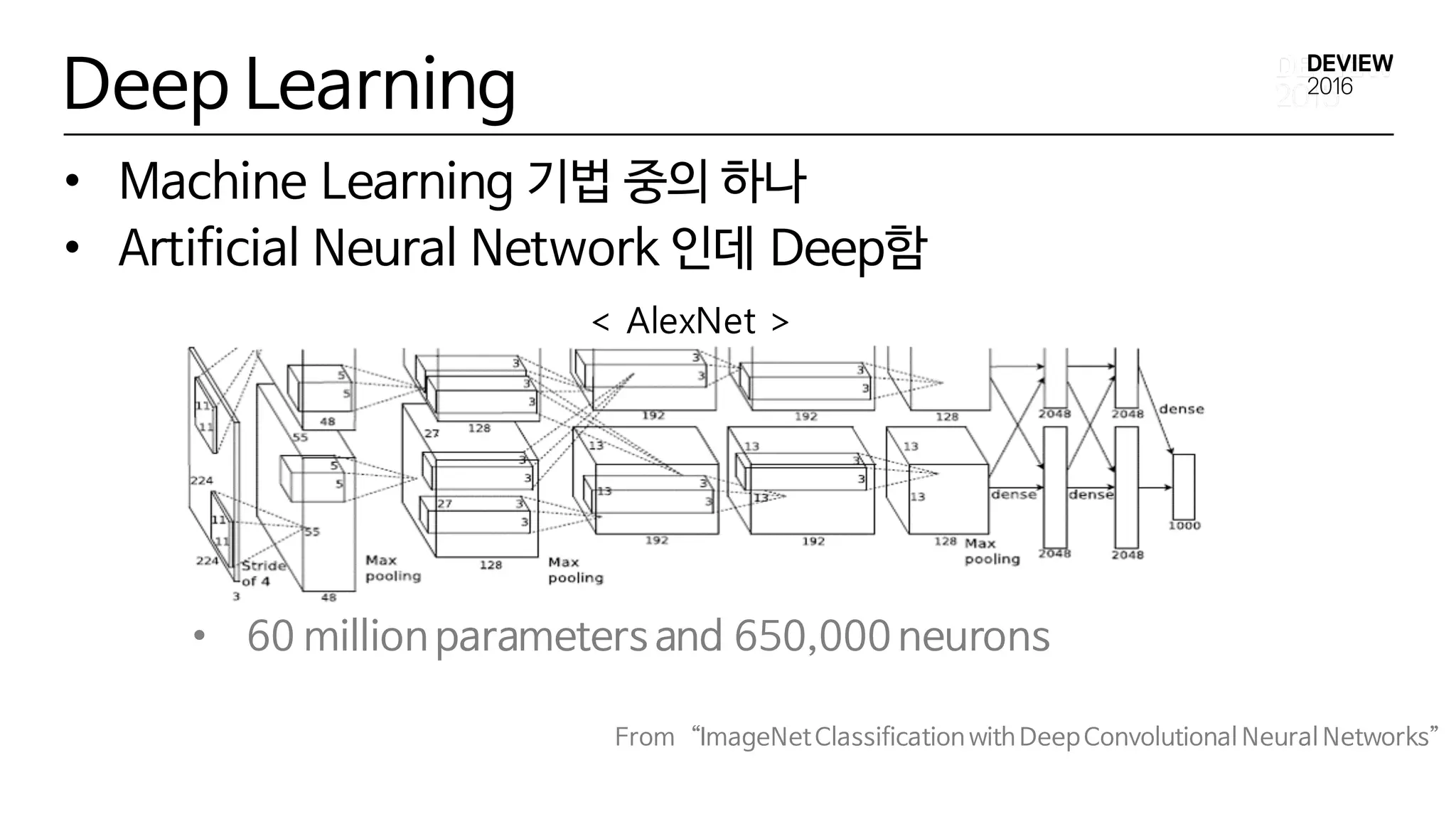
Deep Learning
• MachineLearning 기법 중의 하나
• Artificial Neural Network 인데 Deep함
< AlexNet >
• 60 million parameters and 650,000 neurons
From “ImageNetClassification with Deep Convolutional Neural Networks”
7.
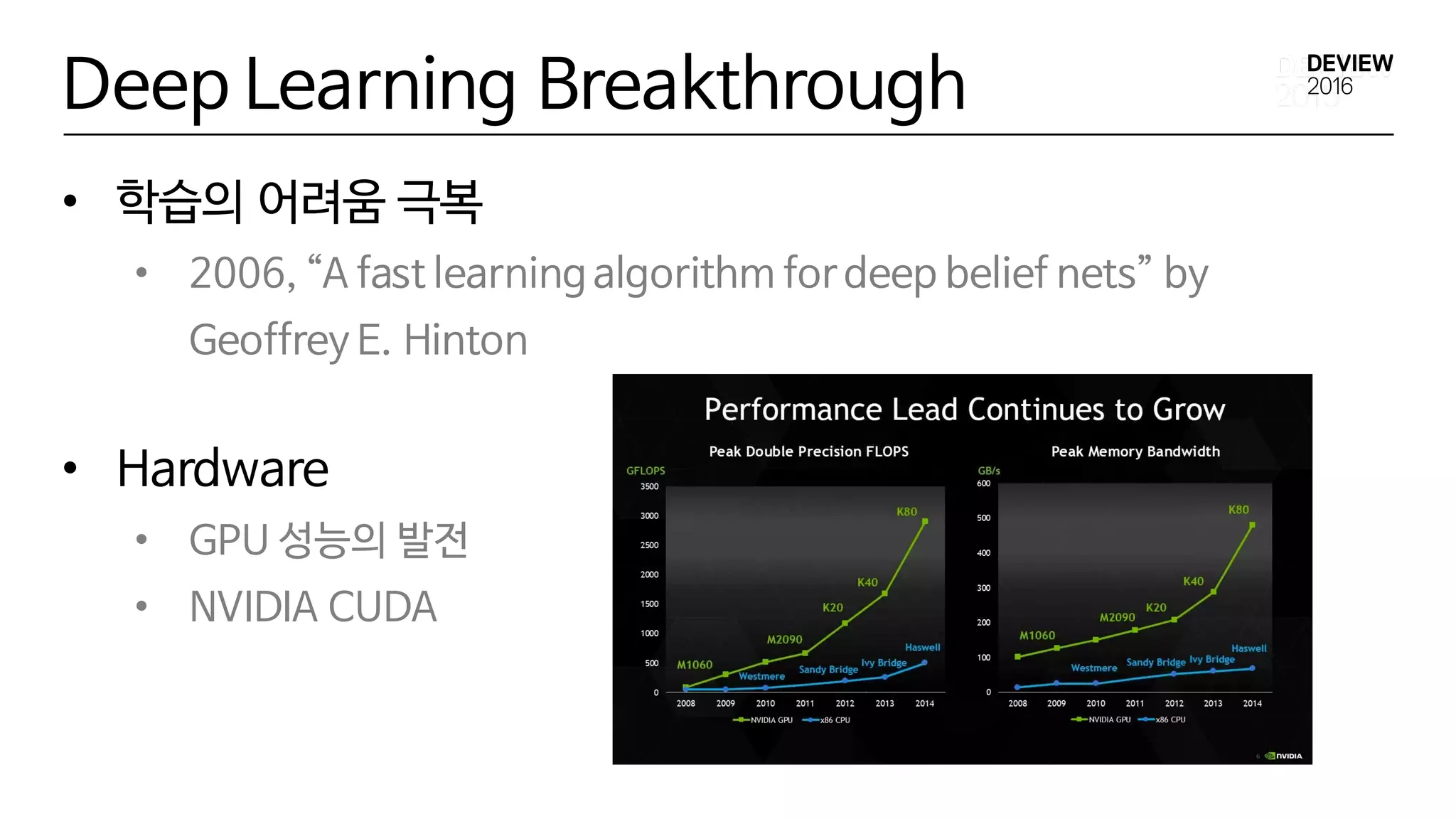
