Download to read offline






![TRACK: SITE RELIABILTY ENGINEERING
Site reliability engineering (SRE) is a discipline
that incorporates aspects of software engineering
and applies them to infrastructure and operations
problems.[1] The main goals are to create
scalable and highly reliable software systems.
According to Ben Treynor, founder of Google's
Site Reliability Team, SRE is "what happens when
a software engineer is tasked with what used to
be called operations."
SRE to the Rescue!](https://image.slidesharecdn.com/addo2020-driving-digital-transformation-through-cloudops-and-sre-240401091115-5660b8d5/75/ADDO_2020-Driving-Digital-Transformation-through-CloudOps-and-SRE-pdf-8-2048.jpg)


















![TRACK: SITE RELIABILTY ENGINEERING
Site reliability engineering (SRE) is a discipline
that incorporates aspects of software engineering
and applies them to infrastructure and operations
problems.[1] The main goals are to create
scalable and highly reliable software systems.
According to Ben Treynor, founder of Google's
Site Reliability Team, SRE is "what happens when
a software engineer is tasked with what used to
be called operations."
SRE to the Rescue!](https://crownmelresort.com/image.slidesharecdn.com/addo2020-driving-digital-transformation-through-cloudops-and-sre-240401091115-5660b8d5/75/ADDO_2020-Driving-Digital-Transformation-through-CloudOps-and-SRE-pdf-8-2048.jpg)


















