Download to read offline





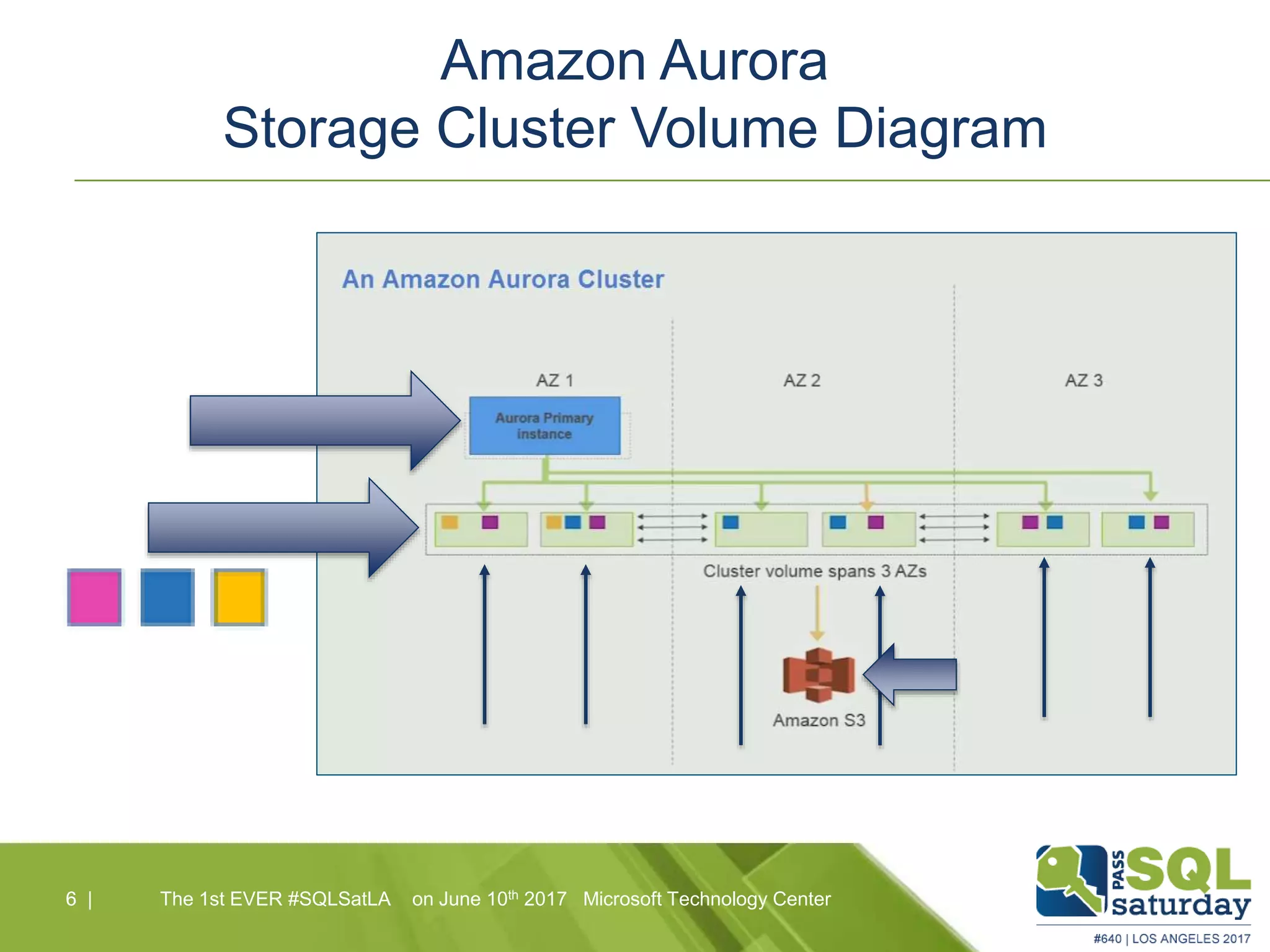

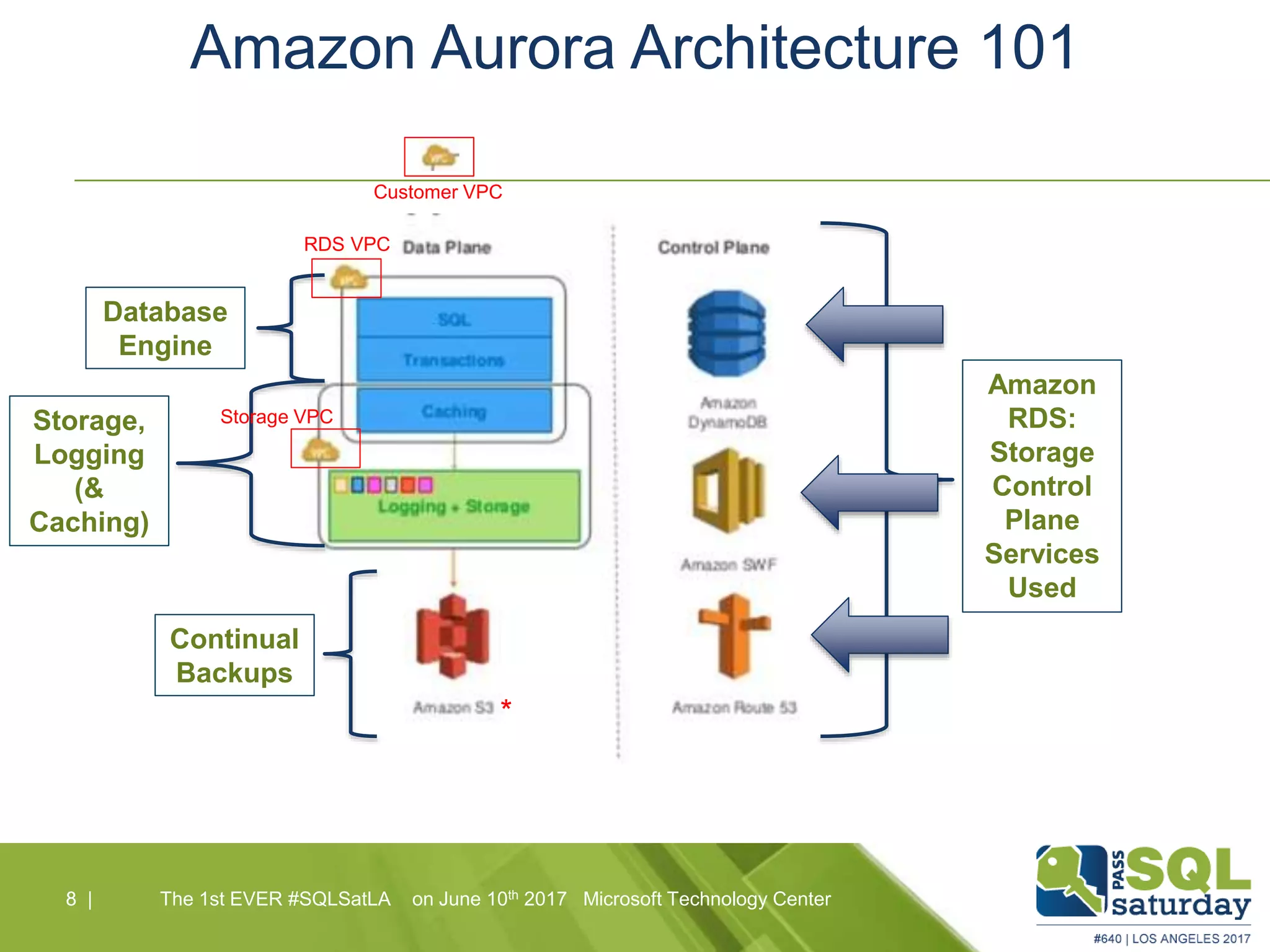

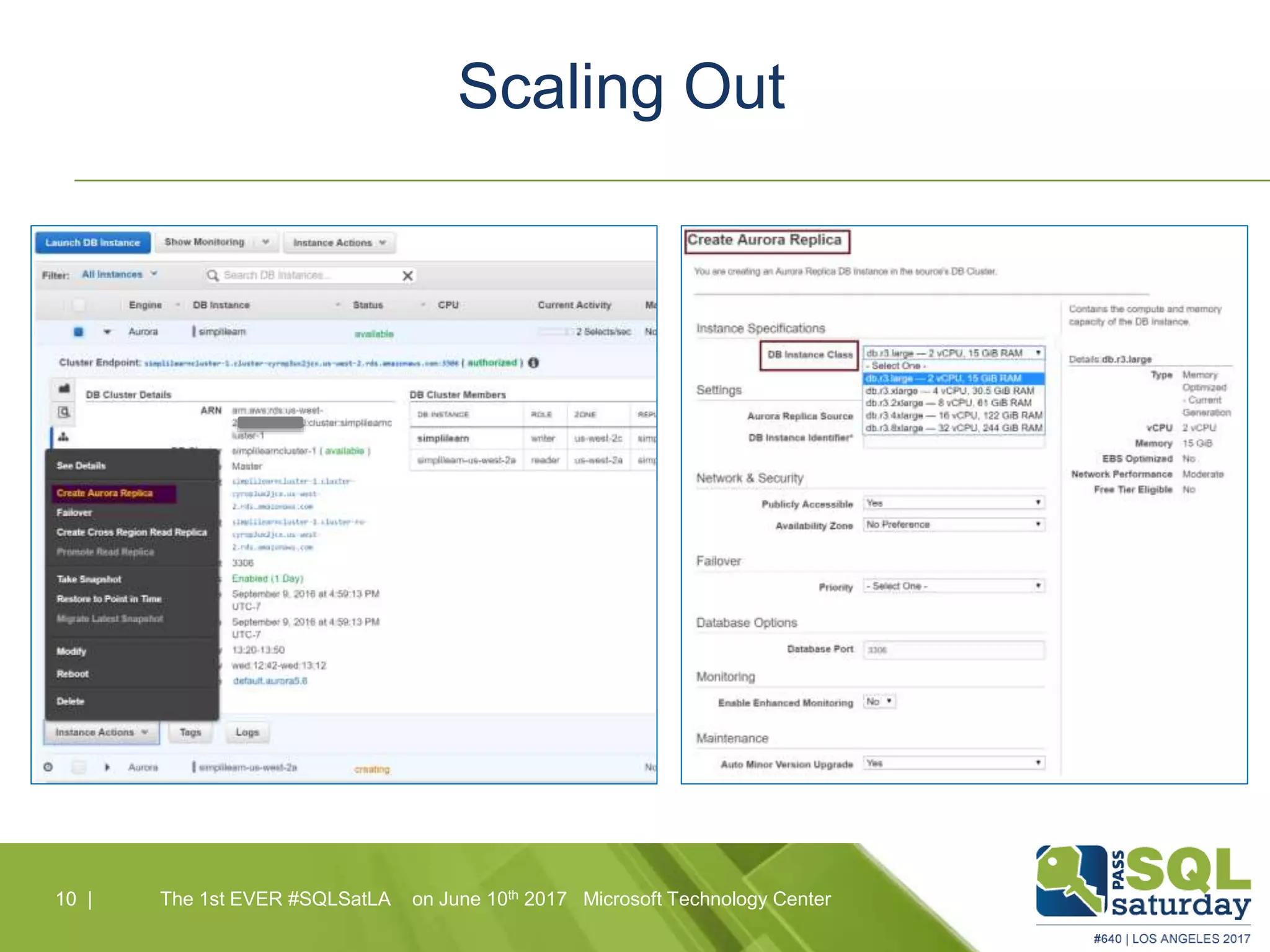