Deep Learning Breakthrough
•학습의 어려움 극복
• 2006, “A fast learning algorithm for deep belief nets” by
Geoffrey E. Hinton
• Hardware
• GPU 성능의 발전
• NVIDIA CUDA
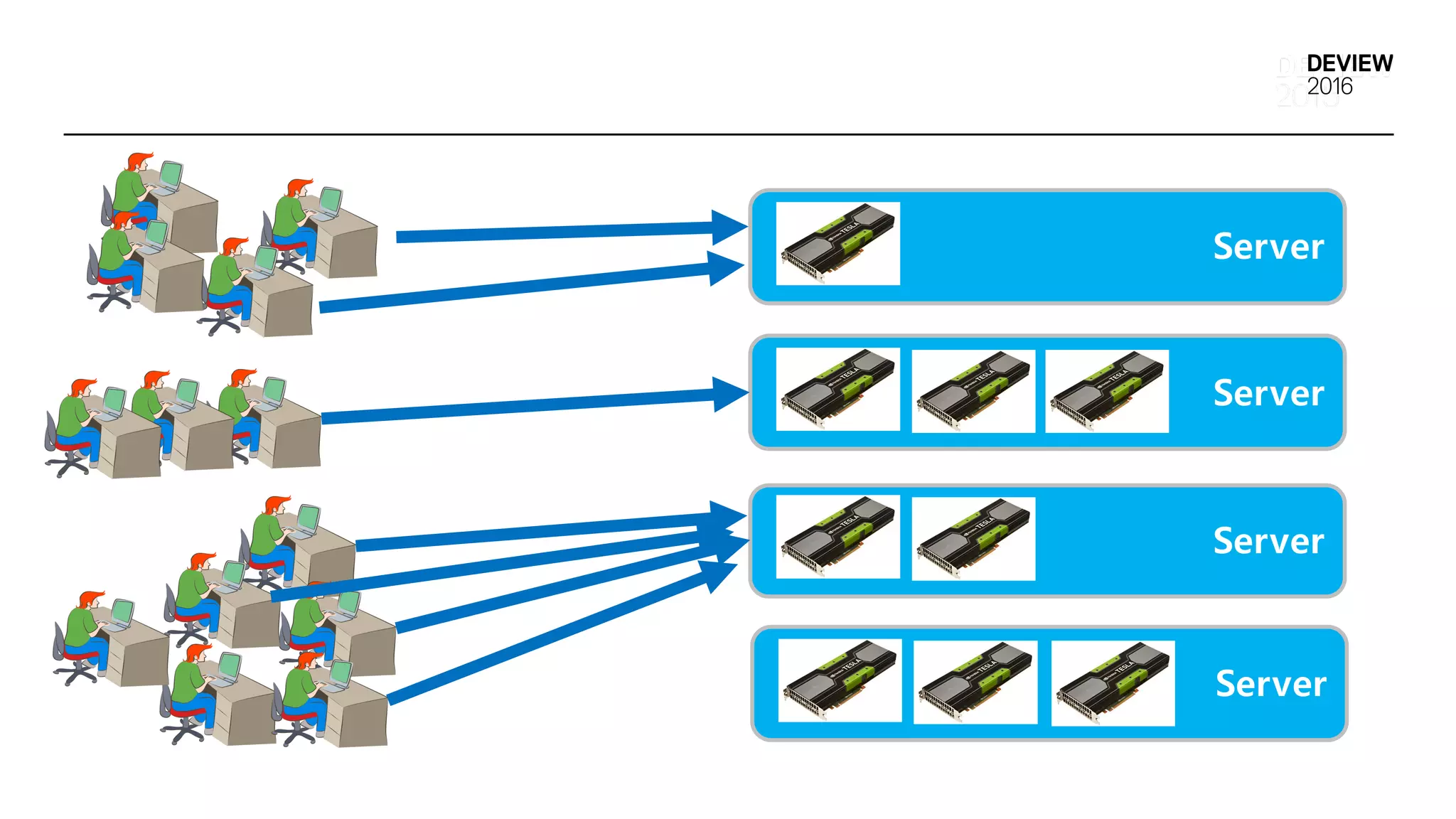
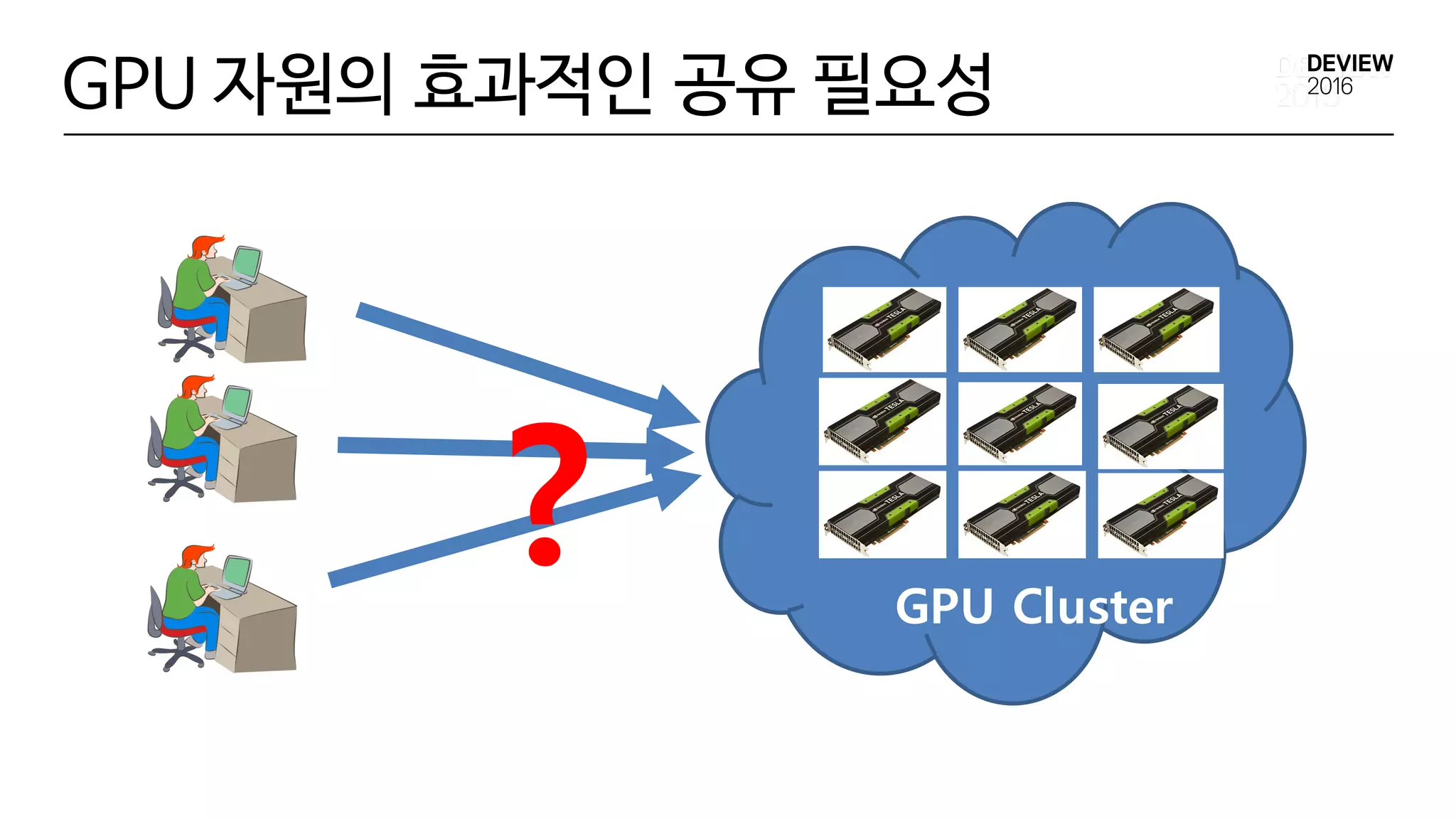
