Downloaded 94 times


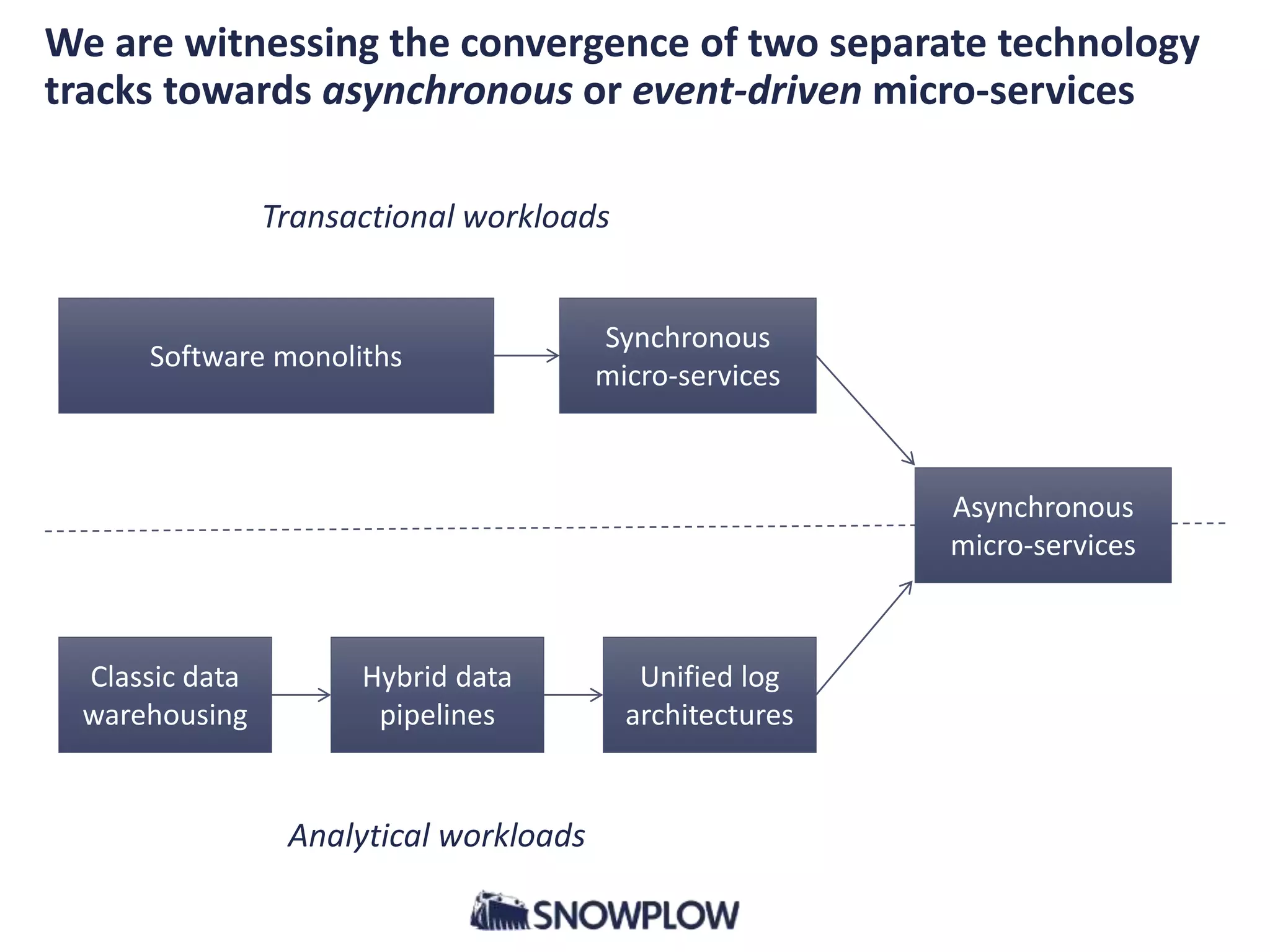

![A quick history lesson: the three eras of business data
processing [1]
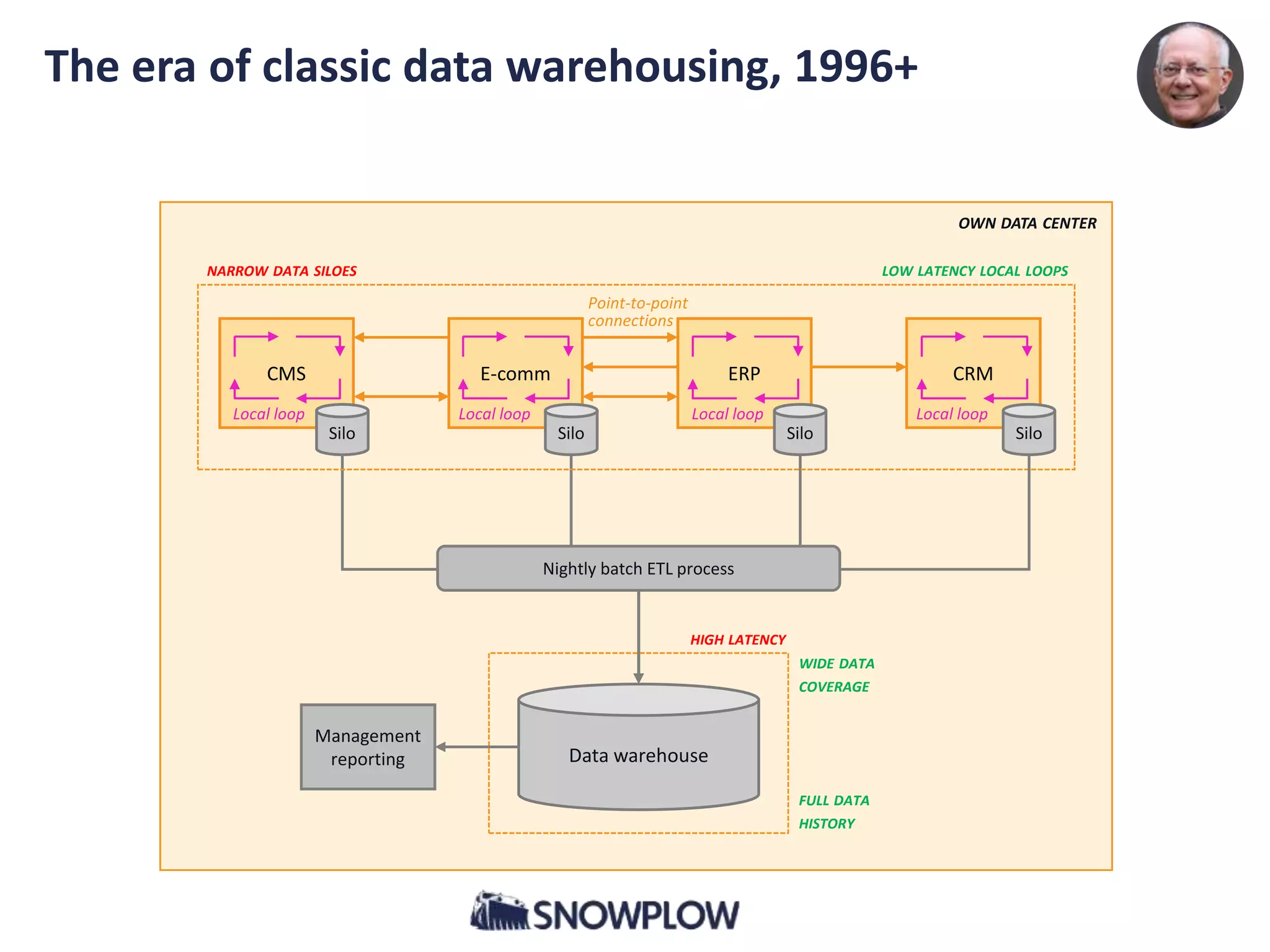
1. Classic data warehousing, 1996+
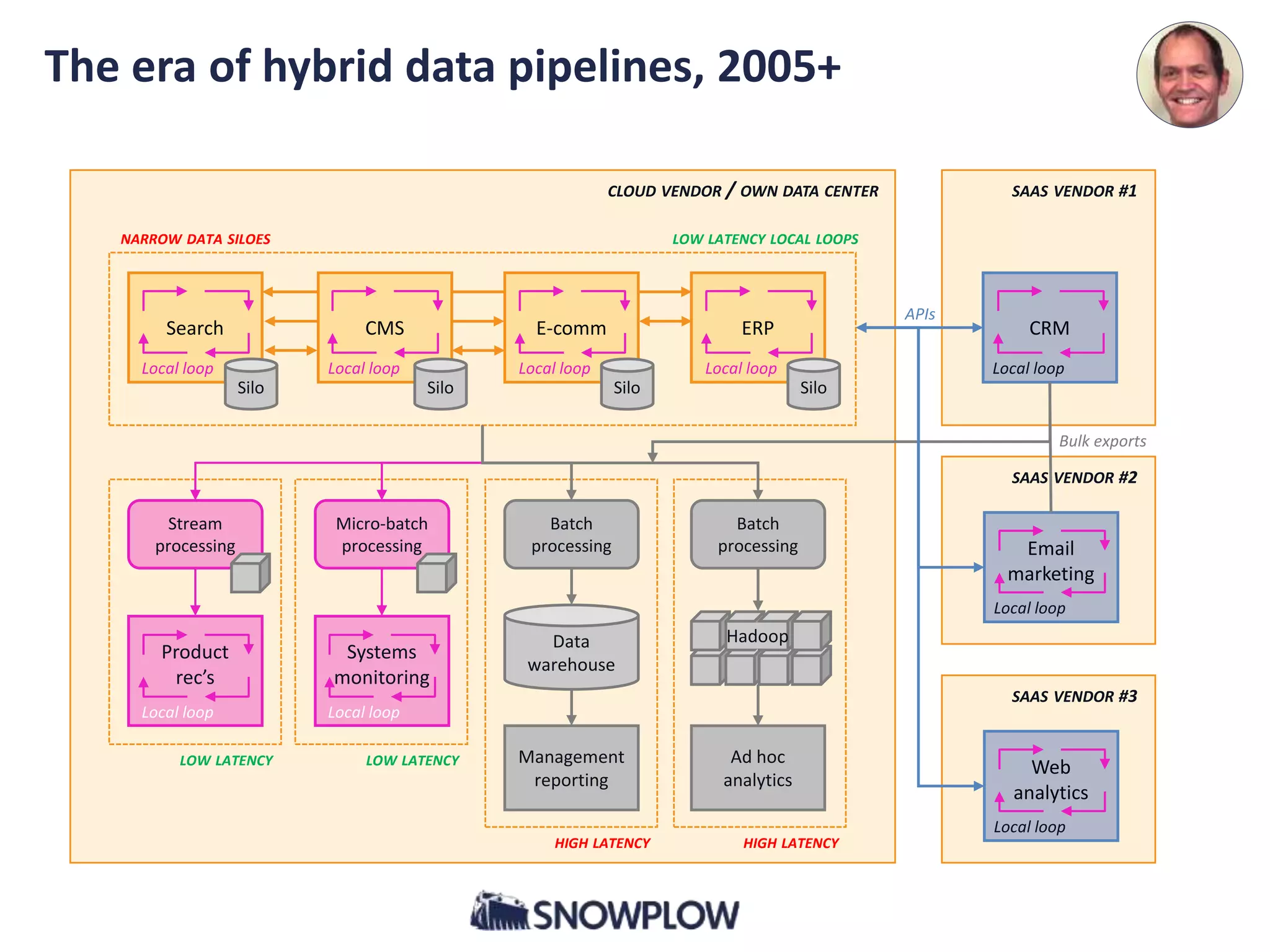
2. Hybrid data pipelines, 2005+
3. Unified log architectures, 2013+
[1] http://snowplowanalytics.com/blog/
2014/01/20/the-three-eras-of-business-data-processing/](https://image.slidesharecdn.com/asynchronousmicro-servicesandtheunifiedlog