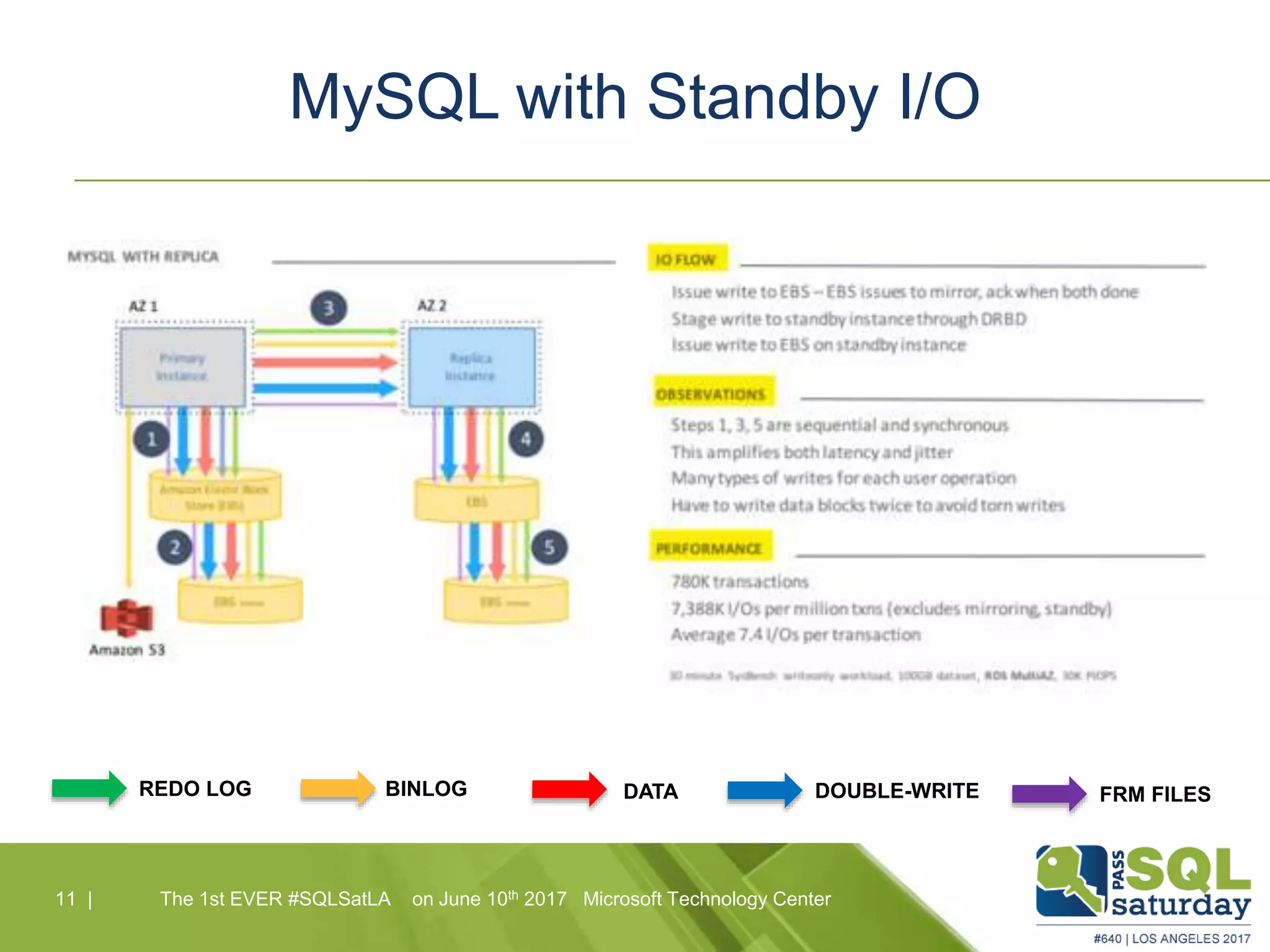
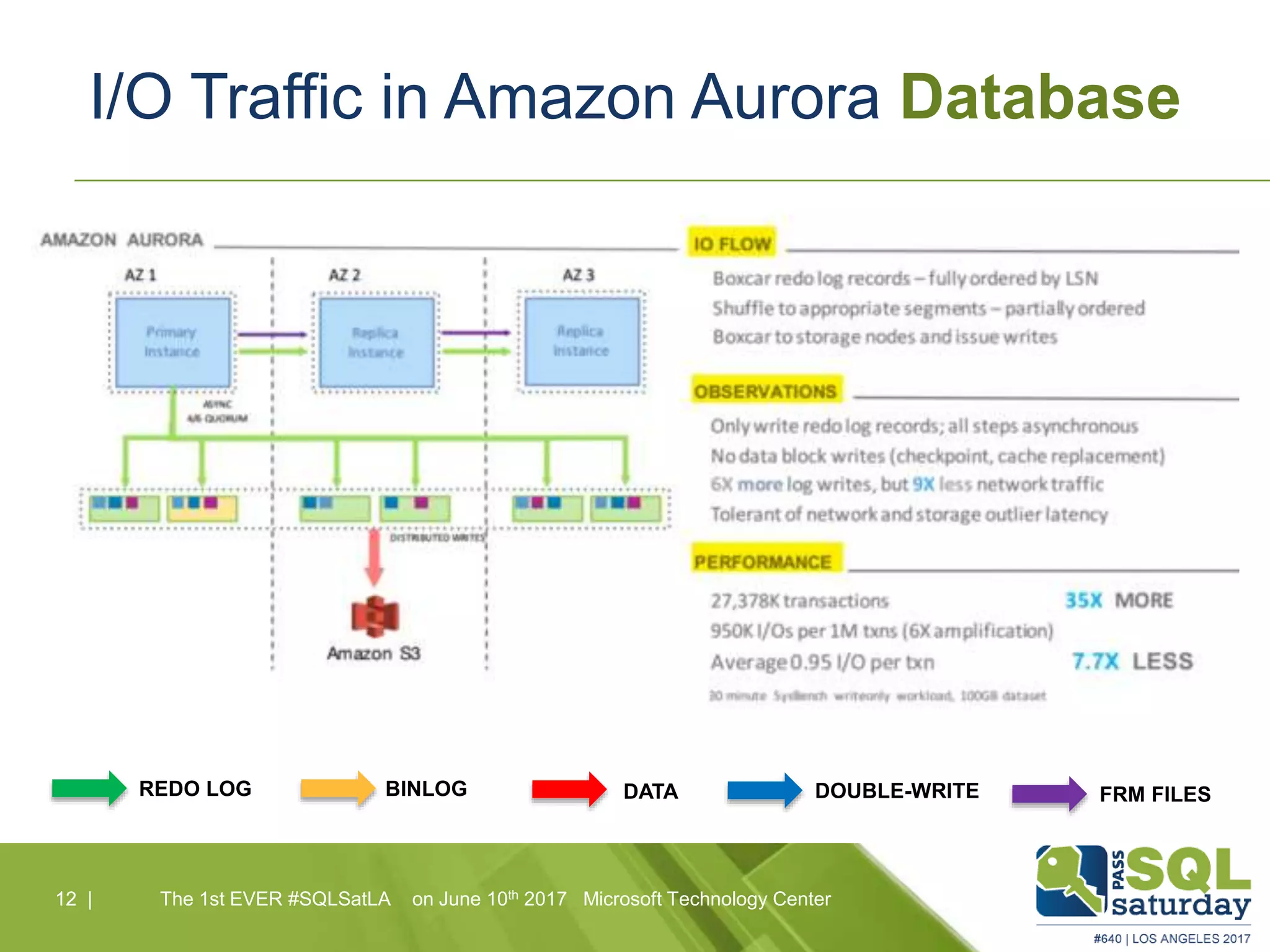
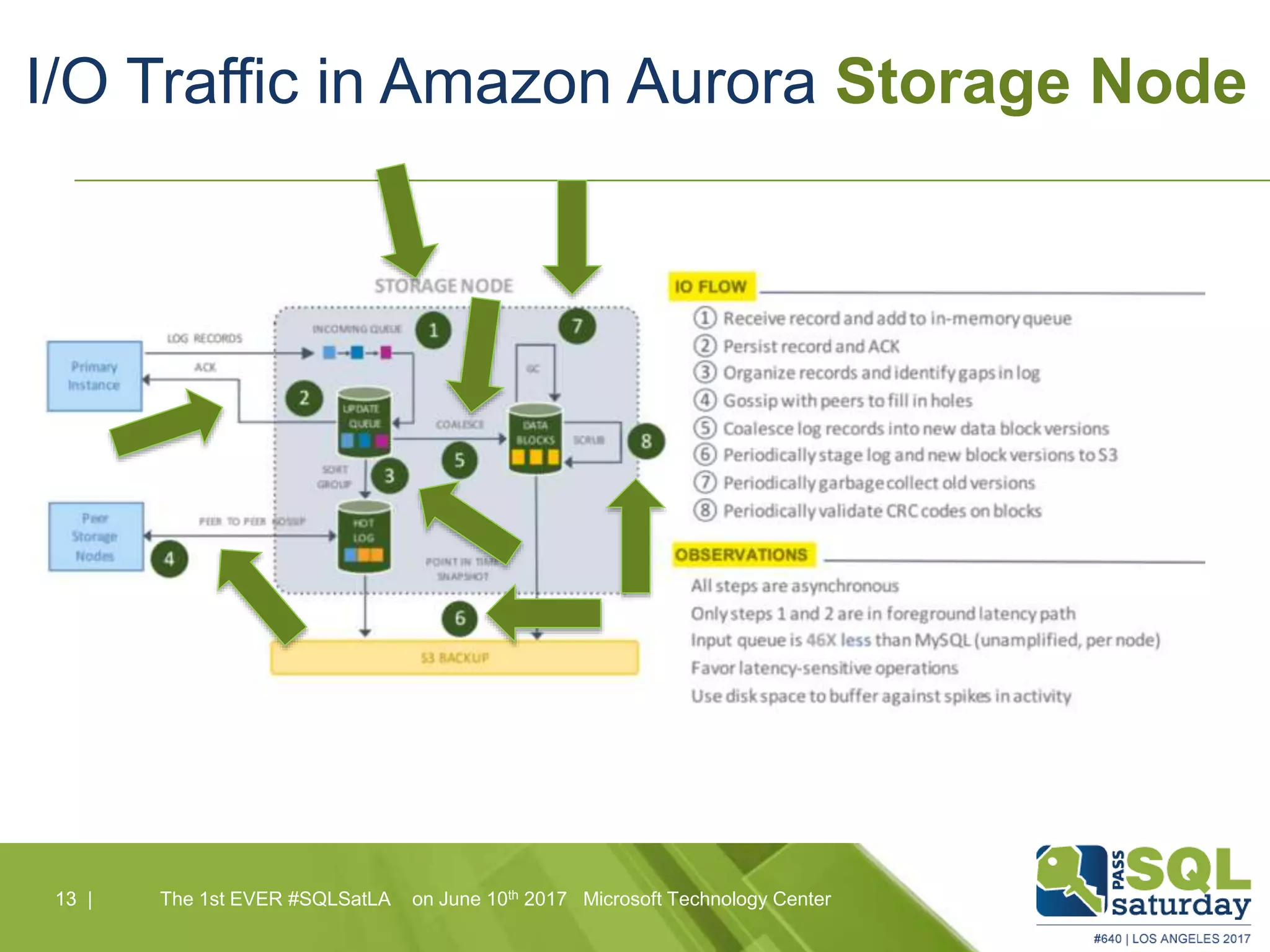

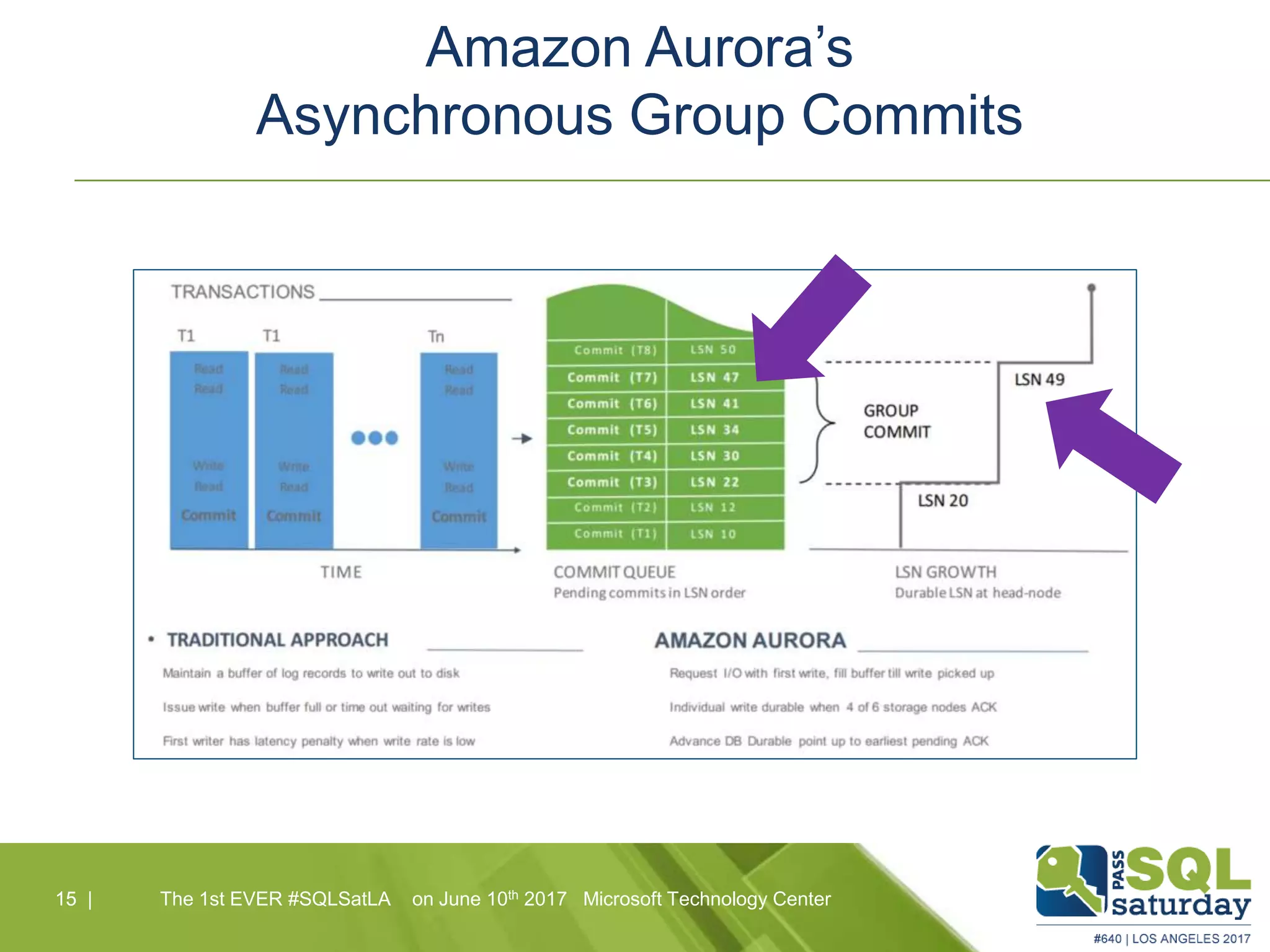