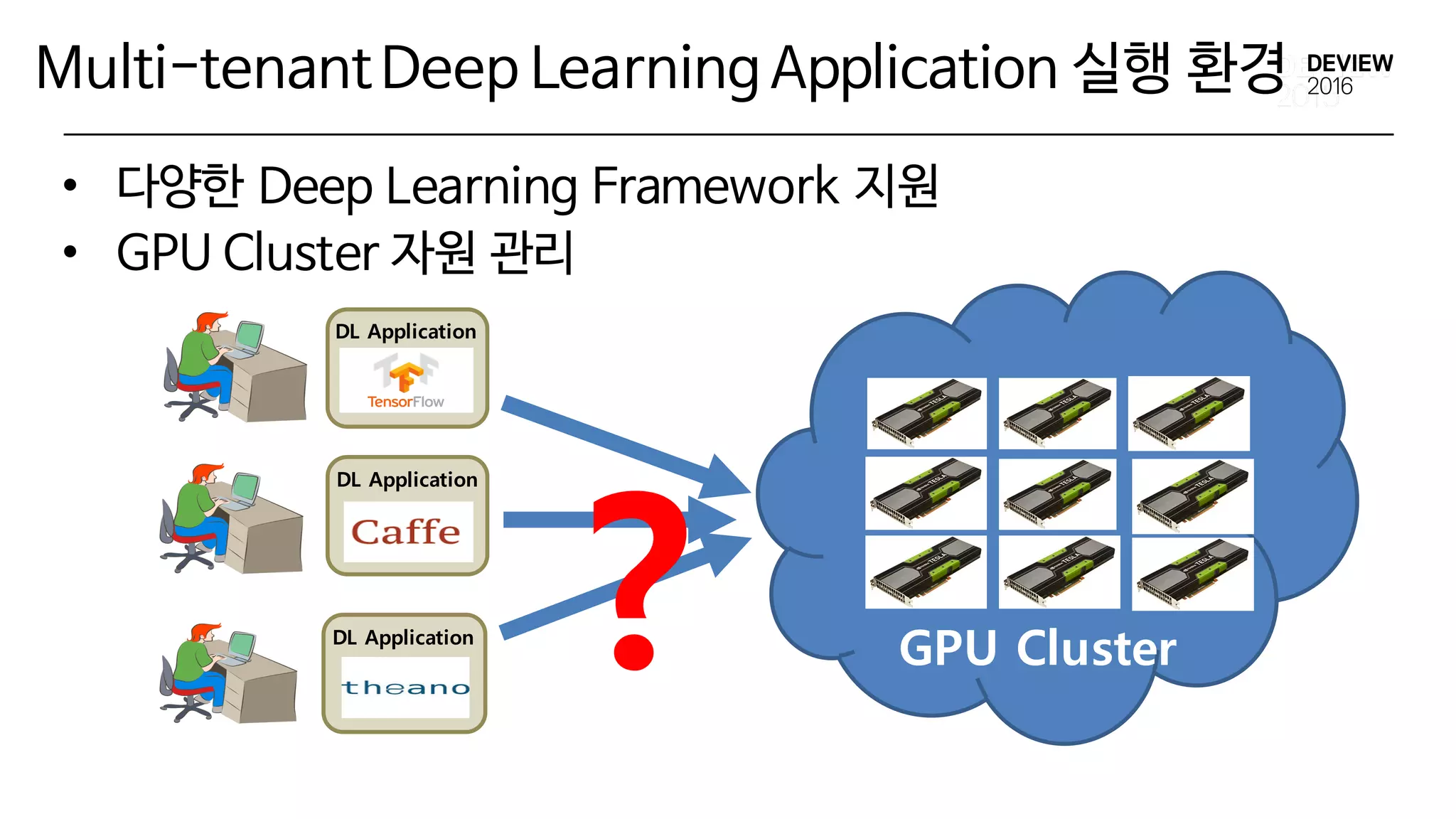
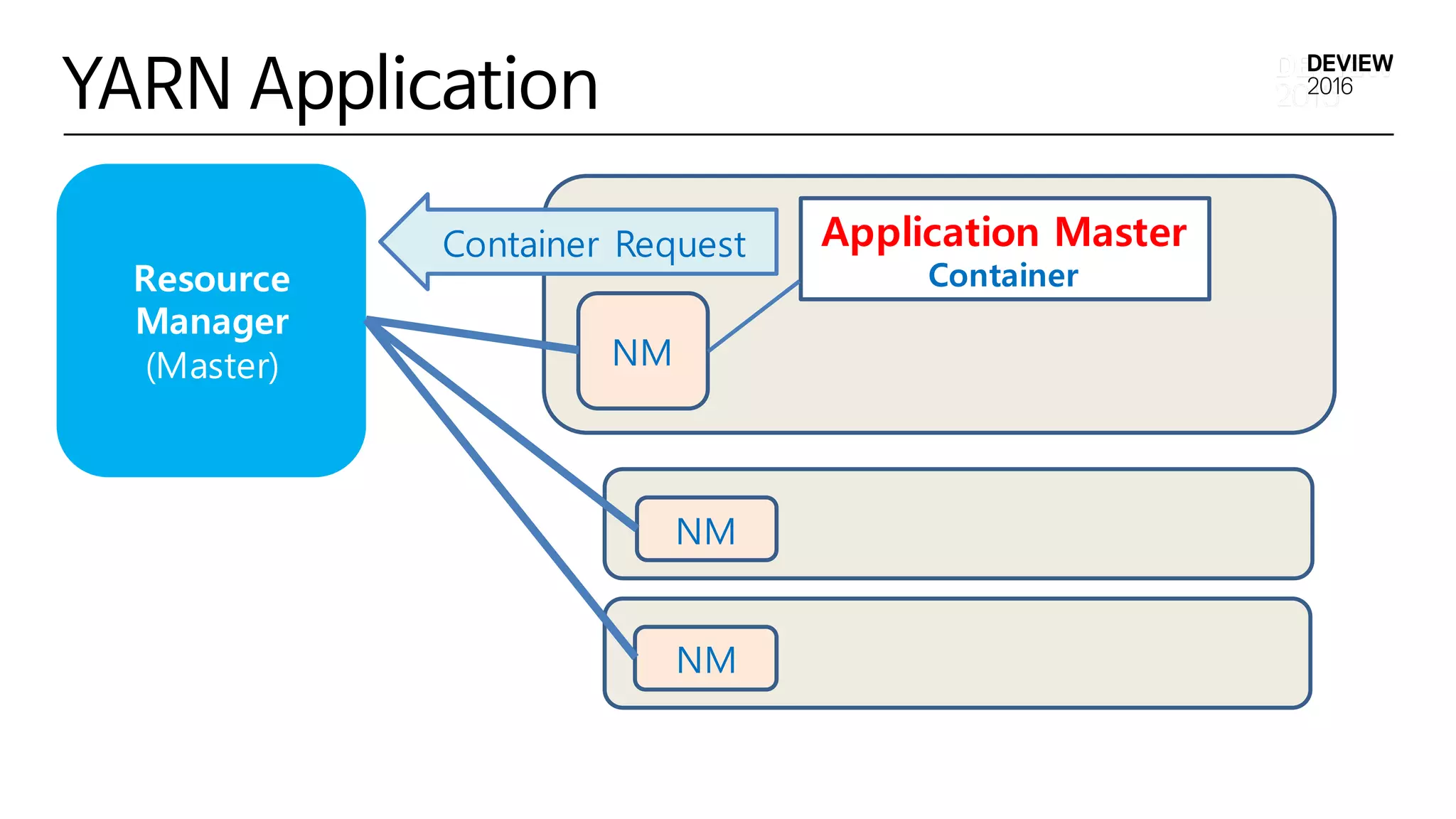
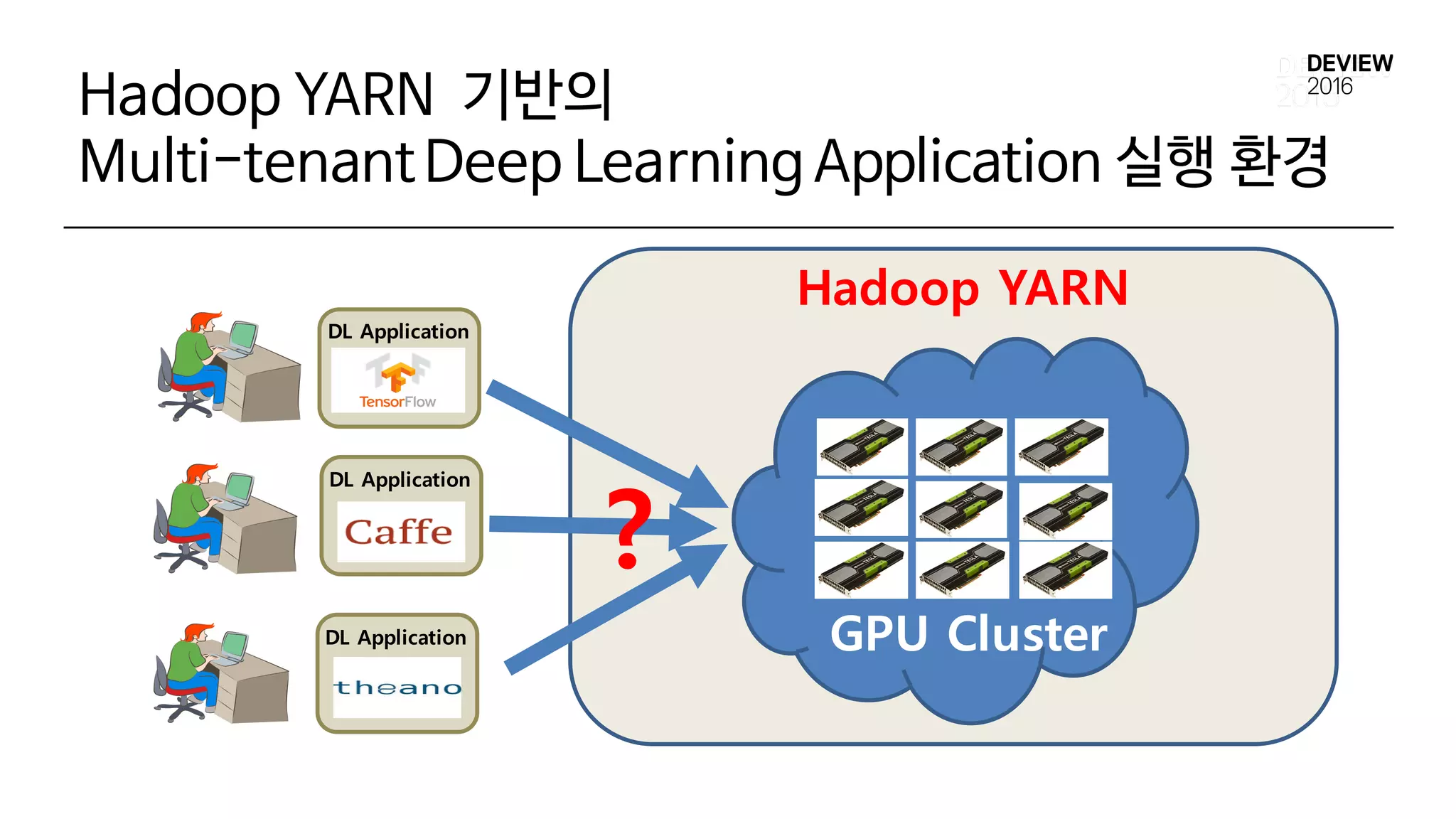
Multi-tenantDeep Learning Application실행 환경
• 다양한 Deep Learning Framework 지원
• GPU Cluster 자원 관리
? GPU Cluster
DL Application
DL Application
DL Application
16.
