Downloaded 11 times

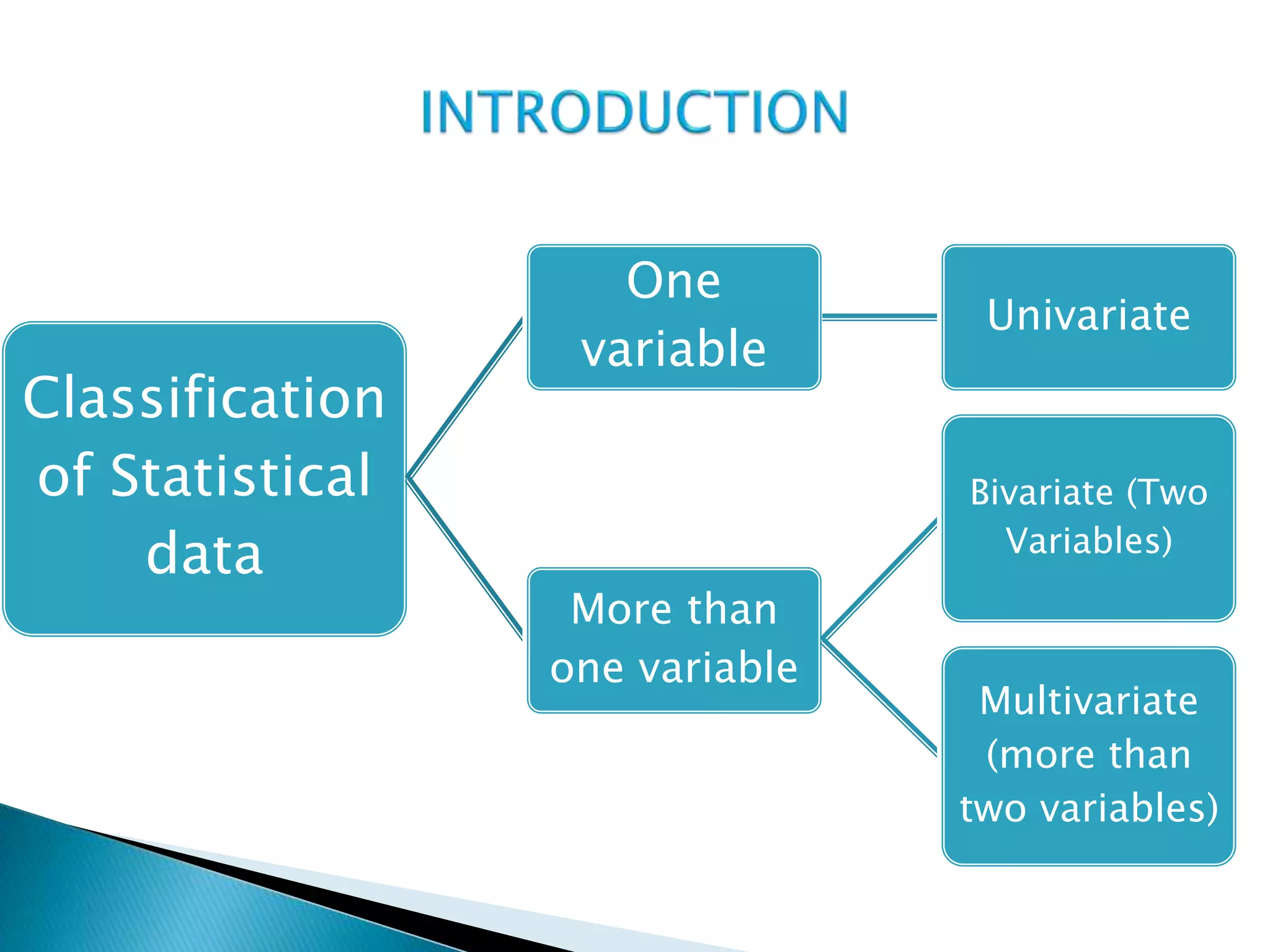







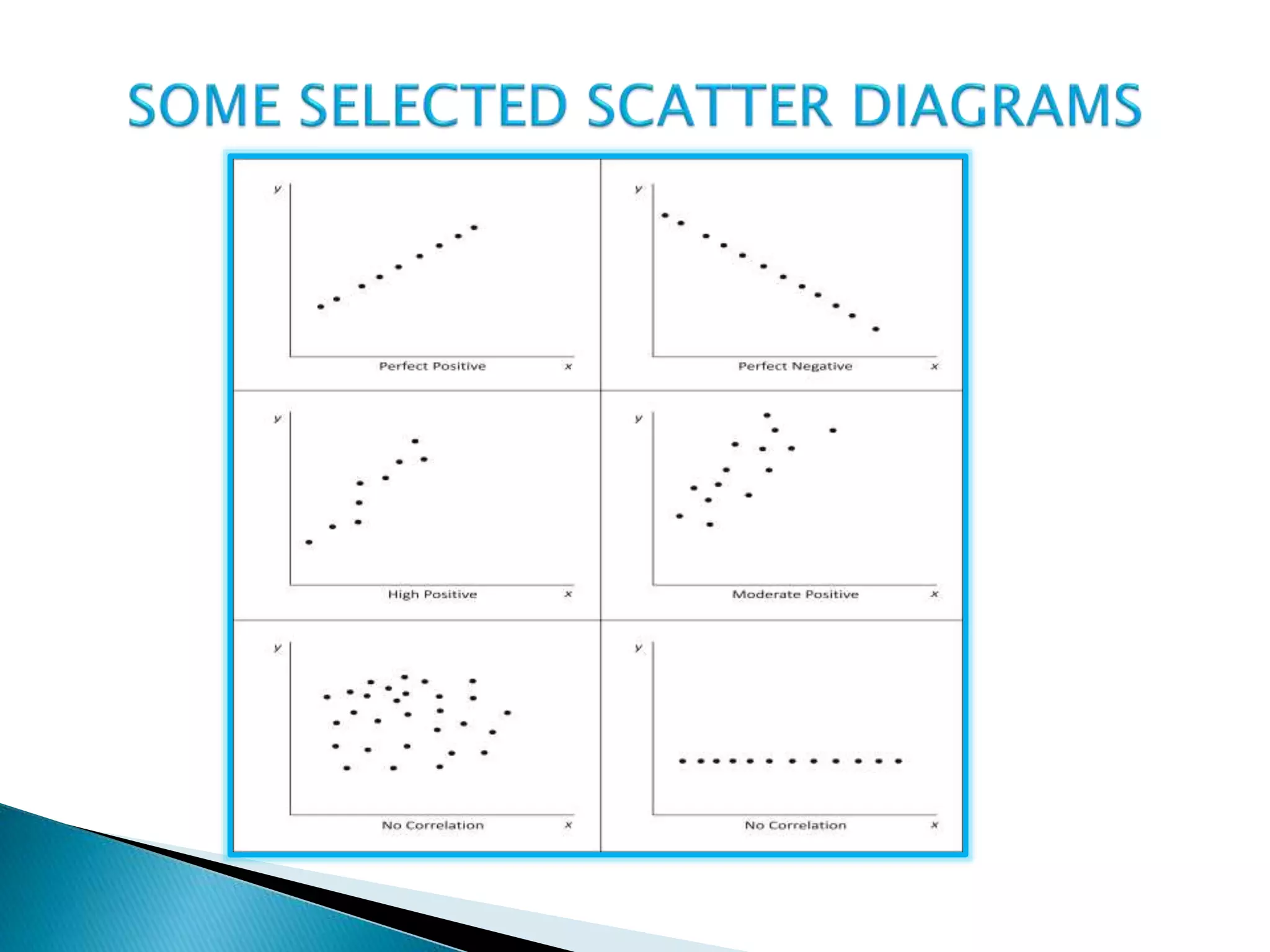

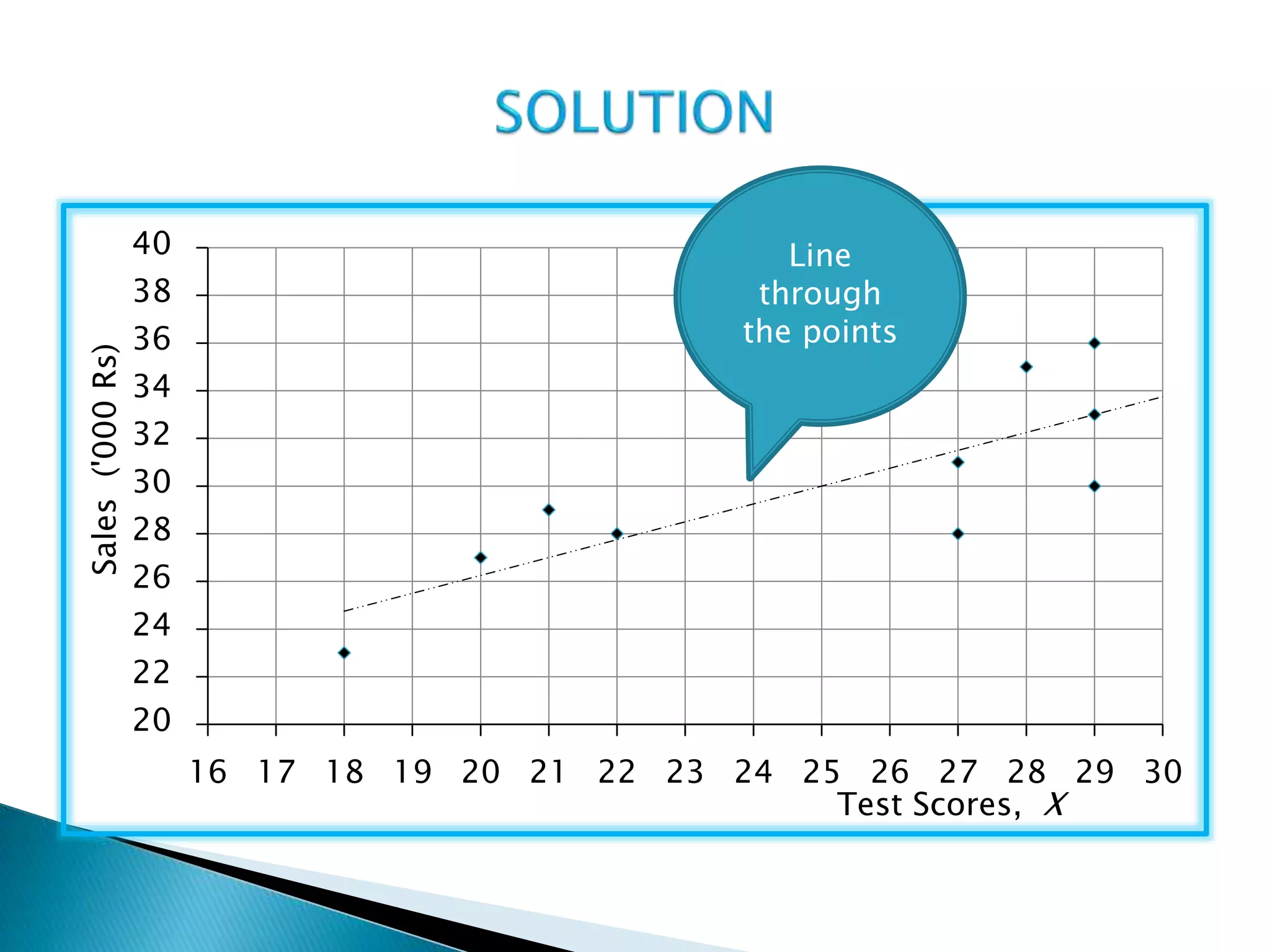