-161007165224/75/Asynchronous-micro-services-and-the-unified-log-5-2048.jpg)

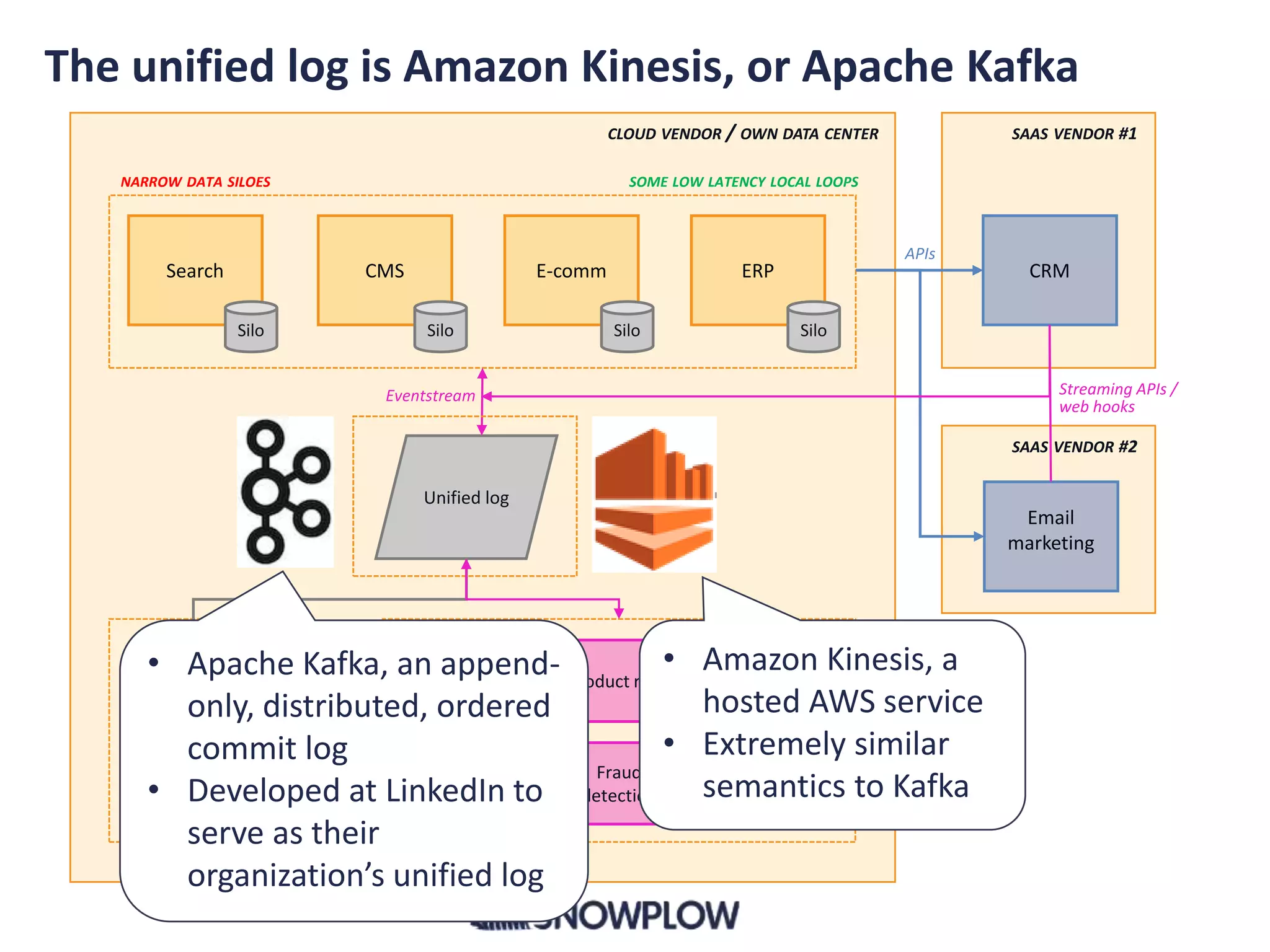
![“Kafka is designed to allow a
single cluster to serve as the
central data backbone for a
large organization” [1]
[1] http://kafka.apache.org/](https://image.slidesharecdn.com/asynchronousmicro-servicesandtheunifiedlog-161007165224/75/Asynchronous-micro-services-and-the-unified-log-14-2048.jpg)



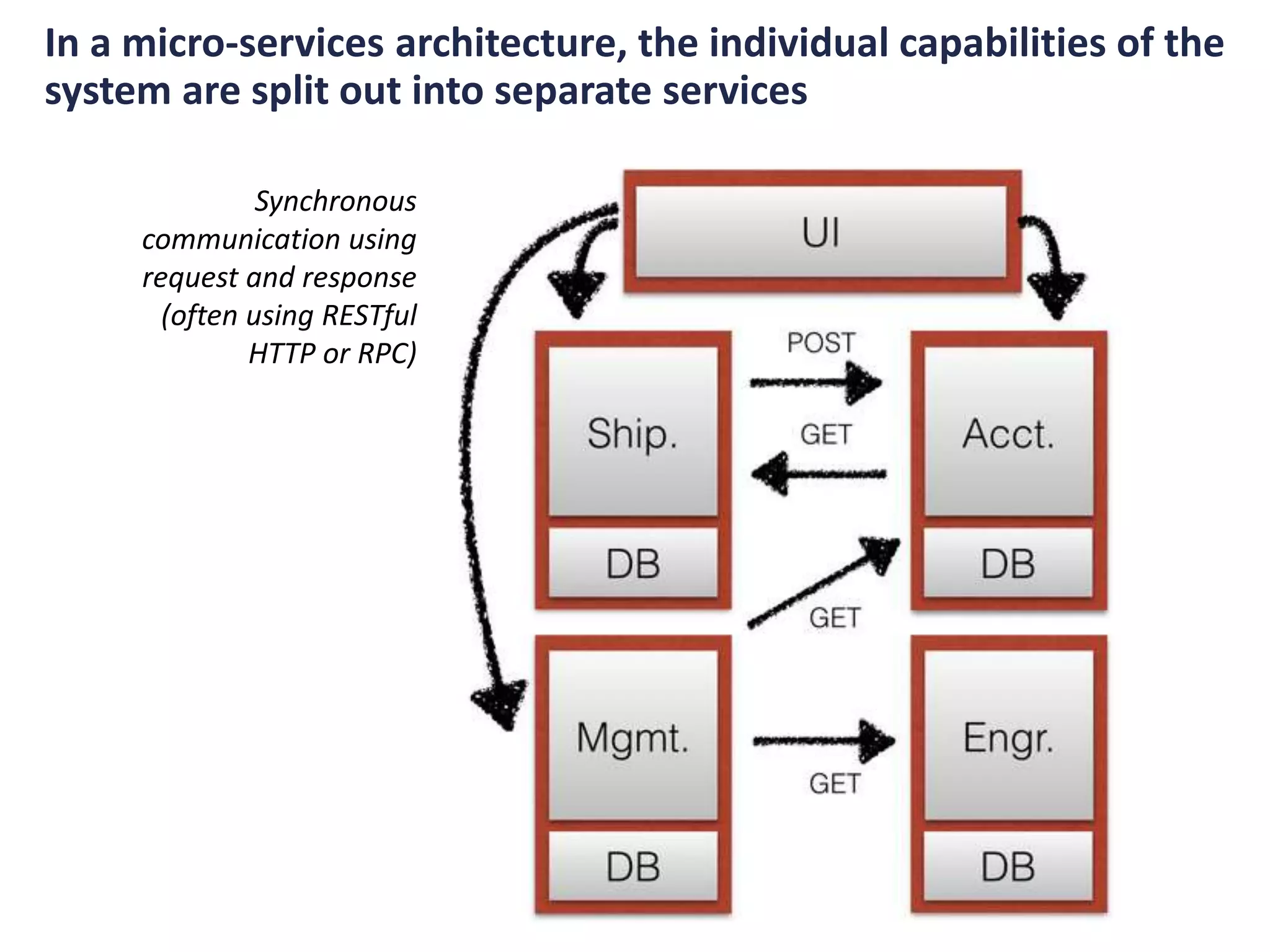





![“…What I mean is that these stream
