Downloaded 150 times



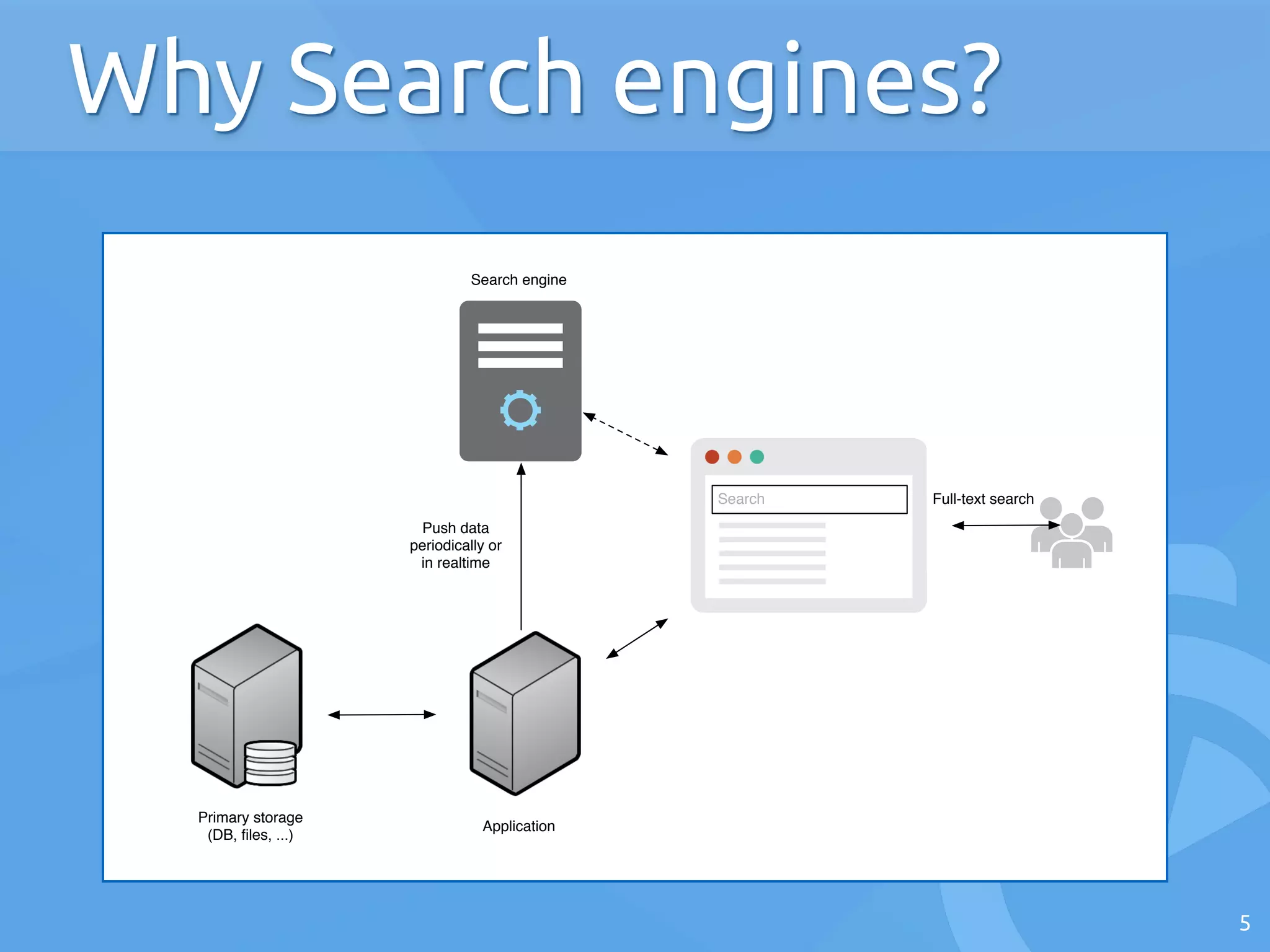



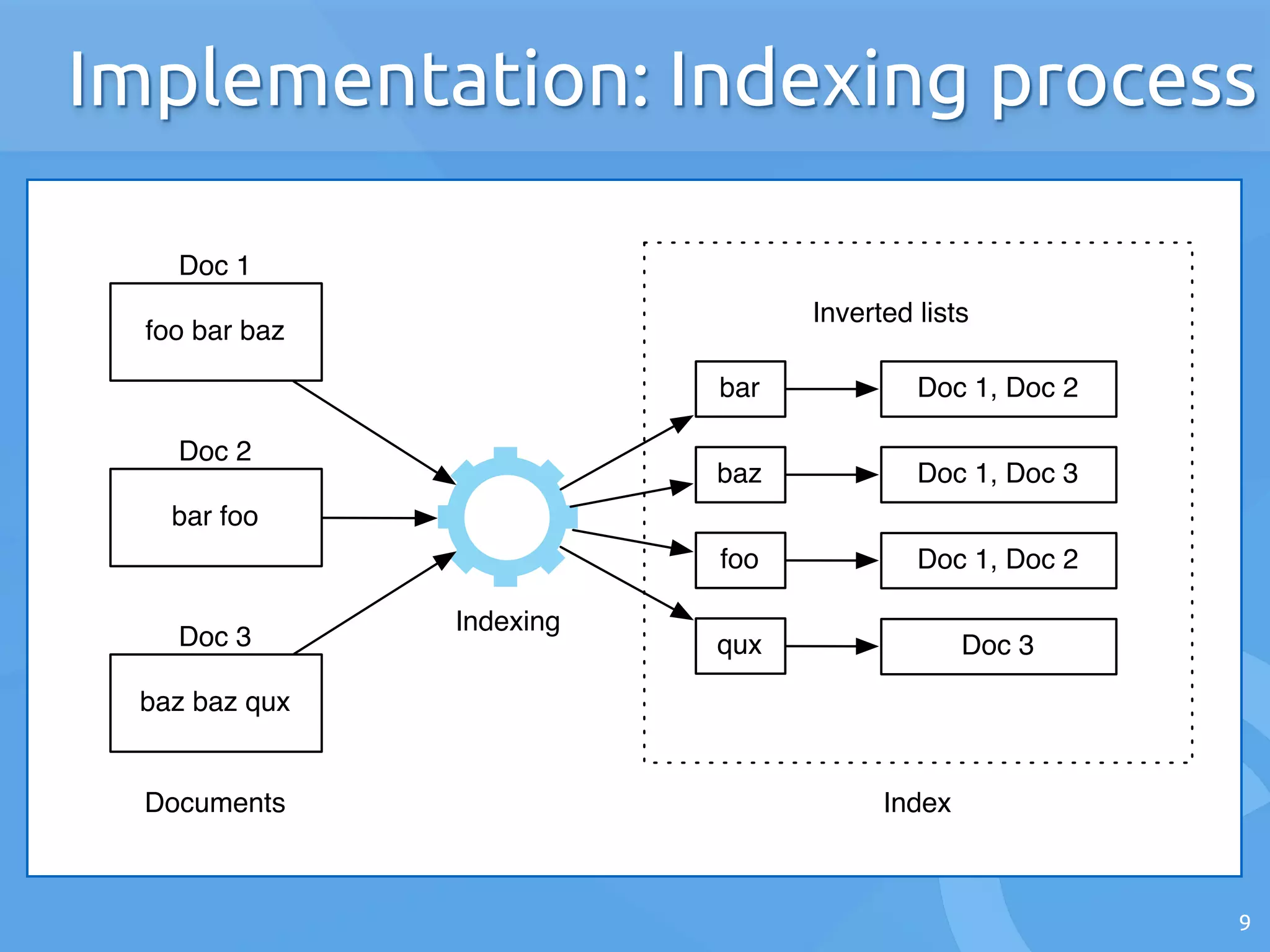