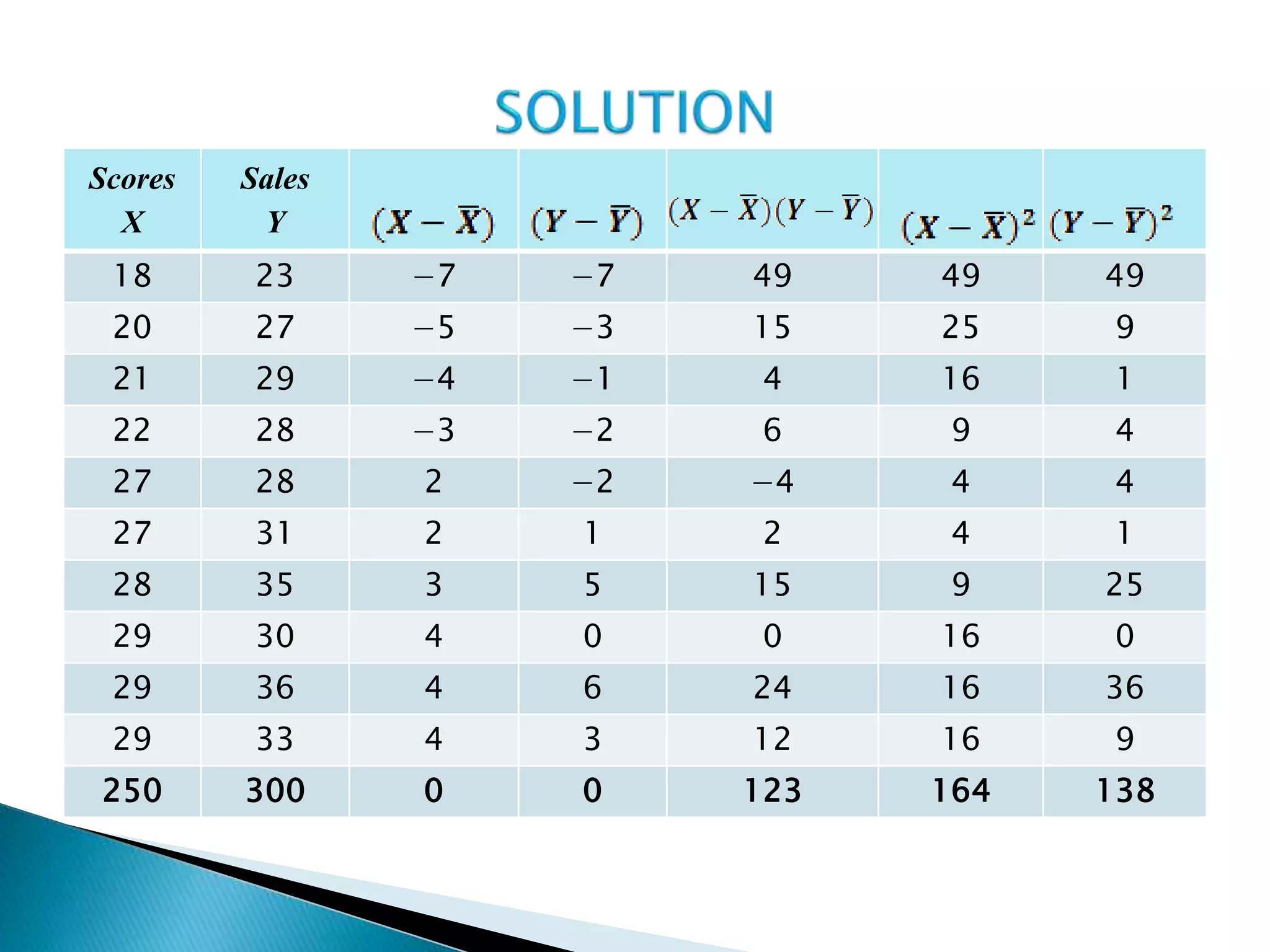


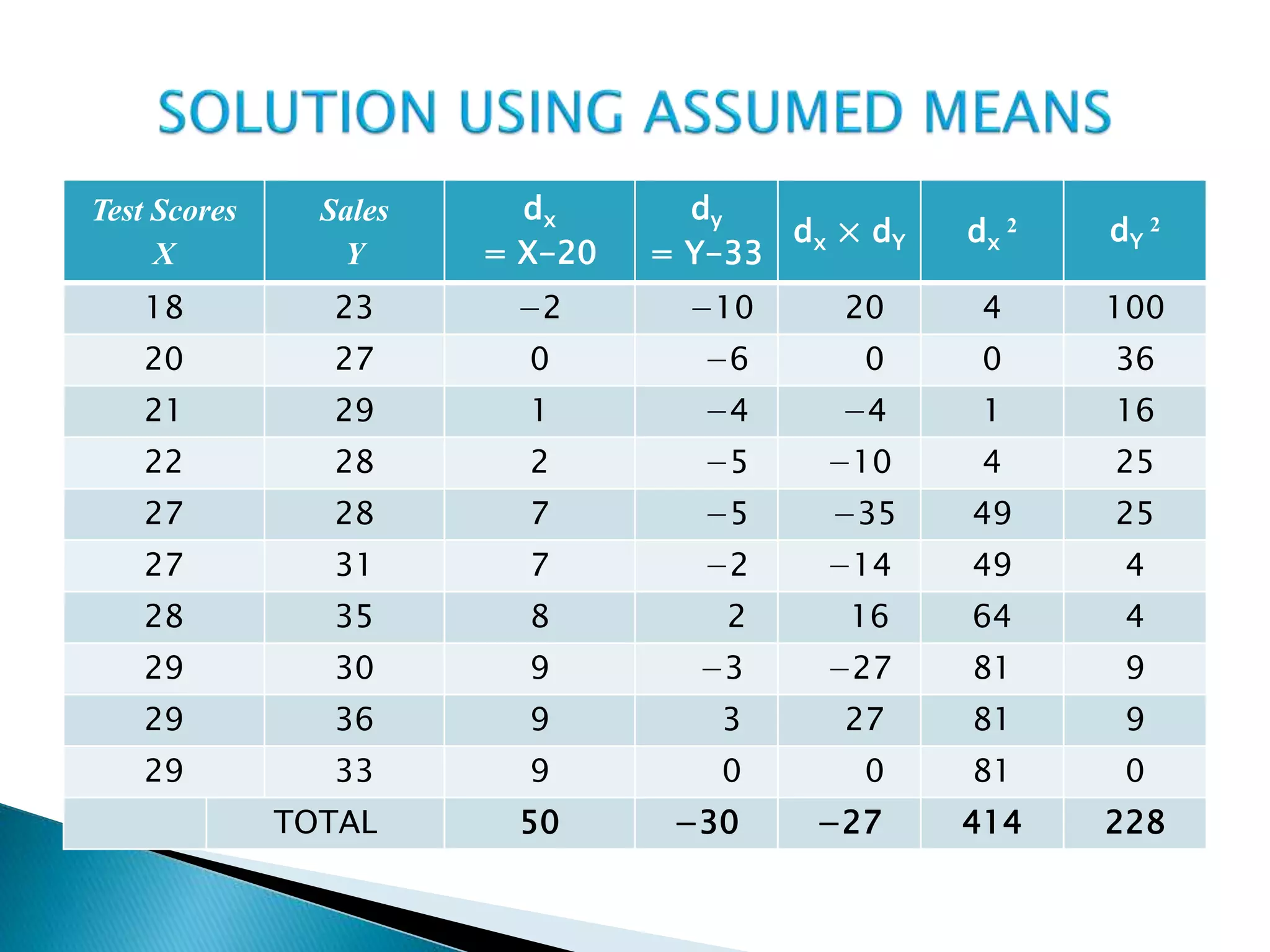


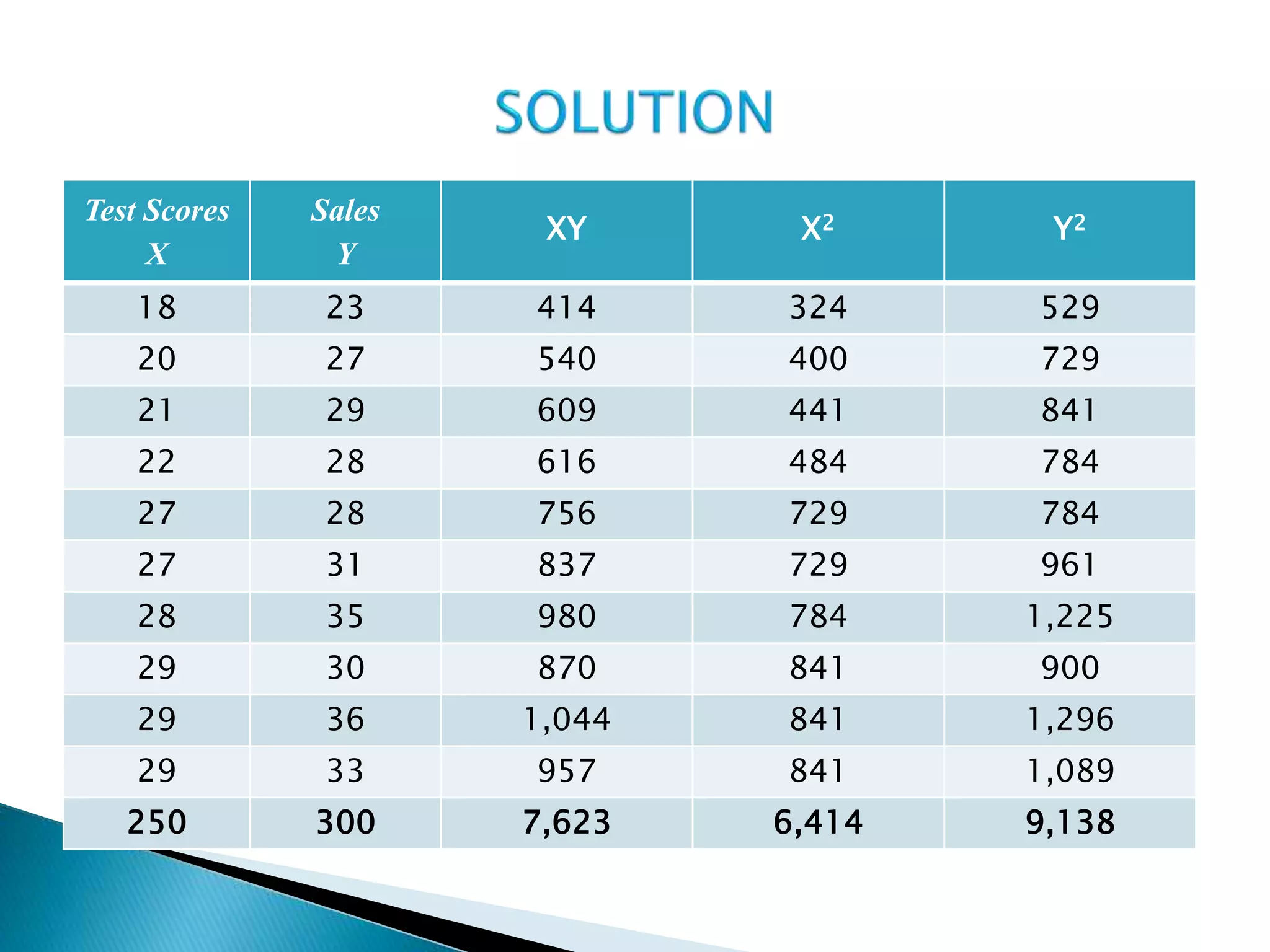