processing apps were most often
software that implemented core
functions in the business rather than
computing analytics about the
business.” [1]
[1] http://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/
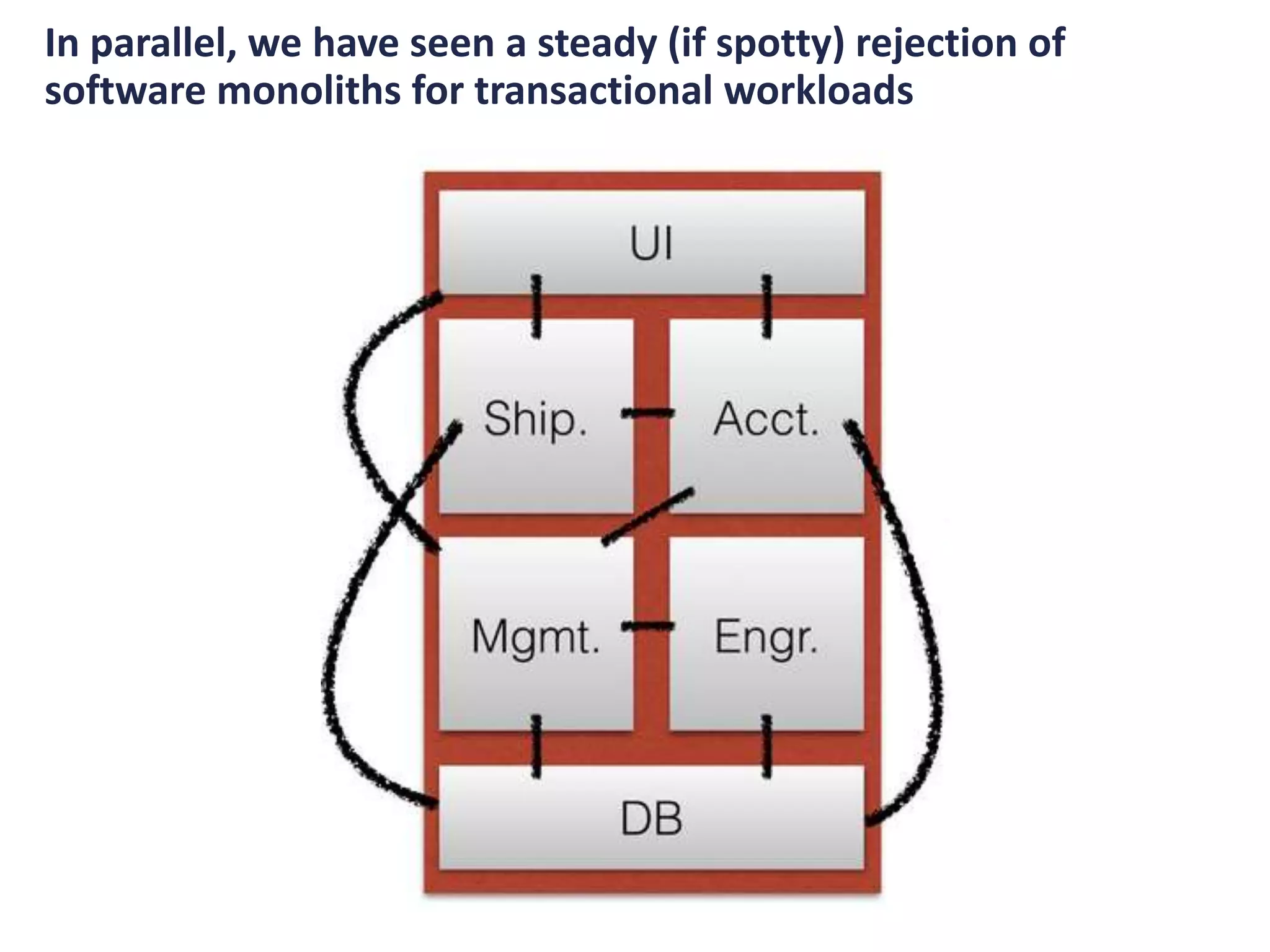
And these micro-services were substituting not just for batch
analytical workloads, but also for transactional workloads](https://image.slidesharecdn.com/asynchronousmicro-servicesandtheunifiedlog-161007165224/75/Asynchronous-micro-services-and-the-unified-log-28-2048.jpg)