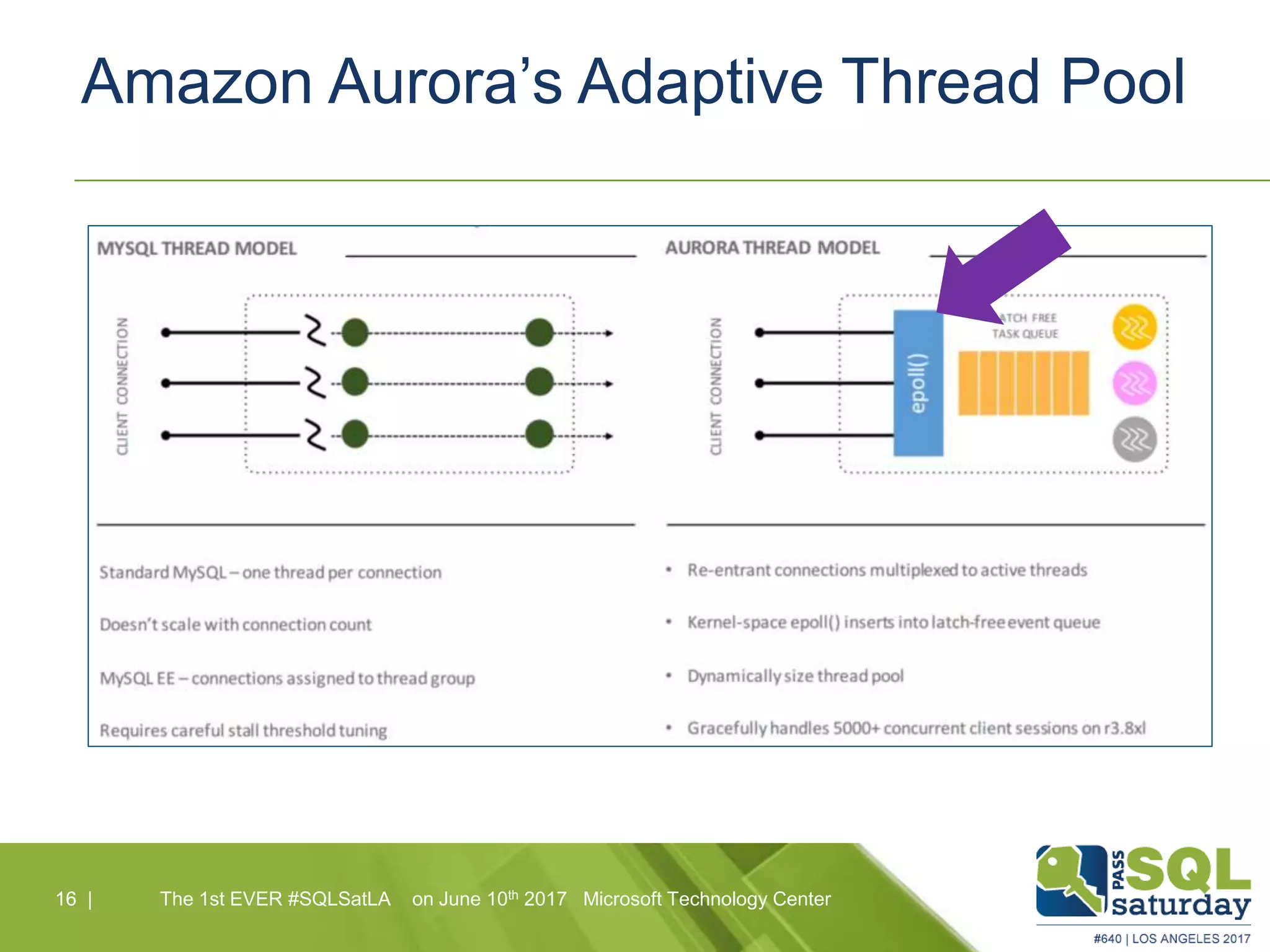

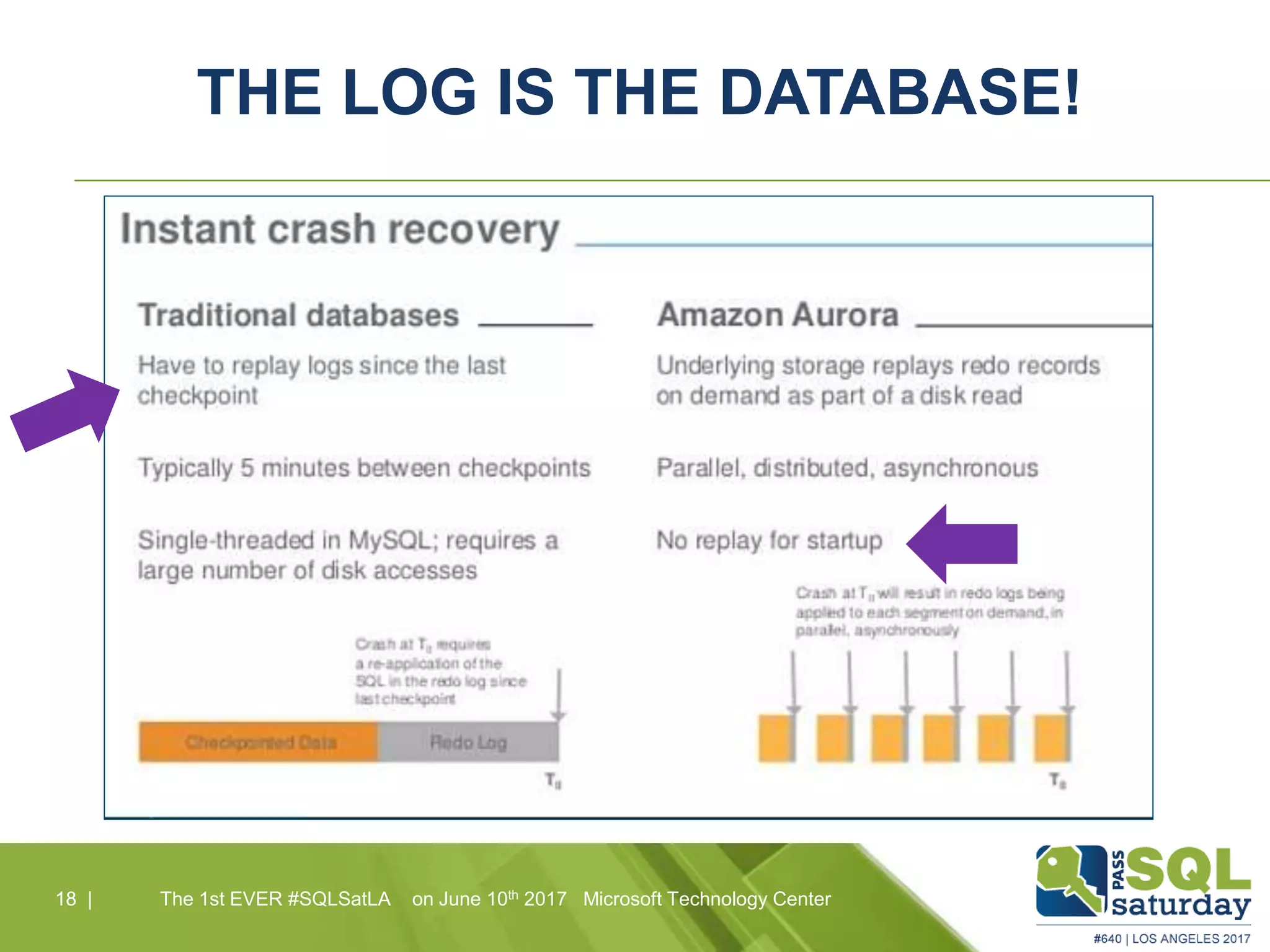

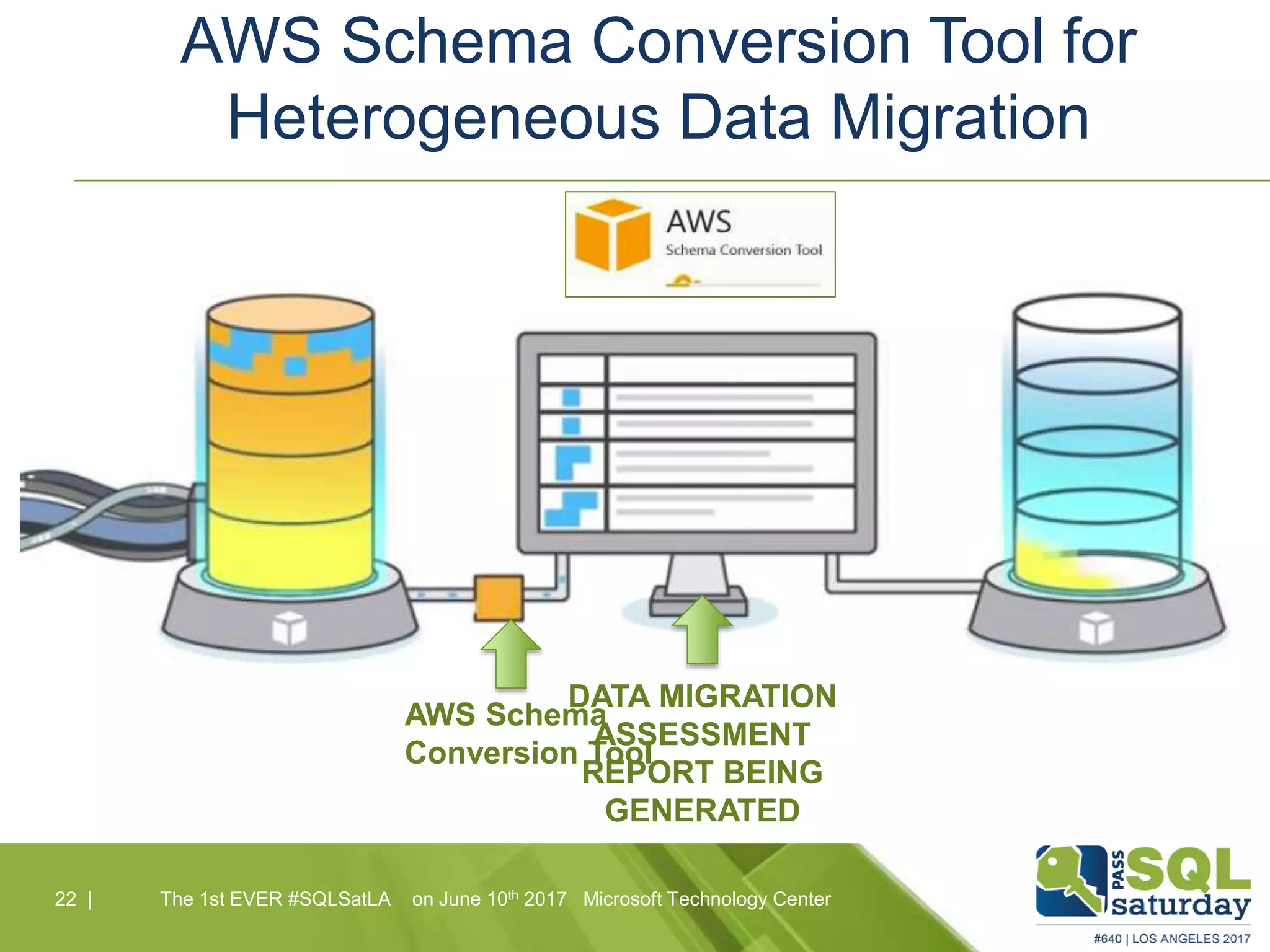

































Amazon Aurora is a fully-managed relational database service that combines the speed and reliability of high-end commercial databases with the simplicity of open source, offering significant cost savings and high availability. It features a unique architecture with decoupled storage and compute layers, enabling instant recovery and scalability up to 64 TB. The service also includes automated backups, continuous data protection, and is designed for seamless integration with other AWS services.




















































![[Redis Released]- FalkorDB - Redis + Graph Agentic Memory’s Secret Sauce](https://cdn.slidesharecdn.com/ss_thumbnails/redisreleased-falkordbslidedeck-1125-251115194922-e1c0046b-thumbnail.jpg?width=640&height=640&fit=bounds)


