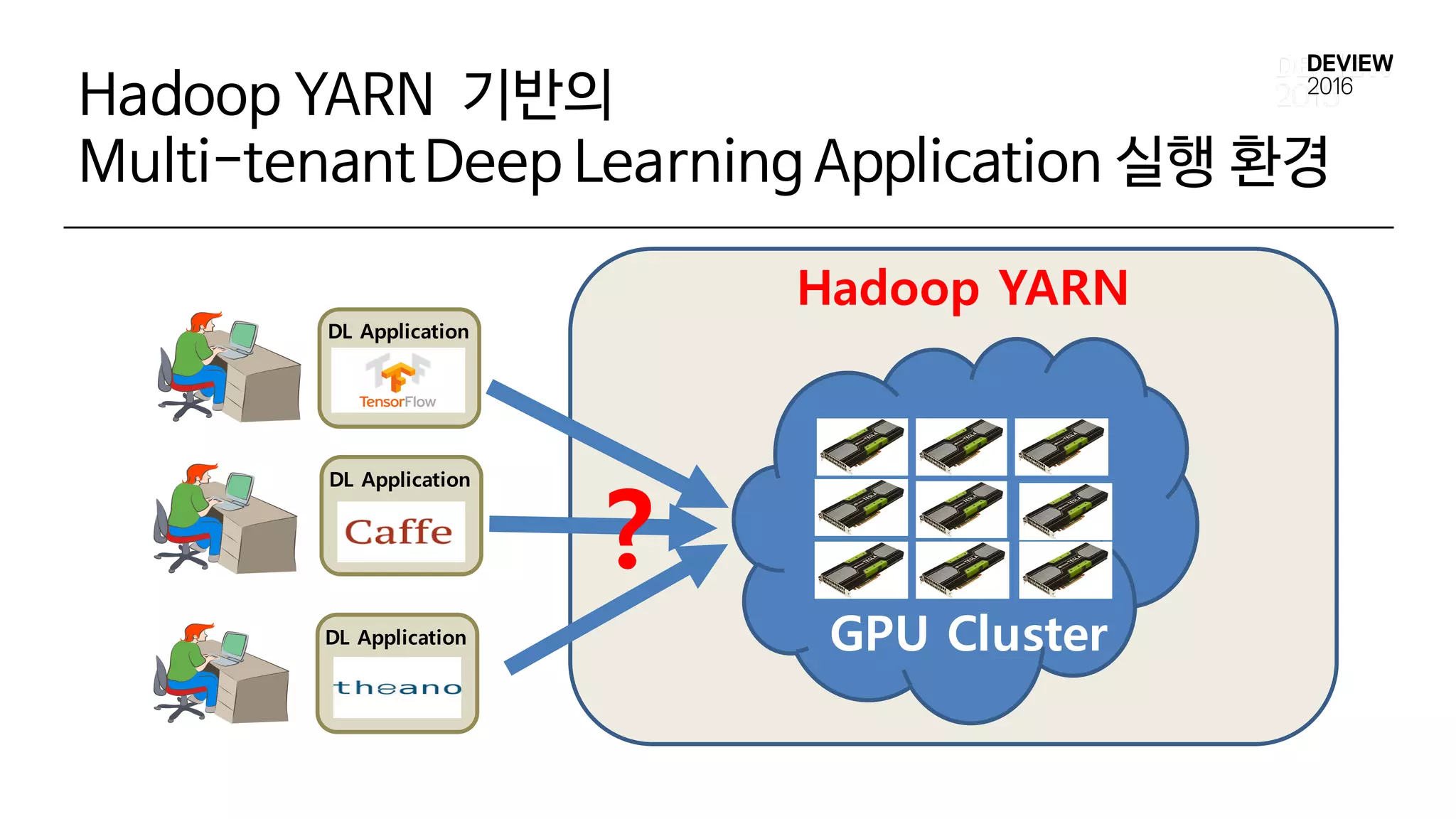
Hadoop YARN 기반의
Multi-tenantDeepLearning Application 실행 환경
?
GPU Cluster
Hadoop YARN
DL Application
DL Application
DL Application
17.
Why YARN ?
•Mesos ?