![A quick history lesson: the three eras of business data
processing [1]
1. Classic data warehousing, 1996+
2. Hybrid data pipelines, 2005+
3. Unified log architectures, 2013+
[1] http://snowplowanalytics.com/blog/
2014/01/20/the-three-eras-of-business-data-processing/](https://crownmelresort.com/image.slidesharecdn.com/asynchronousmicro-servicesandtheunifiedlog-161007165224/75/Asynchronous-micro-services-and-the-unified-log-5-2048.jpg)








![“Kafka is designed to allow a
single cluster to serve as the
central data backbone for a
large organization” [1]
[1] http://kafka.apache.org/](https://crownmelresort.com/image.slidesharecdn.com/asynchronousmicro-servicesandtheunifiedlog-161007165224/75/Asynchronous-micro-services-and-the-unified-log-14-2048.jpg)













![“…What I mean is that these stream
processing apps were most often
software that implemented core
functions in the business rather than
computing analytics about the
business.” [1]
[1] http://www.confluent.io/blog/introducing-kafka-streams-stream-processing-made-simple/
And these micro-services were substituting not just for batch
analytical workloads, but also for transactional workloads](https://crownmelresort.com/image.slidesharecdn.com/asynchronousmicro-servicesandtheunifiedlog-161007165224/75/Asynchronous-micro-services-and-the-unified-log-28-2048.jpg)













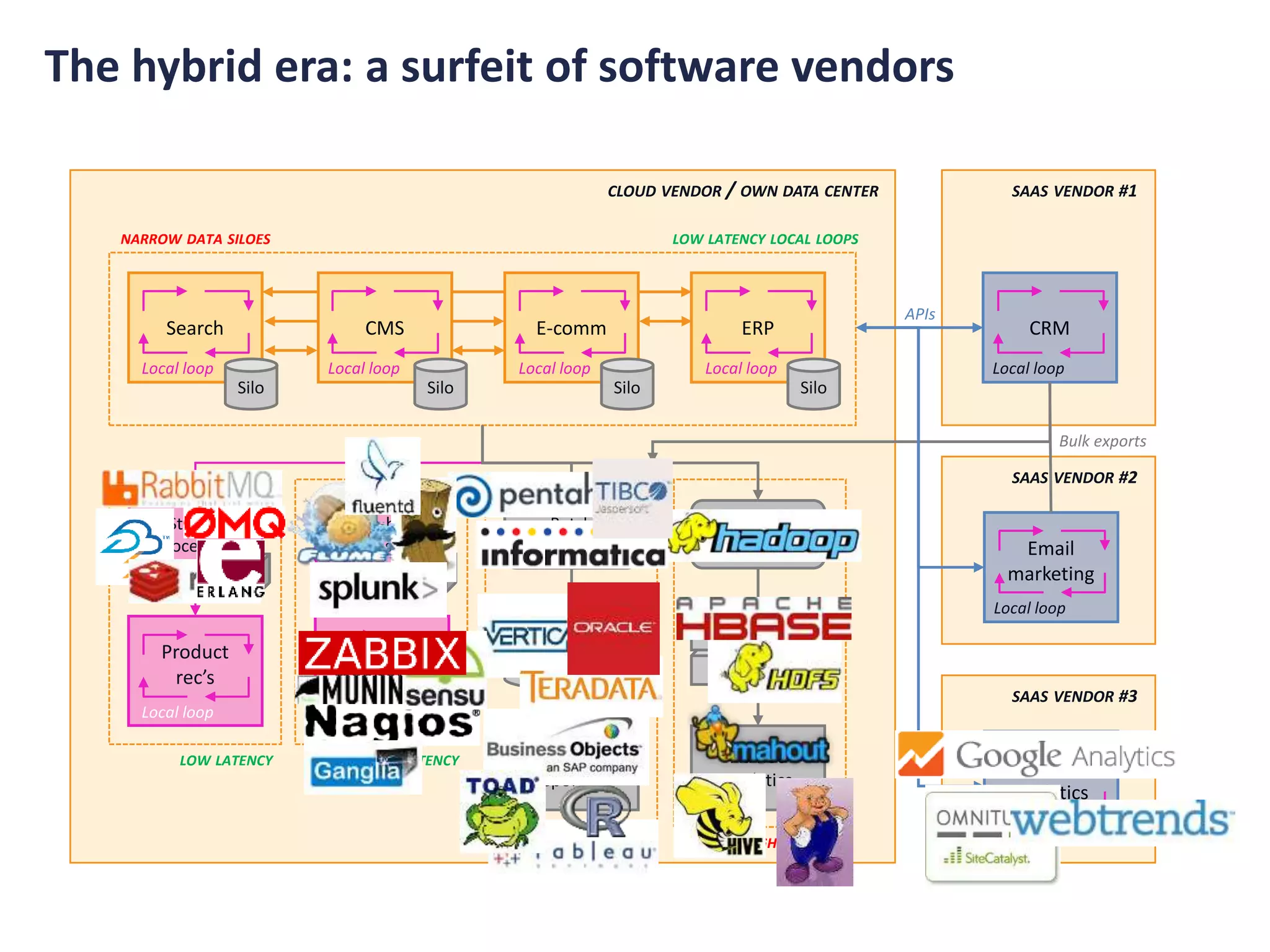