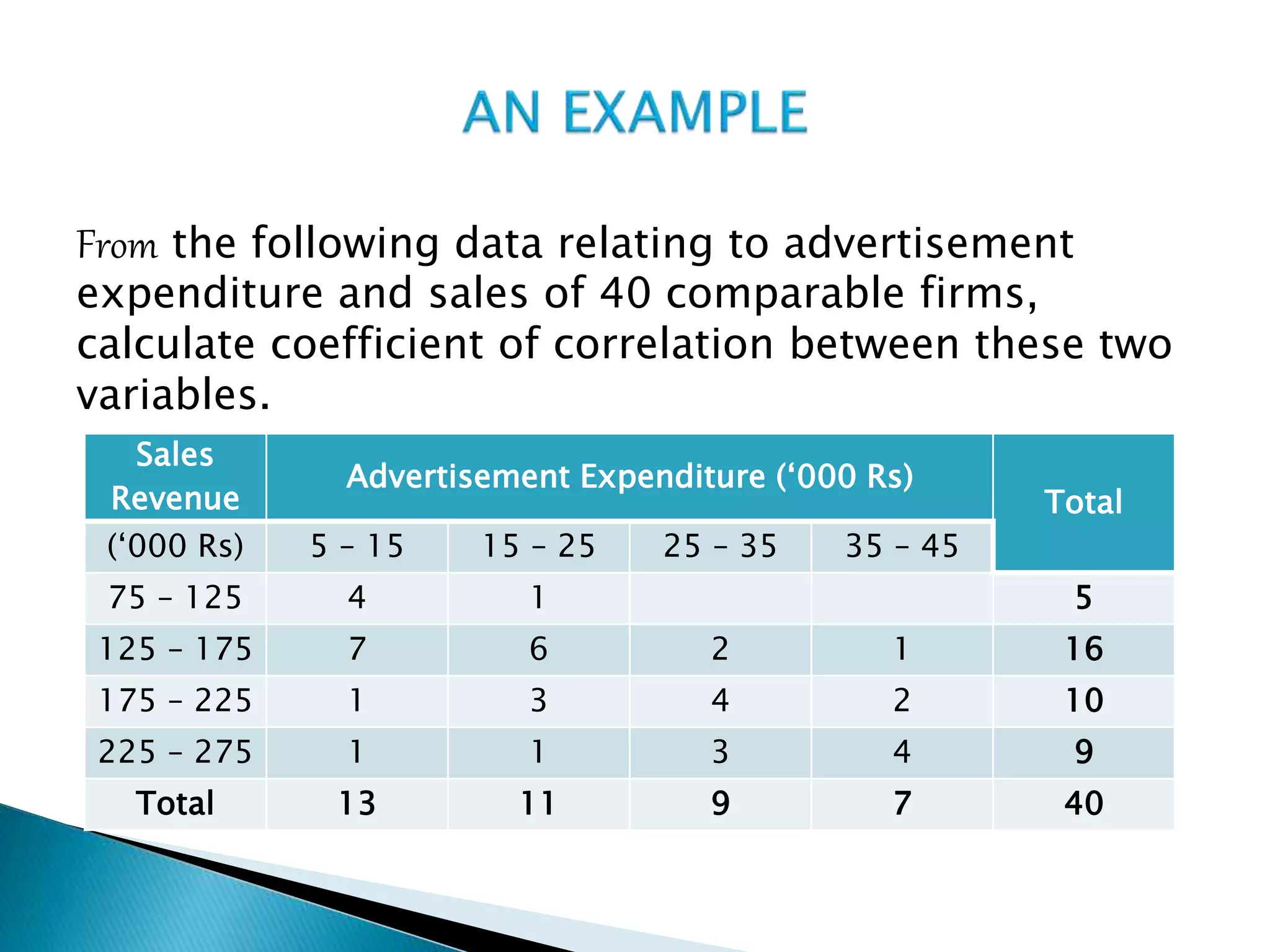
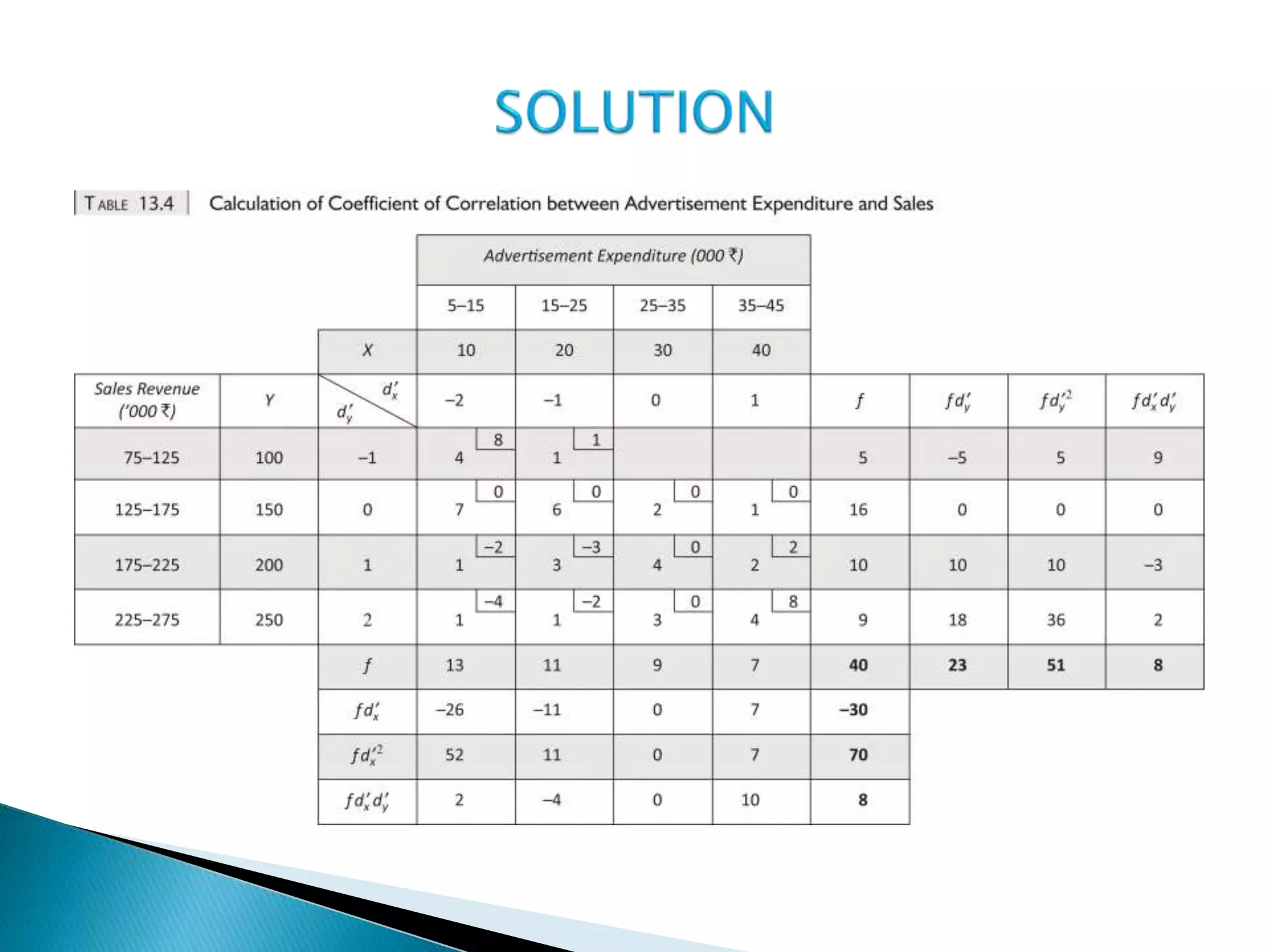












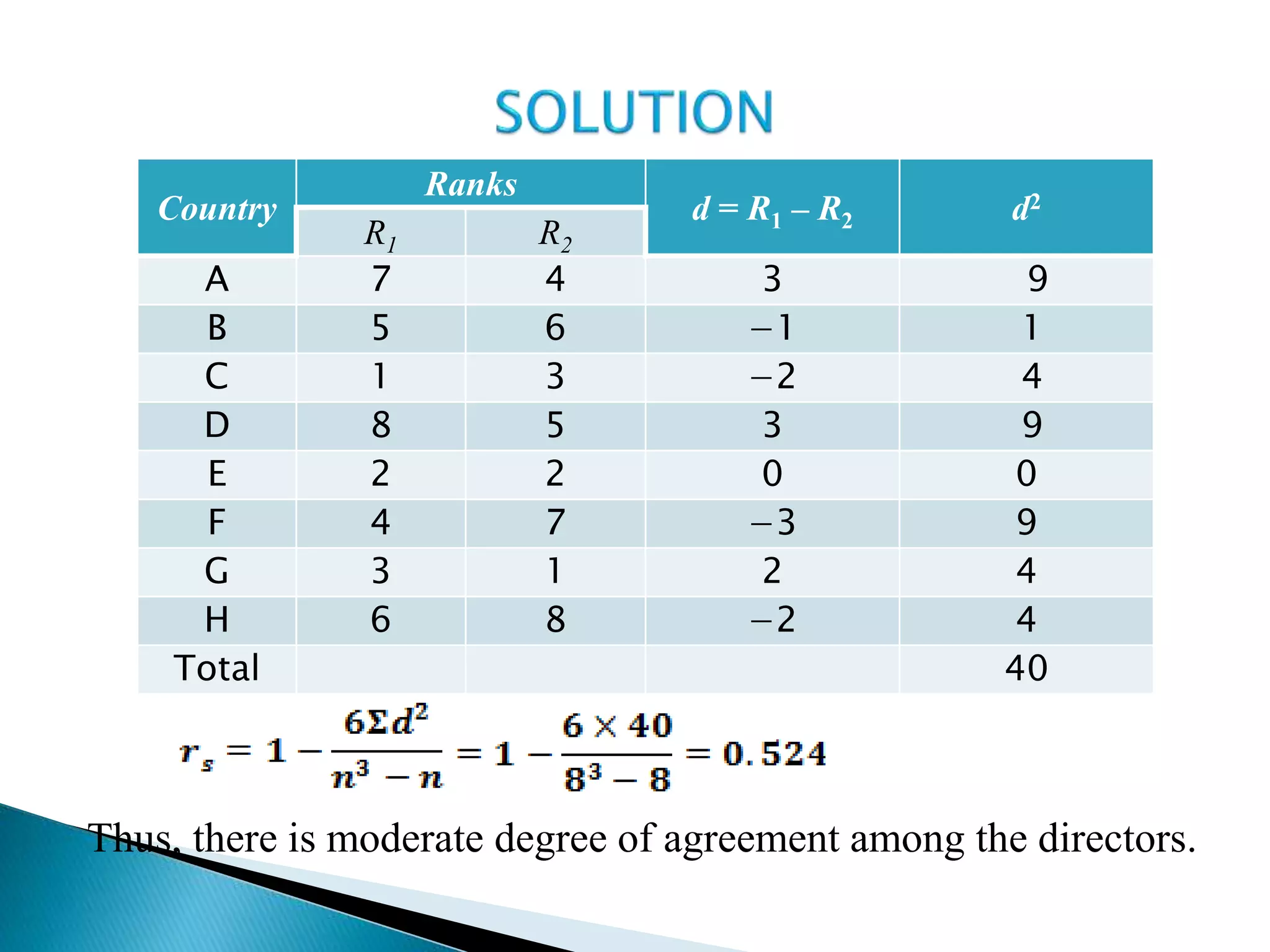


























































This document discusses correlation analysis and provides examples of calculating correlation coefficients. It defines correlation as the degree of co-variation between two or more variables. Three main methods are described for calculating the coefficient of correlation: 1) using deviations from mean values, 2) assuming mean values, and 3) without measuring deviations. An example is provided to demonstrate calculating the coefficient using each method and they all produce the same result. Correlation can be positive, negative, or zero depending on the direction of relationship between the variables.














































