• YARN의 장점
• Capacity Scheduler : Queue기반의 ResourceScheduling
• Enterprise환경에서 ResourcePlanning 용이
• 기타
• 기존 클러스터(C3)와의 호환성 및 통합 가능성
• Cluster 배포 및 관리 시스템 기존재 (Ambari)
• YARN Cluster 운영 Knowhow
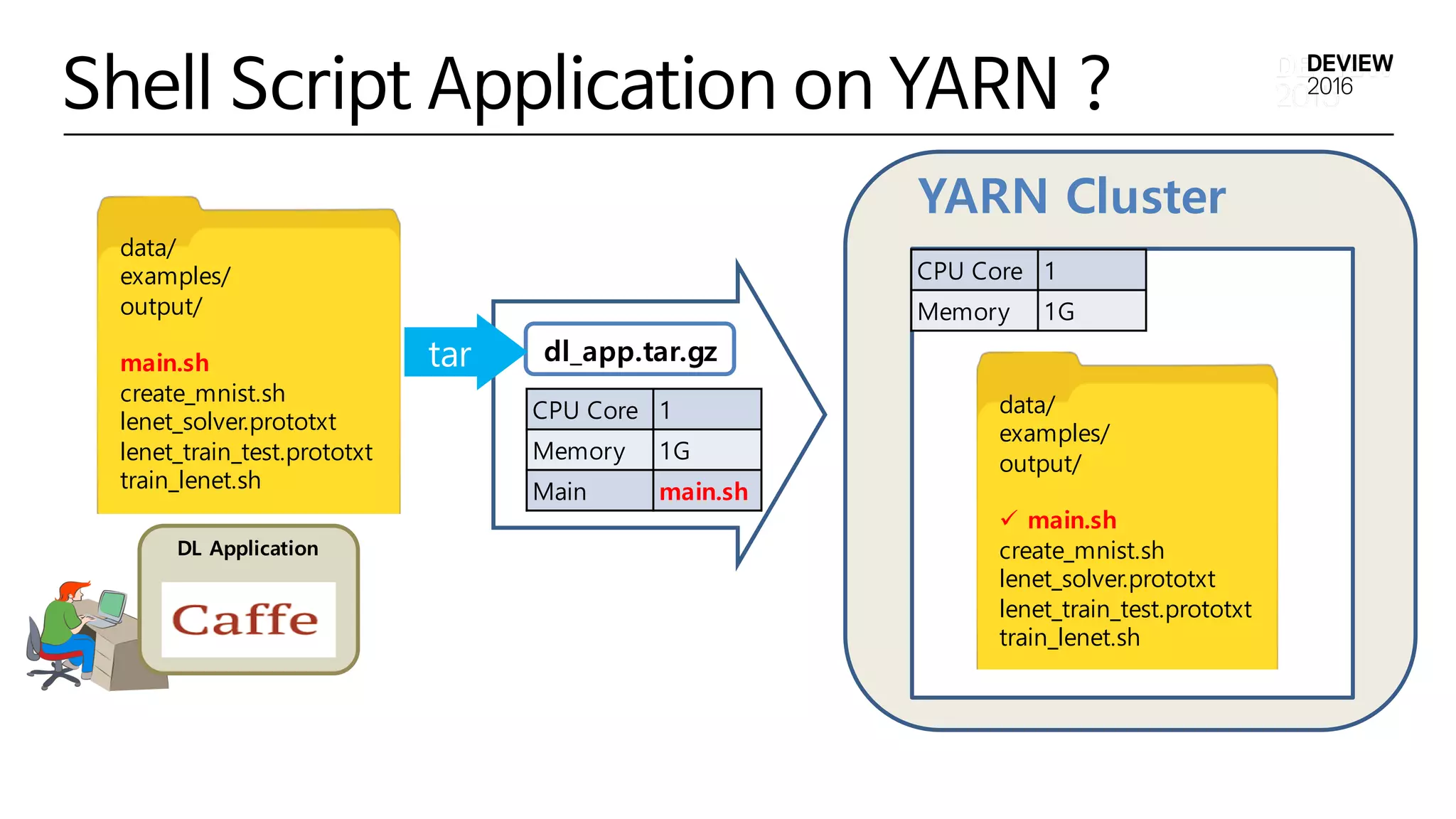
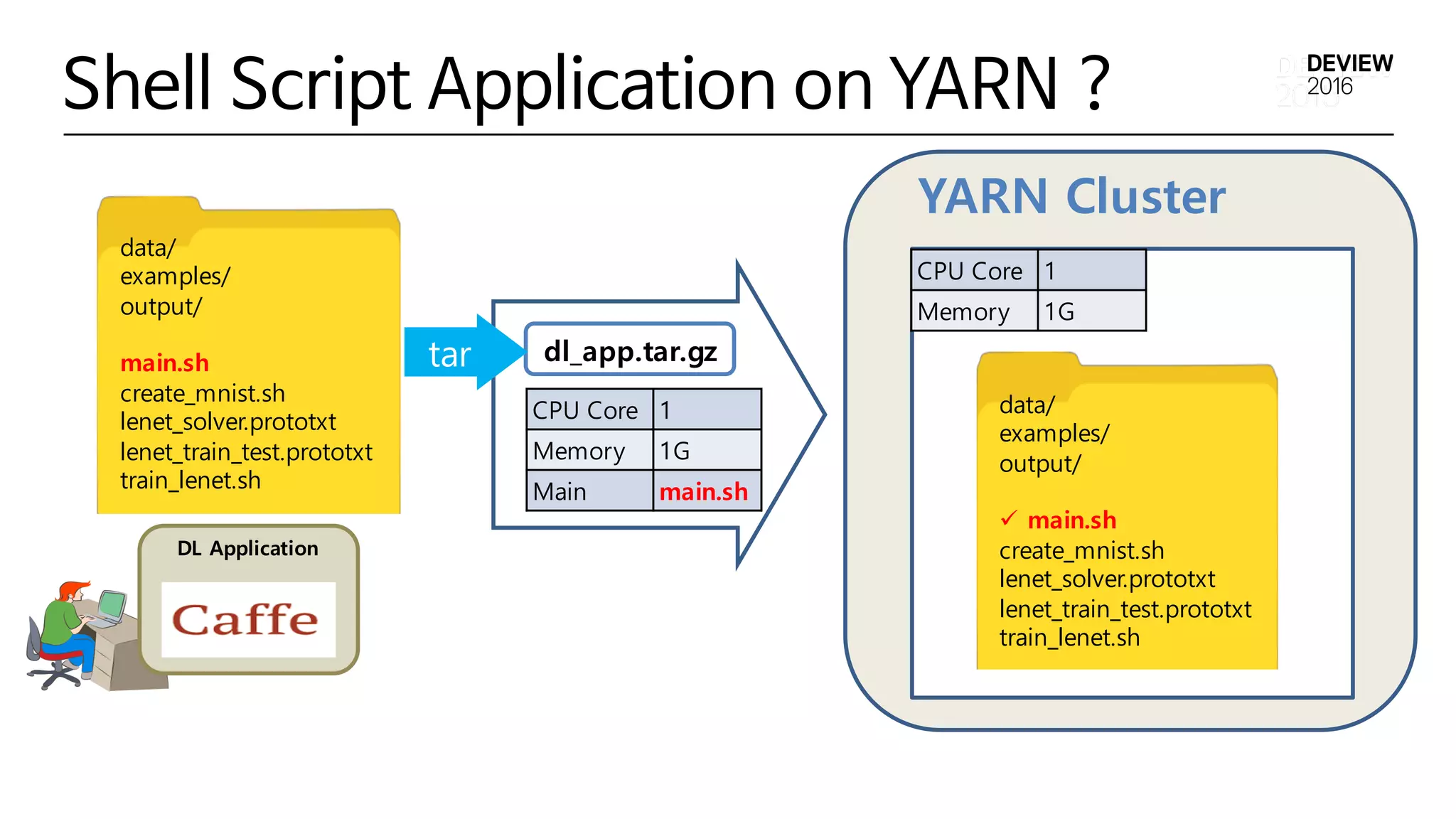
Shell Script Applicationon YARN ?
YARN Cluster
CPU Core 1
Memory 1G
Main main.sh
dl_app.tar.gz
data/
examples/
output/
main.sh
create_mnist.sh
lenet_solver.prototxt
lenet_train_test.prototxt
train_lenet.sh
data/
examples/
output/
ü main.sh
create_mnist.sh
lenet_solver.prototxt
lenet_train_test.prototxt
train_lenet.sh
CPU Core 1
Memory 1G
tar
DL Application
23.