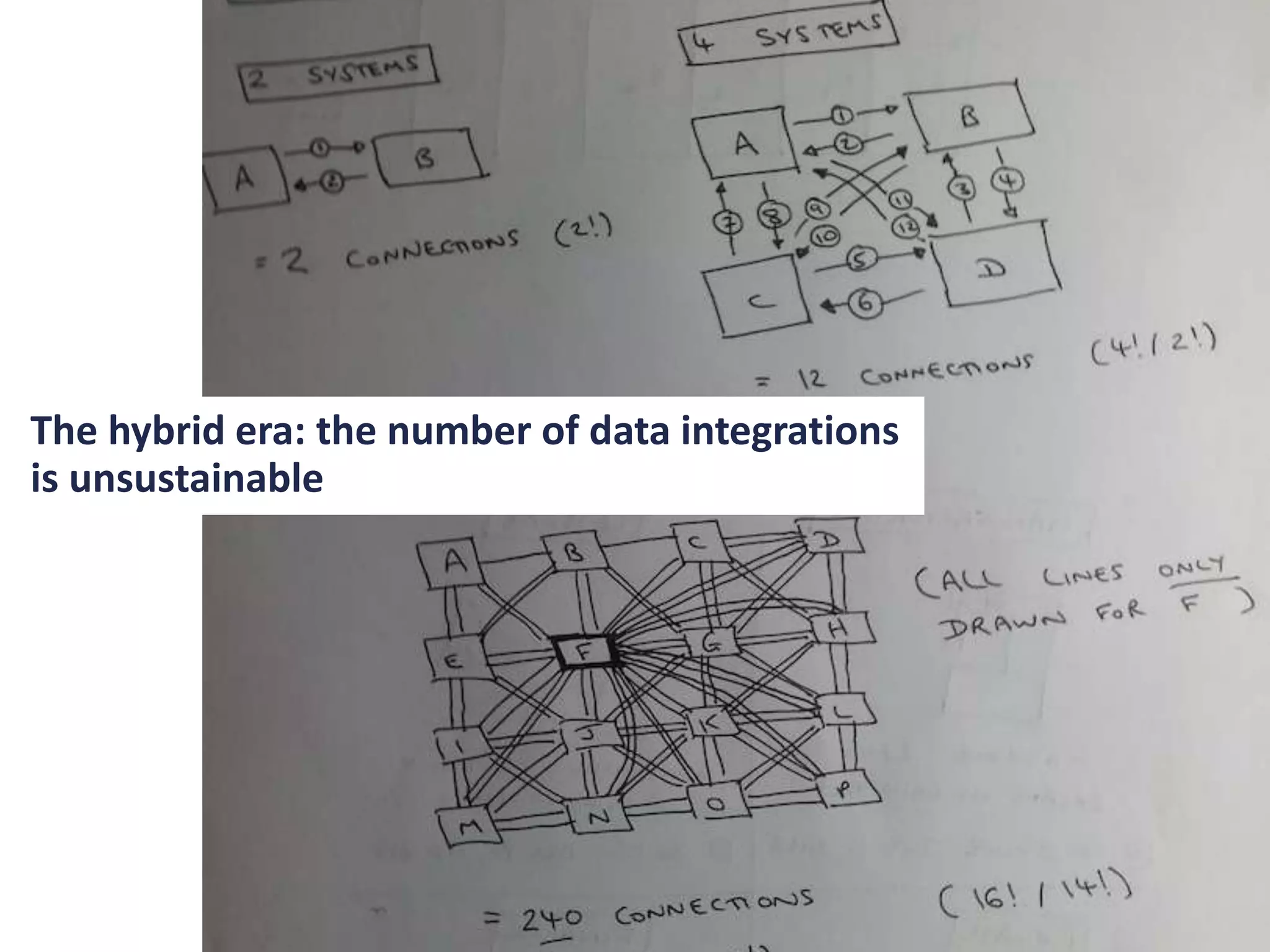
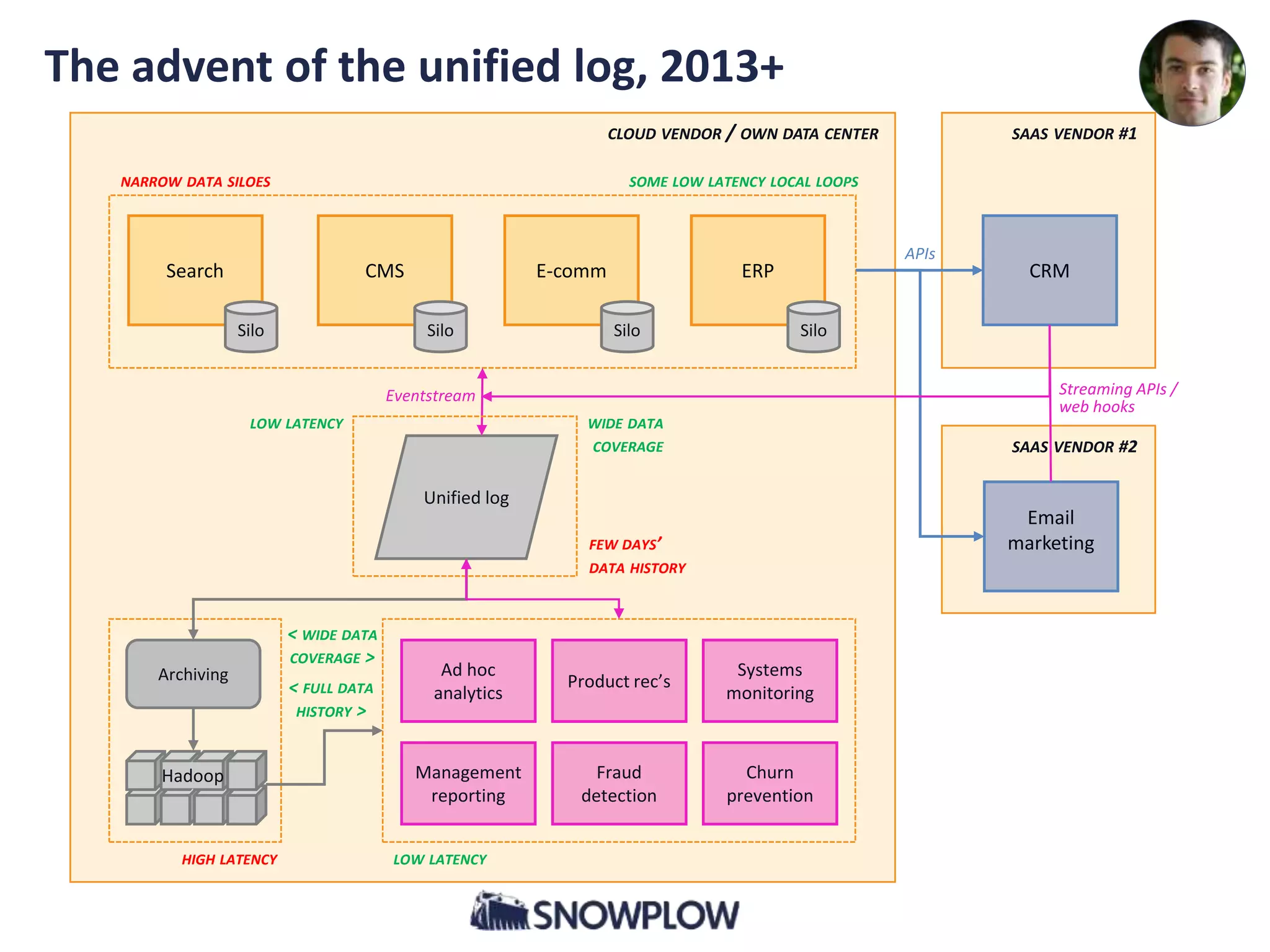
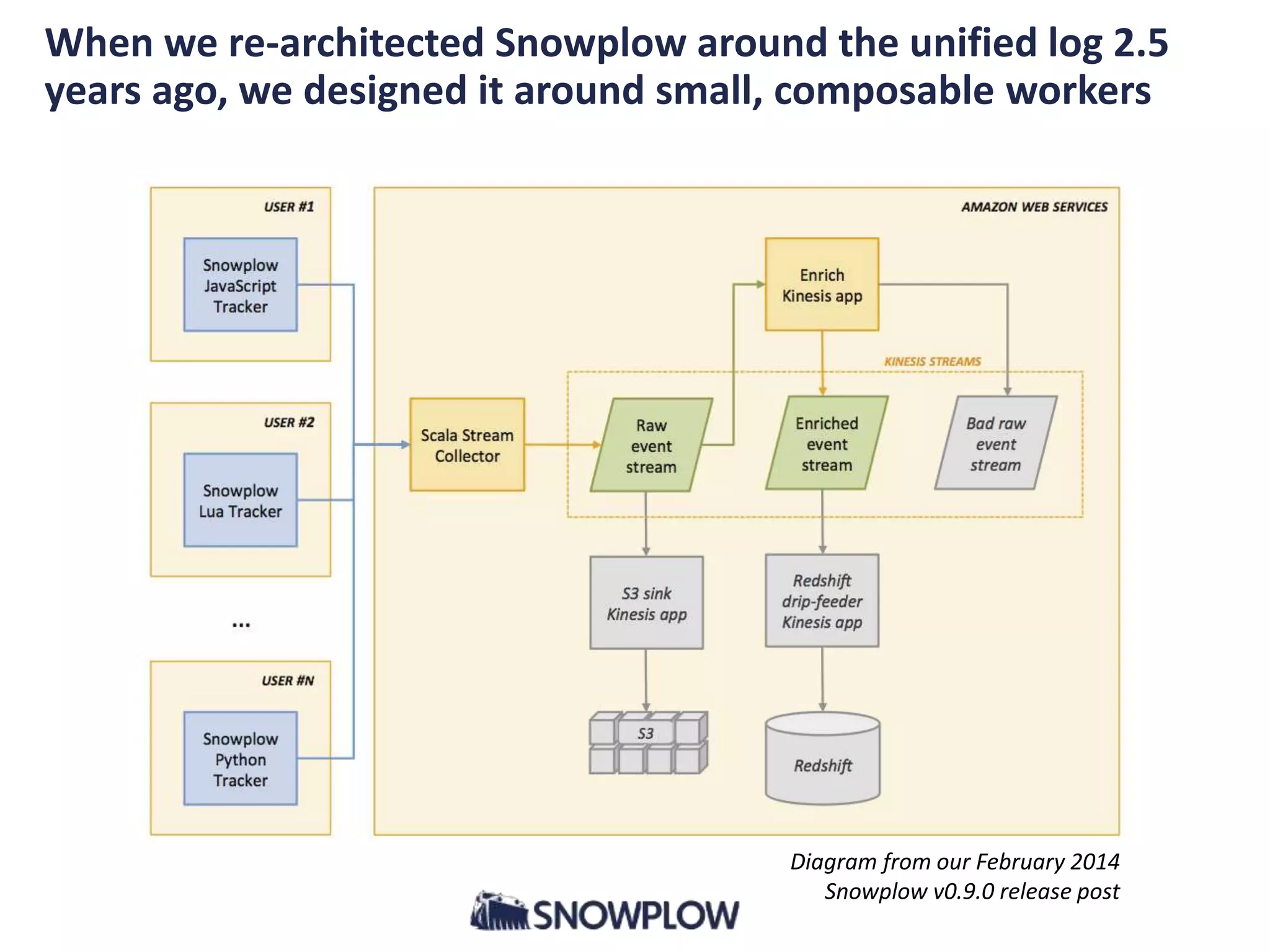
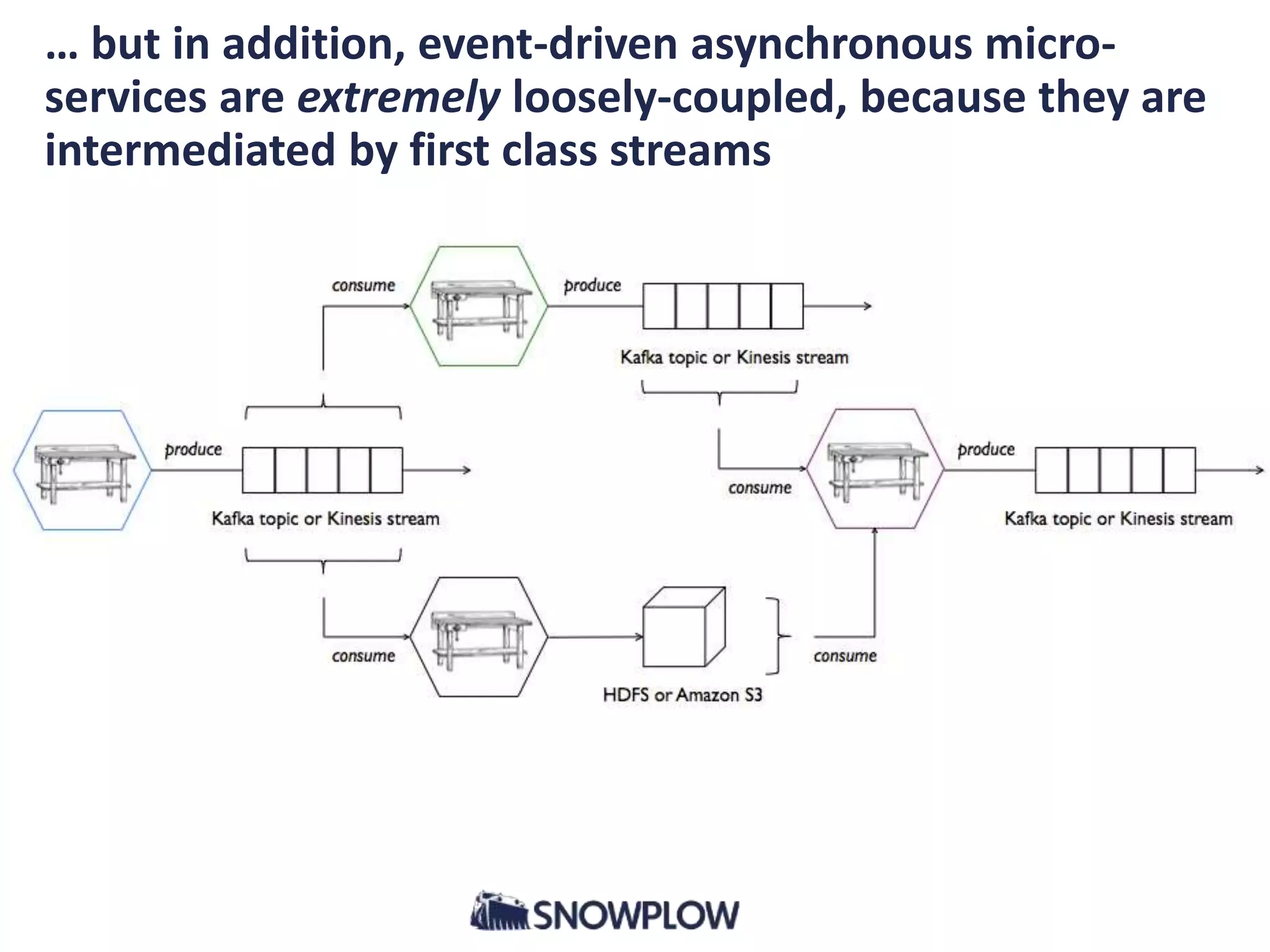
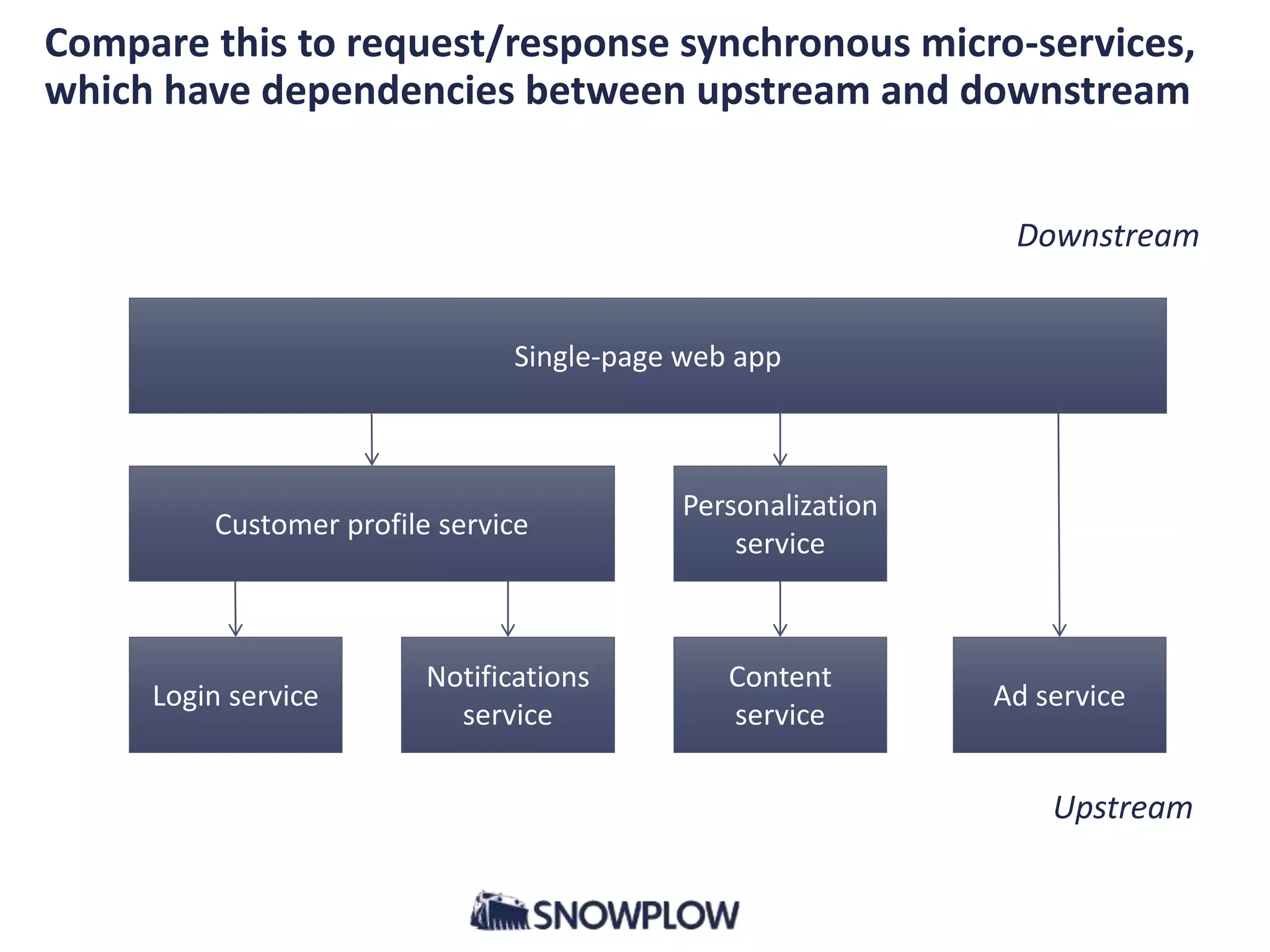
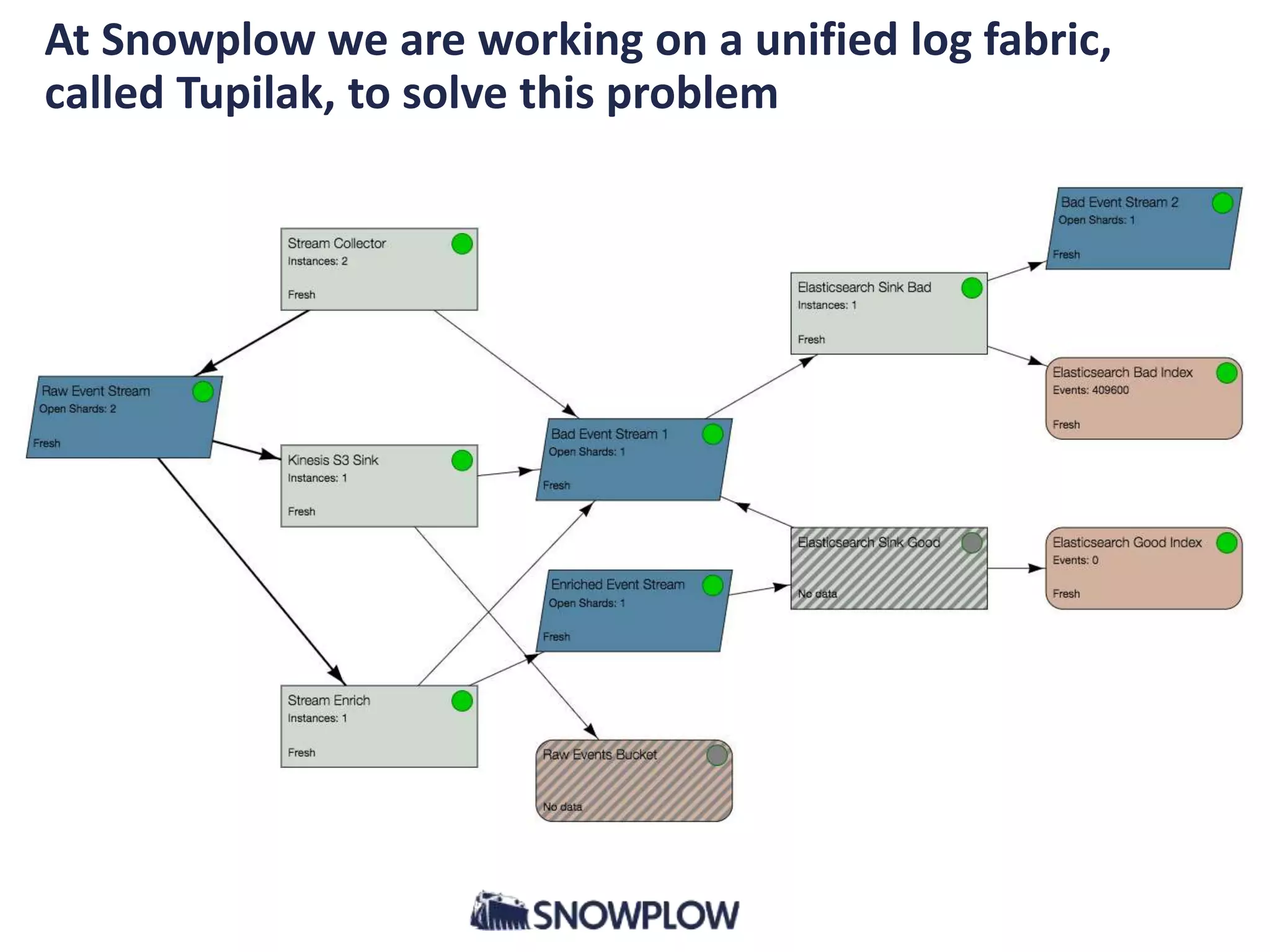
- The document discusses the convergence of asynchronous micro-services and unified log architectures. Asynchronous micro-services are replacing traditional synchronous micro-services and analytical workflows are moving to unified log architectures. - A unified log, like Apache Kafka, provides a single version of truth and unravels the "hairball" of separate data integrations. It allows for wider data coverage, full data history, and low latency queries. - Asynchronous micro-services are loosely coupled through event streams, which provides advantages over synchronous request/response services like easier upgrades and reduced failures. There will be more tools for building asynchronous services and open source schema registries will be important.