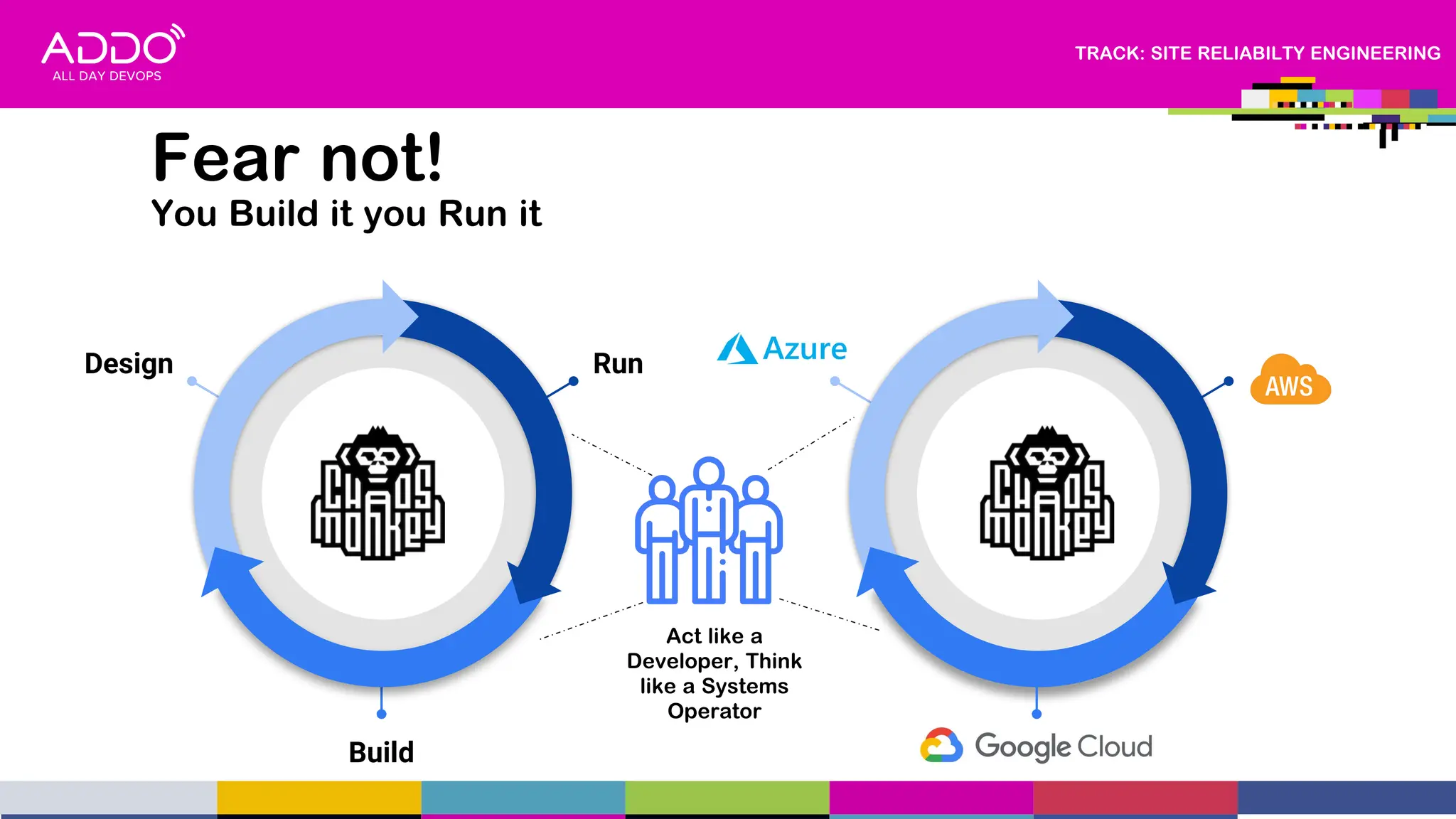
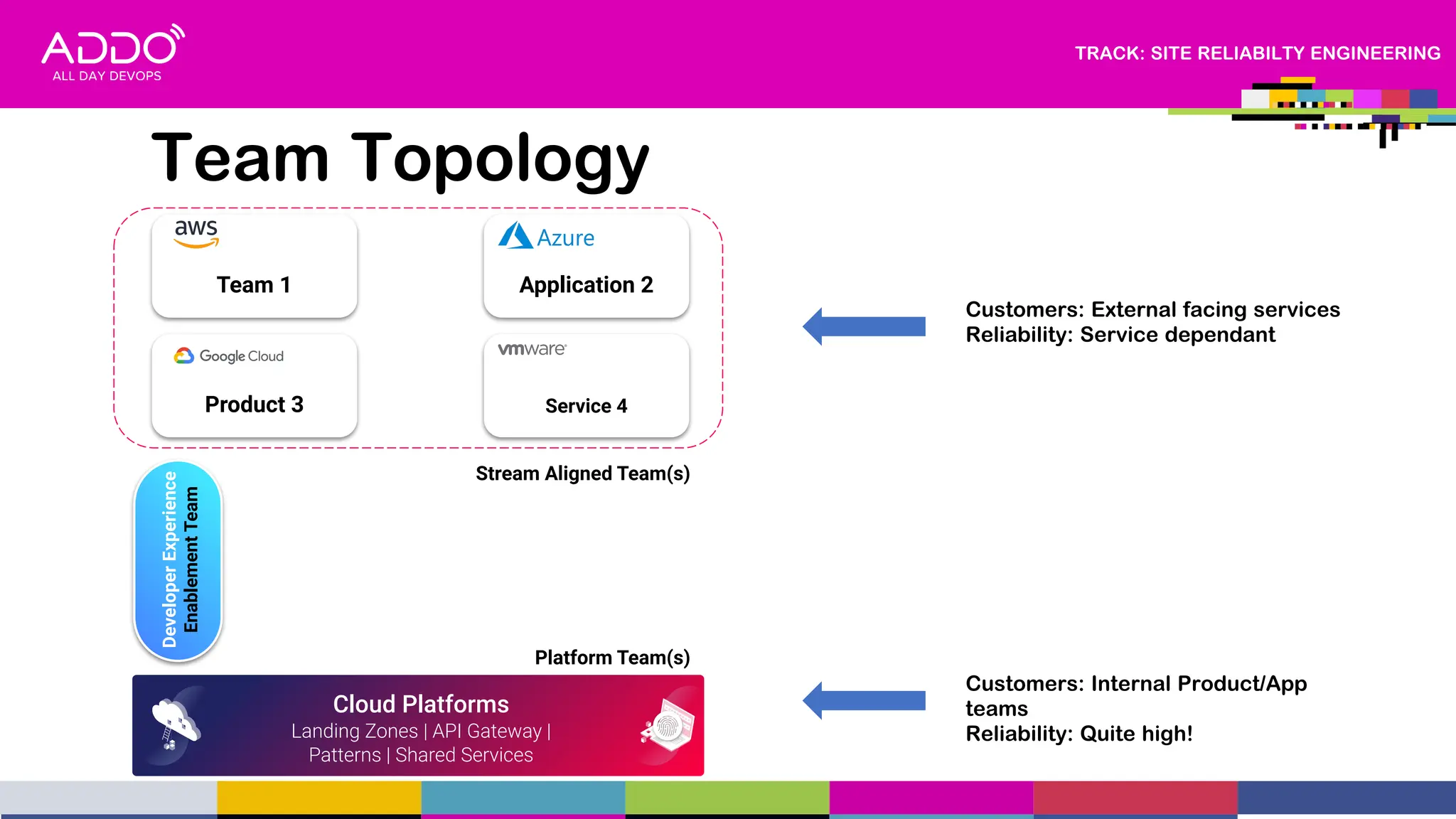
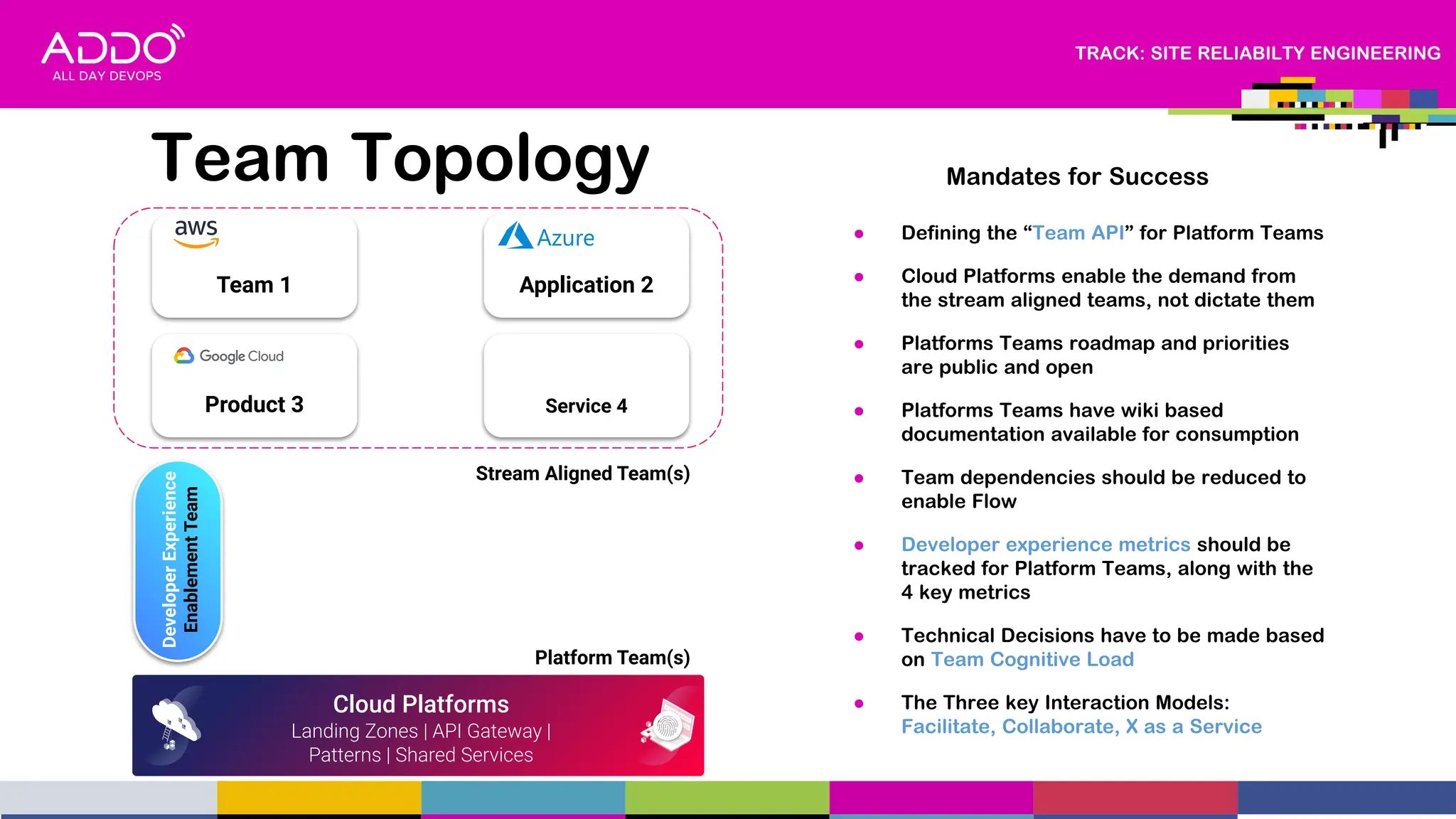
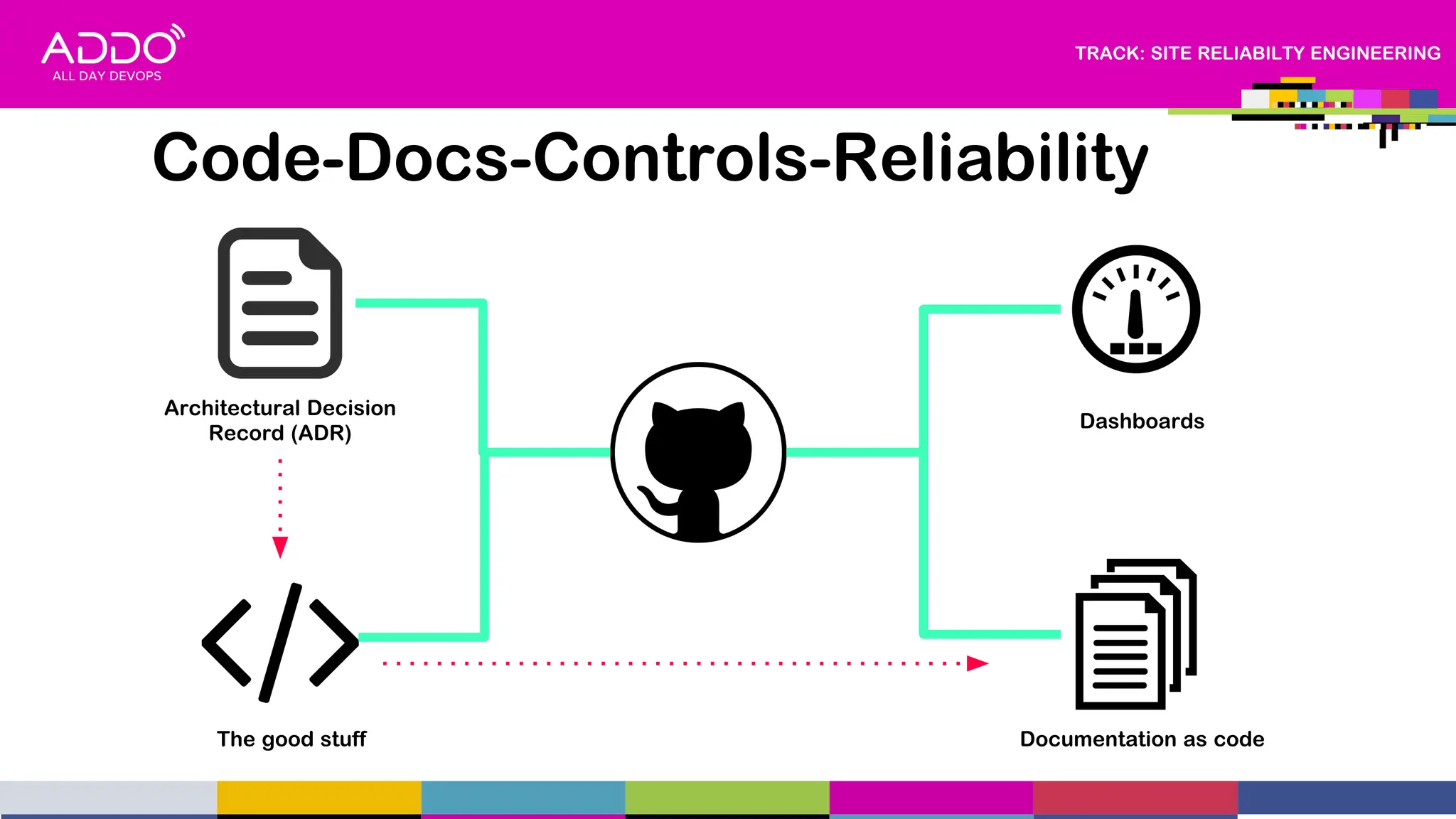
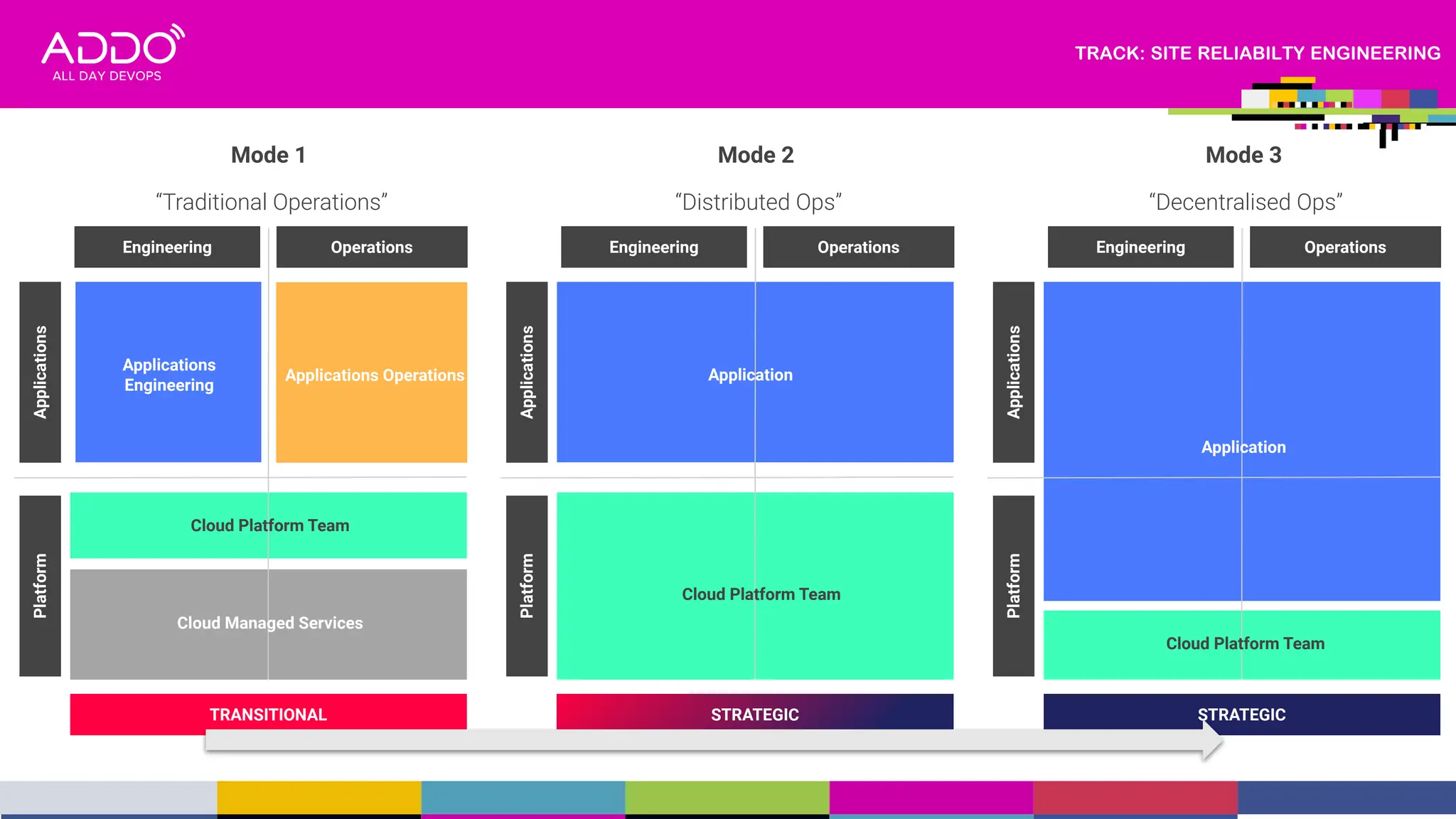
This document provides an overview of a presentation on driving digital transformation through CloudOps and Site Reliability Engineering (SRE). The presentation discusses multi-cloud adoption within regulated industries, advocating for mature engineering practices with a focus on SRE, FinOps, GitOps, and DevSecOps. It also covers helping to develop cloud native products and services for enterprises and building sustainable digital capabilities.




![Site-Reliability-Engineering-v2[6241].pdf](https://cdn.slidesharecdn.com/ss_thumbnails/site-reliability-engineering-v26241-221023035909-82e9559b-thumbnail.jpg?width=640&height=640&fit=bounds)










