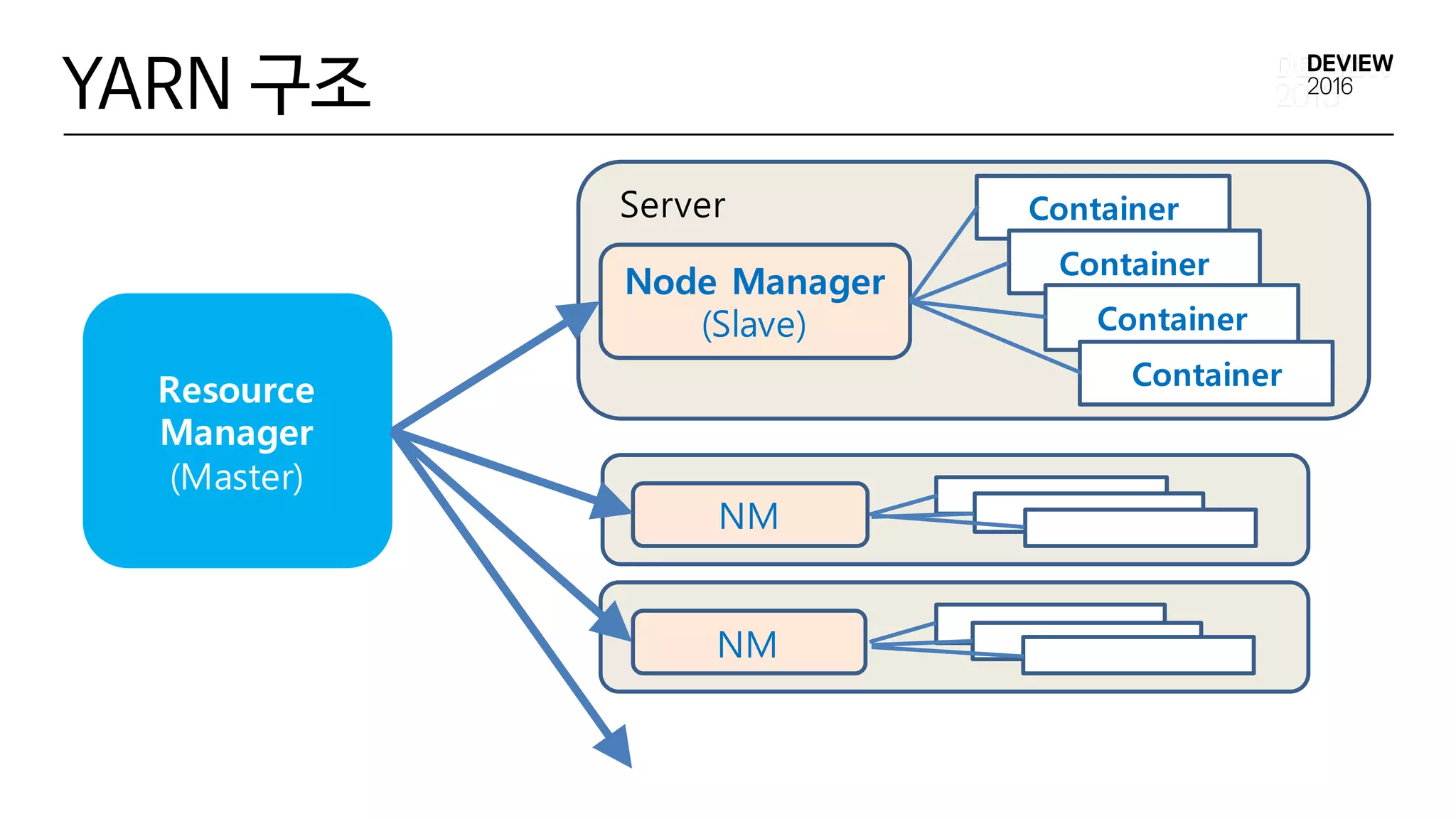
Hadoop YARN
• HadoopYARN ( Hadoop v2)
• Yet Another ResourceNegotiator
• MapReduce이외에 일반적인 Application 실행 가능
• CPU,Memory 기반의 ResourceScheduling
• YARN 구조
• ResourceManager ( Master)
• Node Manager ( Slaves )
• 최소 실행 단위 : Container
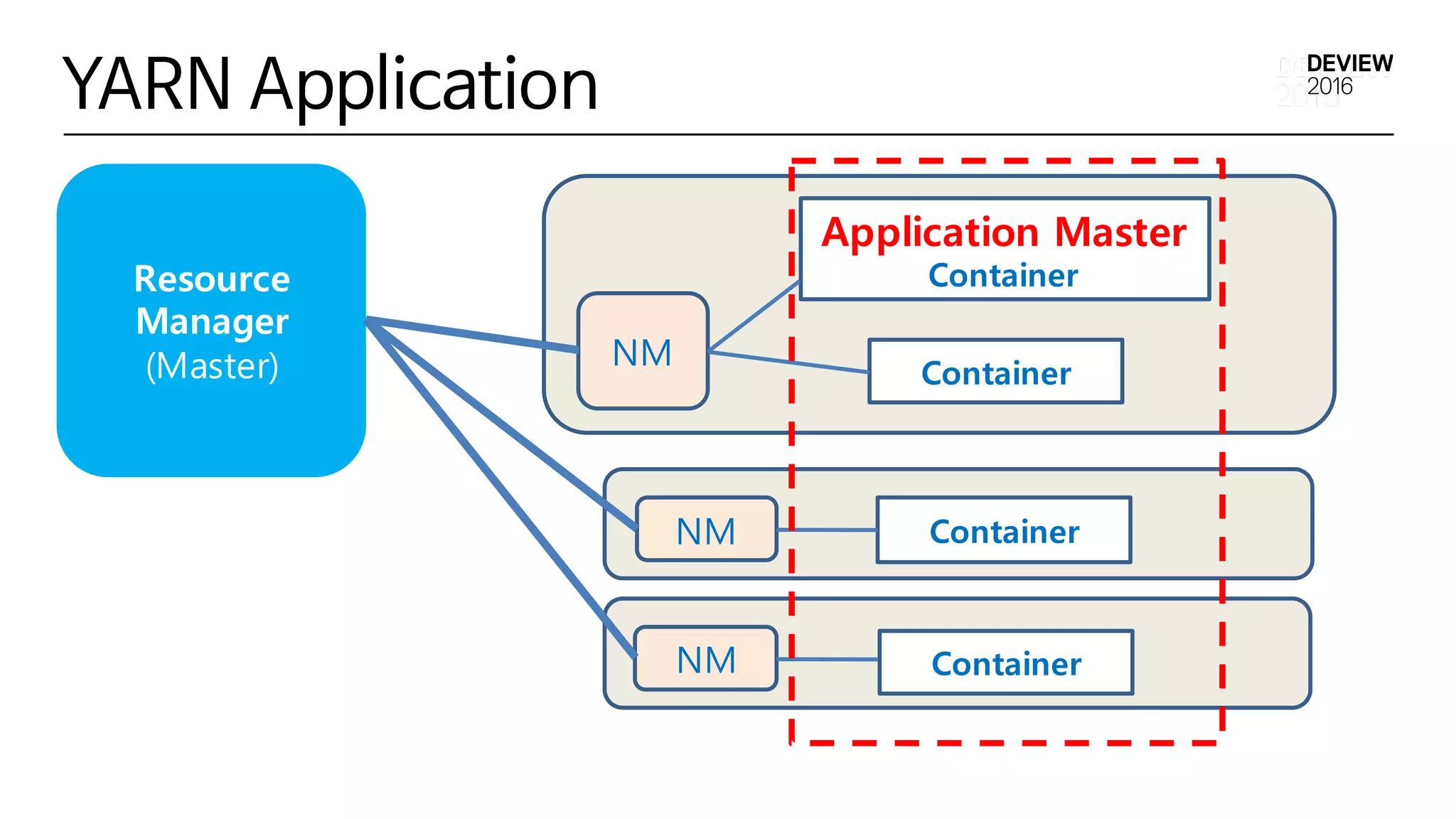
C3 Distributed Shell
•Yarn Distributed Shell 기반
• 추가 기능
• CONTAINTER_INDEX, NUM_CONTAINERS 환경 변수
• YARN-5696
• Server Node 에 따른 Resource요청
• 특정 Server Node 에 Resource요청
• Server Node Blacklist설정
• YARN-4703
31.