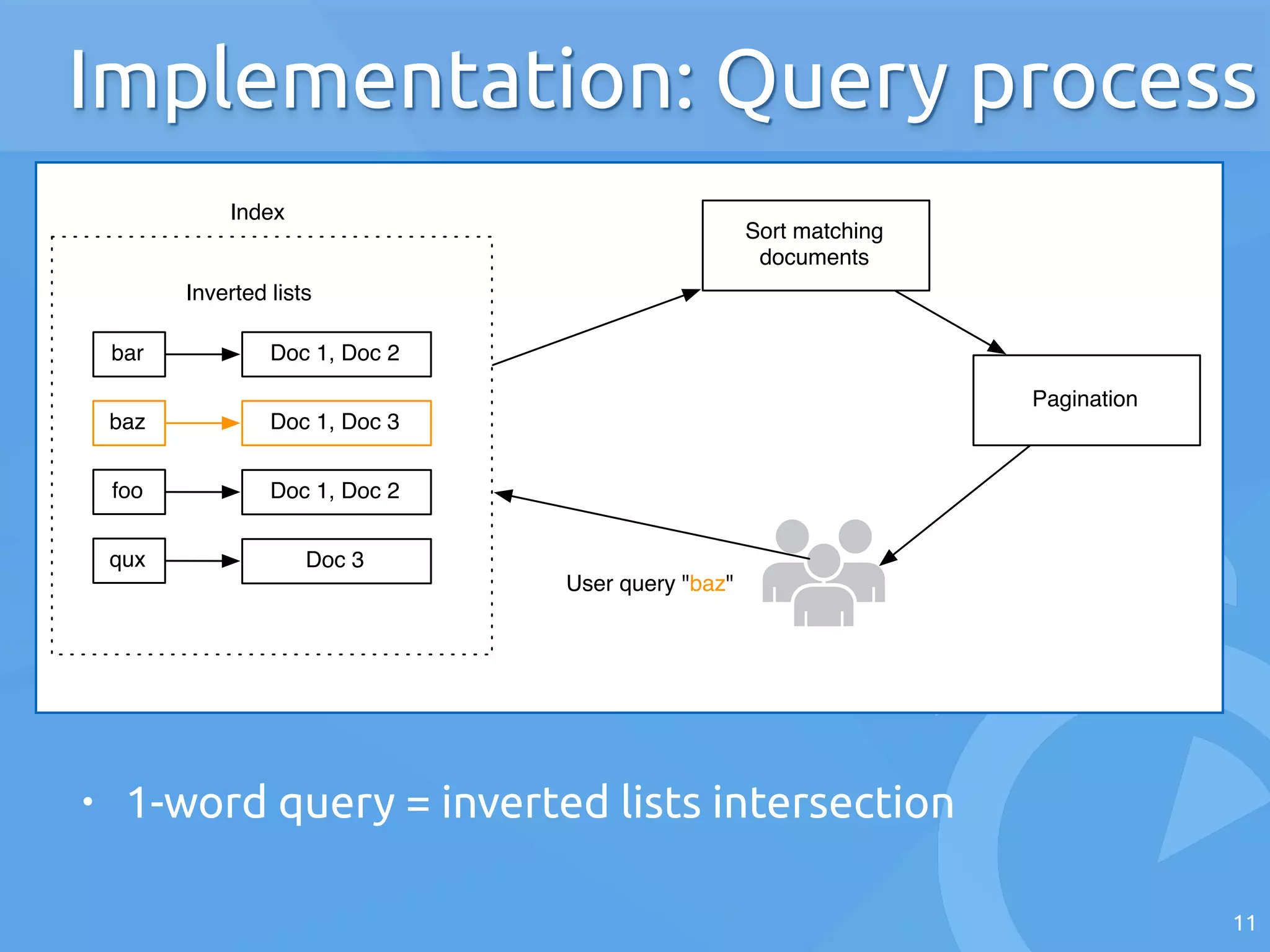
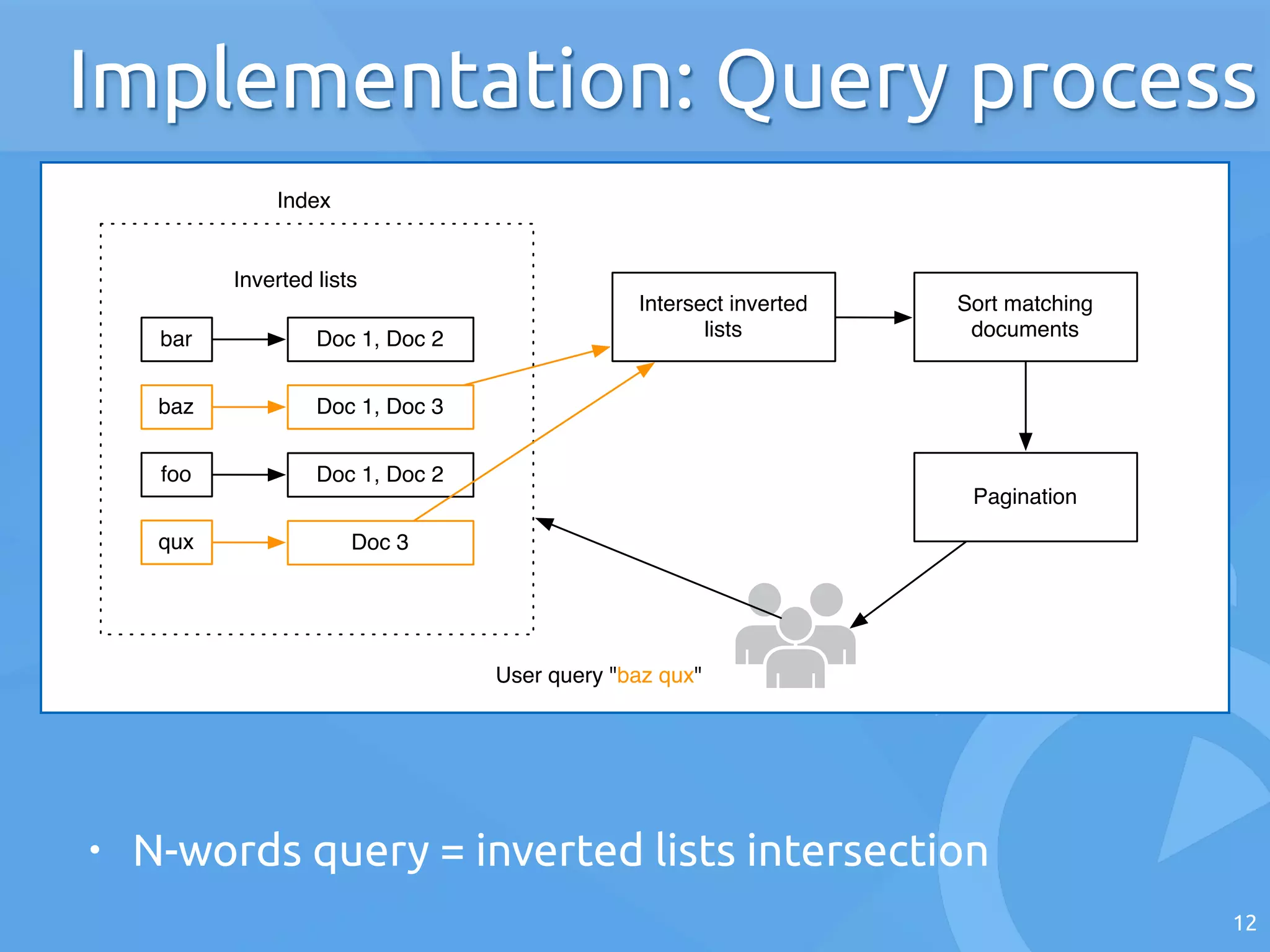

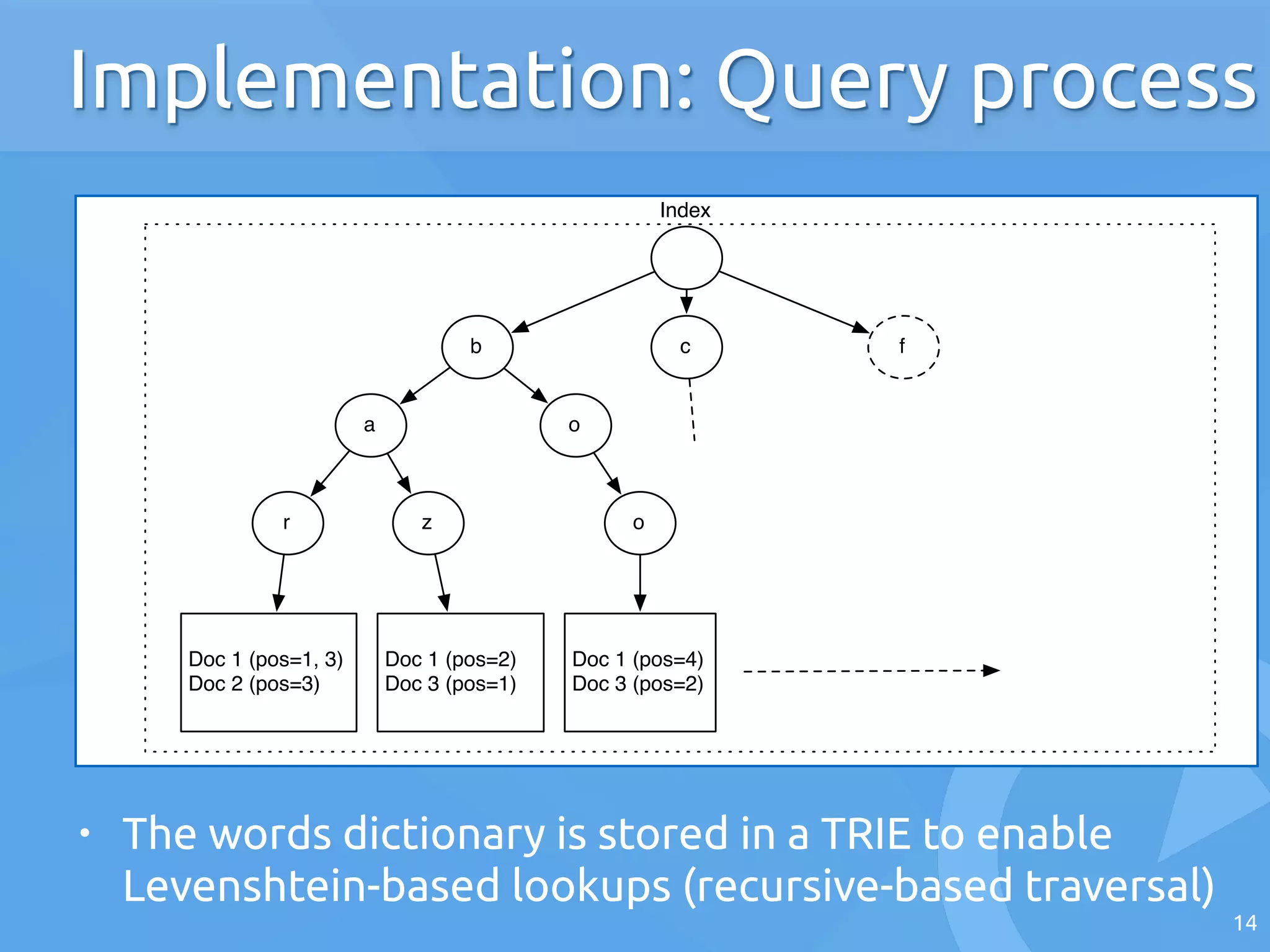
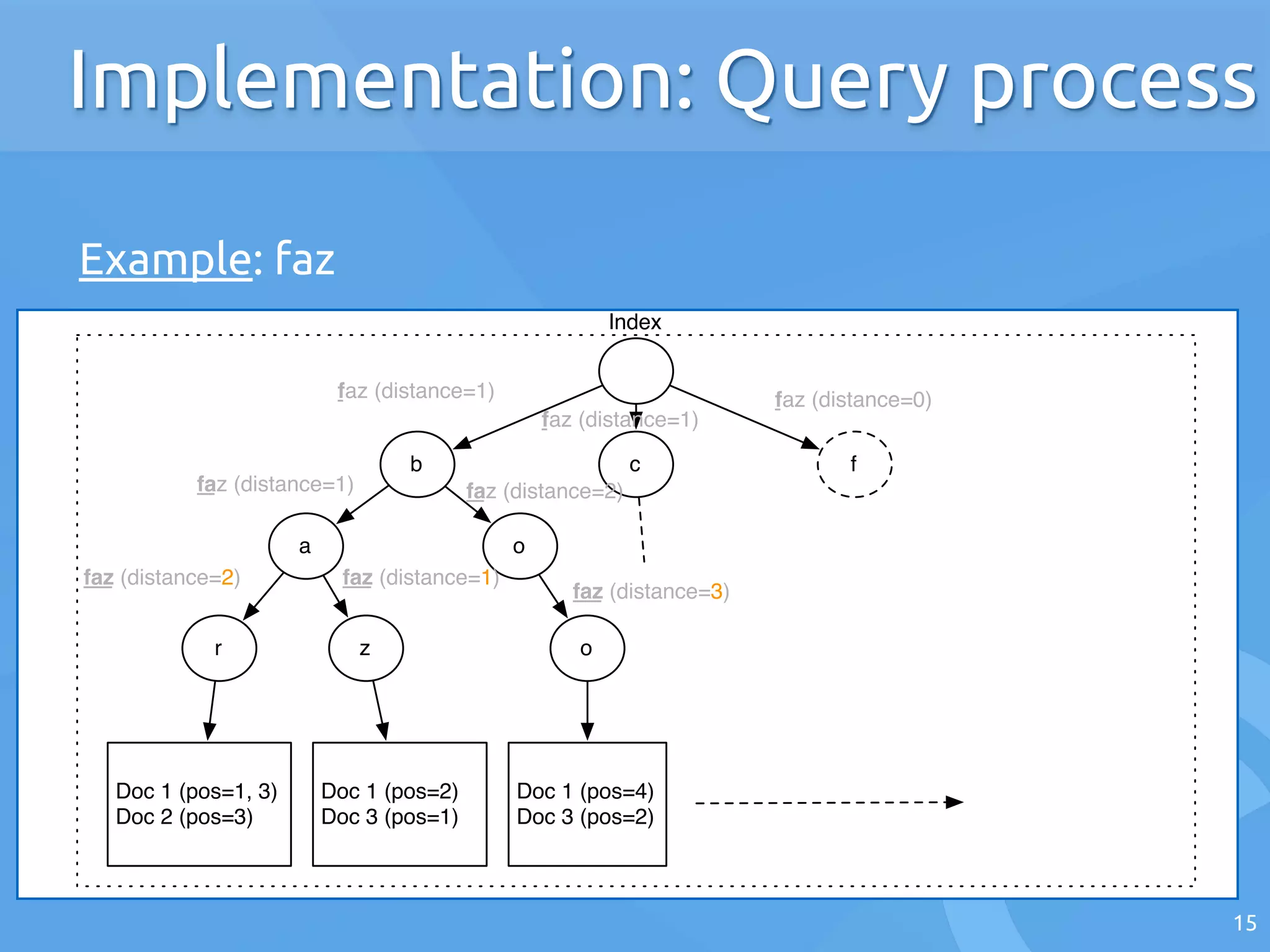
























The document discusses the architecture of search engines, emphasizing the importance of speed, relevance, and fuzzy matching for handling text queries. It explains the processes of indexing and querying, including the use of inverted lists and edit-distance algorithms for managing typographical errors. The talk also touches on advanced topics like numerical queries and scalability solutions.























































