Technical Issues
ü YARNCluster에서 Shell Script Application 실행
2) 다양한 Deep Learning Framework 환경 제공
3) YARN Cluster에서 GPU Resource Scheduling
è C3 Distributed Shell
Classical Approach
• 모든DL Framework를 모든 서버에 설치
• Installation, Upgrade, Update 등 유지 보수의 어려움
• 같은 DL Framework 에서 Multi Version 지원 이슈
• 서로 상이한 DL Framework간의 Library 의존성 충돌
• DevOps Tools :
• Dimensions
• ( DL Framworks ) * ( Versions ) * ( 의존 libs ) * ( Server 환경)
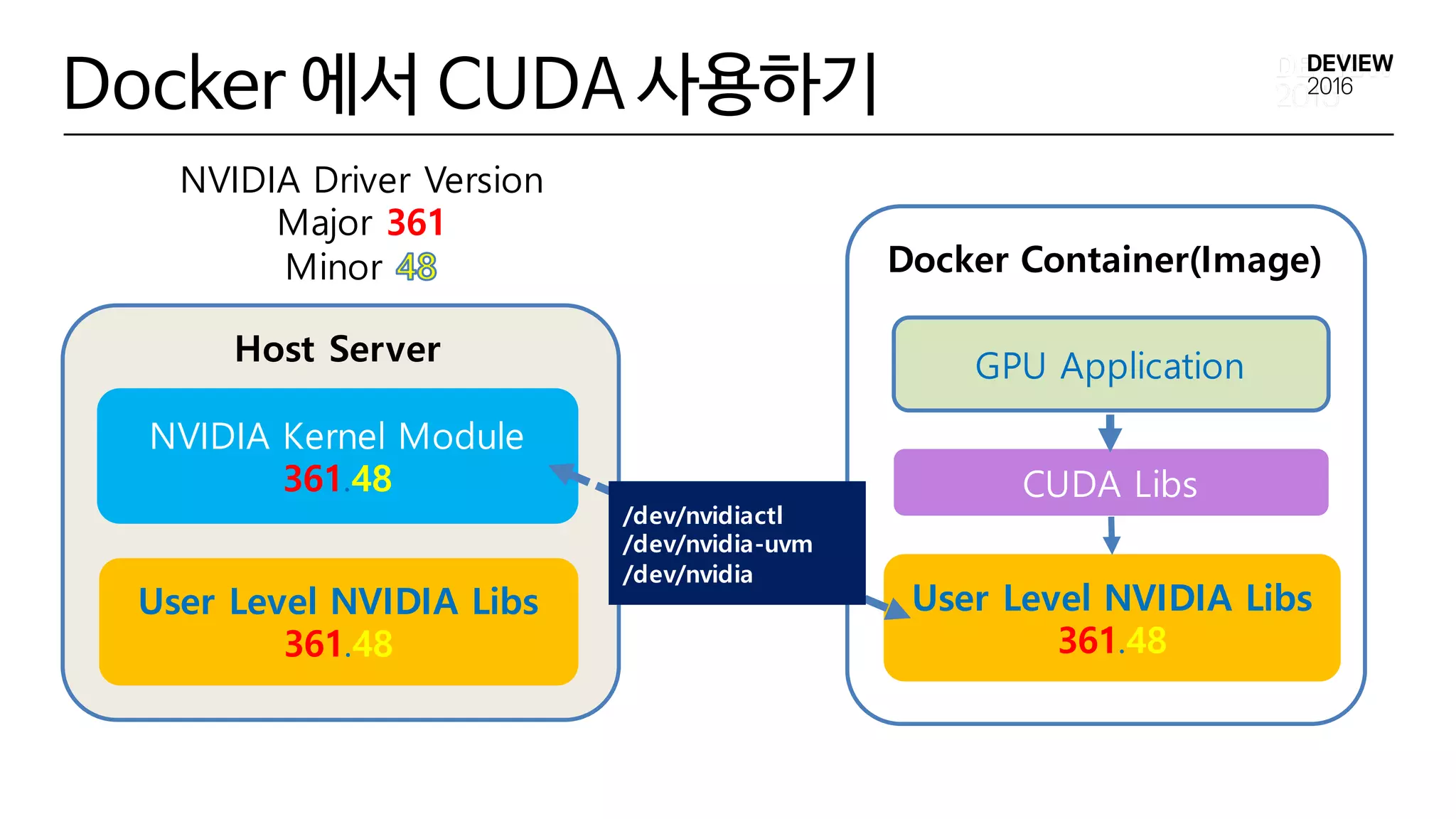
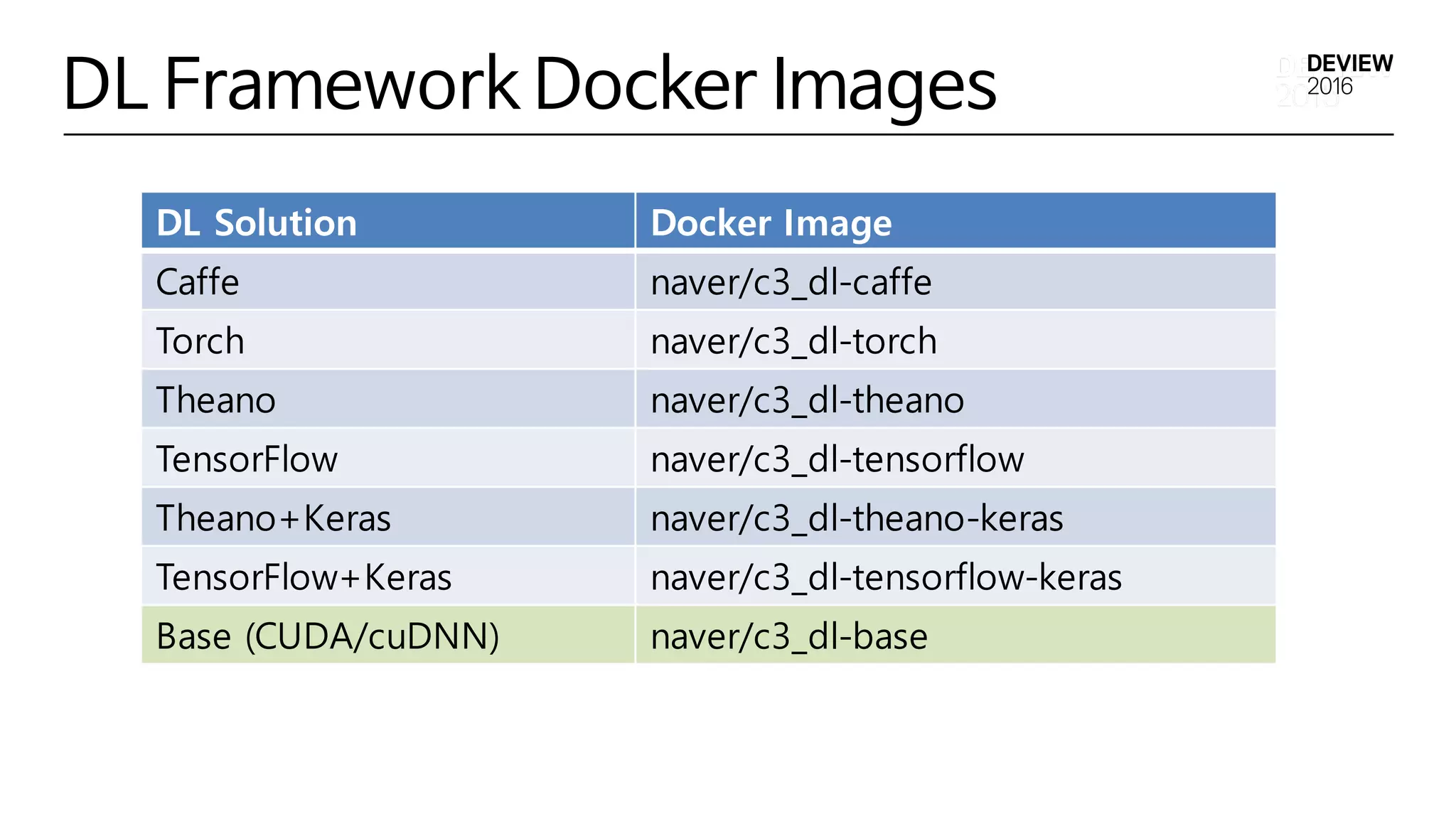
Docker 에서 CUDA사용하기
• Docker Image에 NVIDIA User Level Libraries 와 CUDA
Library 를 설치
• 제약 : Host에 설치된 NVIDIA Driver Major,Minor Version과 일치 해
야함
• Docker 실행시 NVIDIA Device File 들을 Docker에 노출
$ docker run …
--device=/dev/nvidiactl
--device=/dev/nvidia-uvm
--device=/dev/nvidia
38.
Docker 에서 CUDA사용하기
Host Server
NVIDIA Kernel Module
361.48
User Level NVIDIA Libs
361.48
NVIDIA Driver Version
Major 361
Minor Docker Container(Image)
User Level NVIDIA Libs
361.48
GPU Application
CUDA Libs
/dev/nvidiactl
/dev/nvidia-uvm
/dev/nvidia
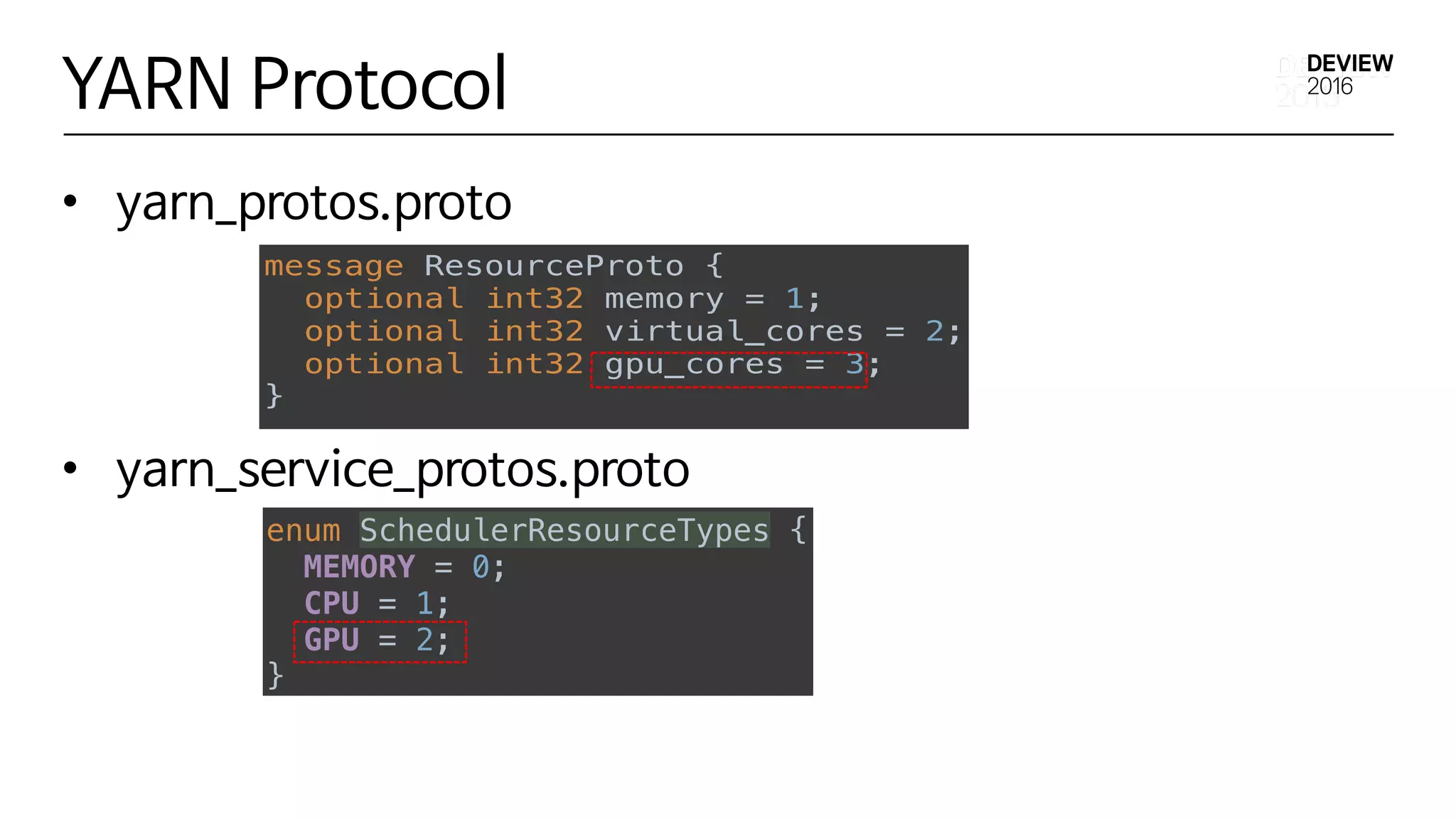
YARN Configuration
• org.apache.hadoop.yarn.conf.YarnConfiguration
ImplementationDetails
• org.apache.hadoop.yarn.conf.YarnConfiguration
public static final String RM_SCHEDULER_MINIMUM_ALLOCATION_GCORES =
YARN_PREFIX + "scheduler.minimum-allocation-gcores";
public static final int DEFAULT_RM_SCHEDULER_MINIMUM_ALLOCATION_GCORES = 0;
public static final String RM_SCHEDULER_MAXIMUM_ALLOCATION_GCORES =
YARN_PREFIX + "scheduler.maximum-allocation-gcores";
public static final int DEFAULT_RM_SCHEDULER_MAXIMUM_ALLOCATION_GCORES = 8;
public static final String NM_GCORES = NM_PREFIX + "resource.gcores";
public static final int DEFAULT_NM_GCORES = 0;
51.
Resource 객체
• org.apache.hadoop.yarn.util.resource.Resource
ImplementationDetails
• org.apache.hadoop.yarn.util.resource.Resources
public static Resource createResource(int memory) {
return createResource(memory, (memory > 0) ? 1 : 0, 0);
}
public static Resource createResource(int memory, int cores) {
return createResource(memory, cores, 0);
}
public static Resource createResource(int memory, int cores, int gcores) {
Resource resource = Records.newRecord(Resource.class);
resource.setMemory(memory);
resource.setVirtualCores(cores);
resource.setGpuCores(gcores);
return resource;
}
public int getGpuCores() { return 0; }
public void setGpuCores(int gcores) { throw new RuntimeException("NONE cannot be modified!"); }
public int compareTo(Resource o) {
int diff = 0 - o.getMemory();
if (diff == 0) {
diff = 0 - o.getVirtualCores();
if (diff == 0) {
diff = 0 - o.getGpuCores();
}
}
return diff;
}
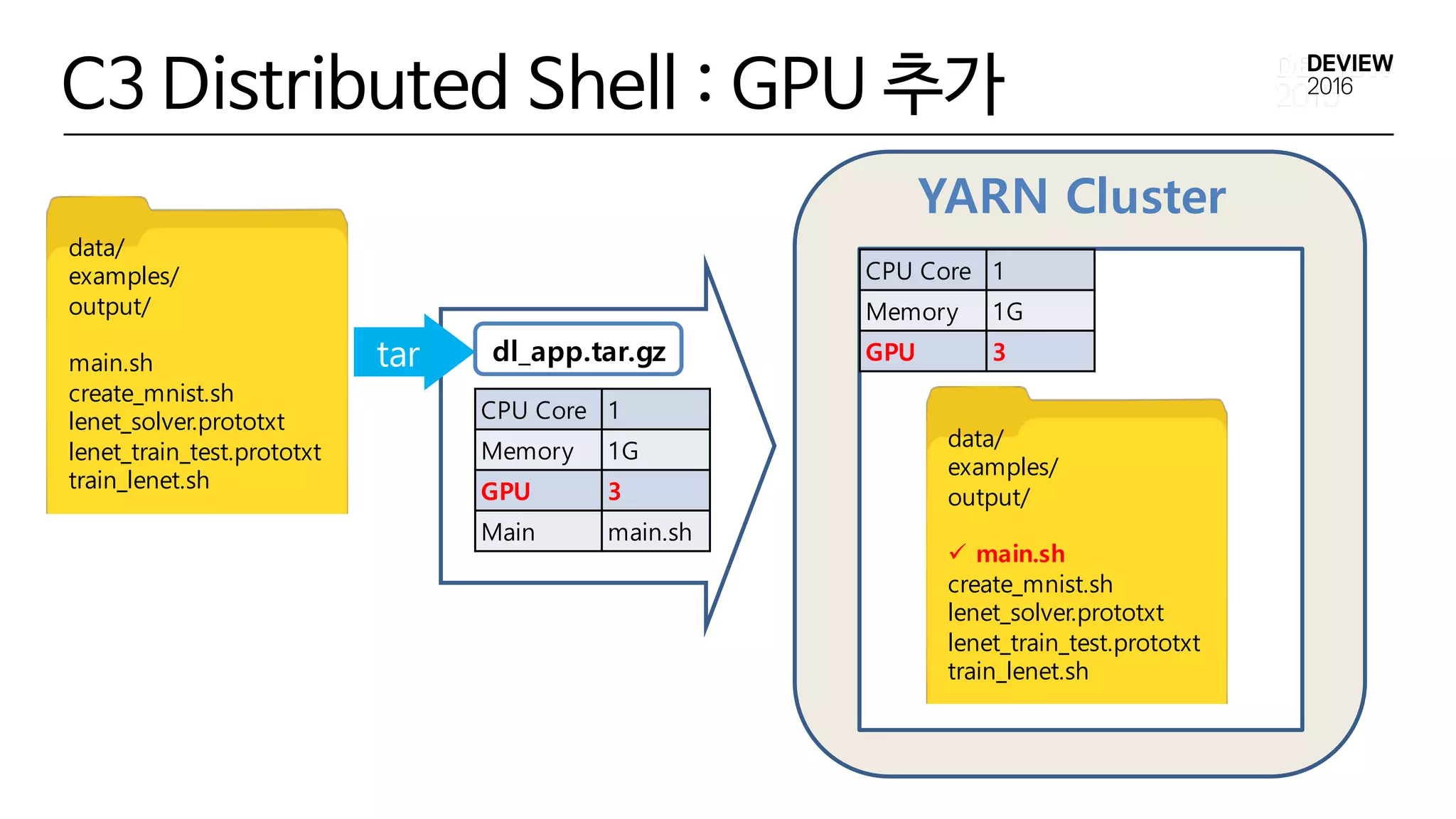
YARN Cluster
CPU Core1
Memory 1G
GPU 3
Main main.sh
tar dl_app.tar.gz
data/
examples/
output/
main.sh
create_mnist.sh
lenet_solver.prototxt
lenet_train_test.prototxt
train_lenet.sh
data/
examples/
output/
ü main.sh
create_mnist.sh
lenet_solver.prototxt
lenet_train_test.prototxt
train_lenet.sh
CPU Core 1
Memory 1G
GPU 3
C3 Distributed Shell : GPU 추가
55.
Technical Issues
ü YARNCluster에서 Shell Script Application 실행
ü 다양한 Deep Learning Framework 환경 제공
ü YARN Cluster에서 GPU Resource Scheduling
è C3 Distributed Shell
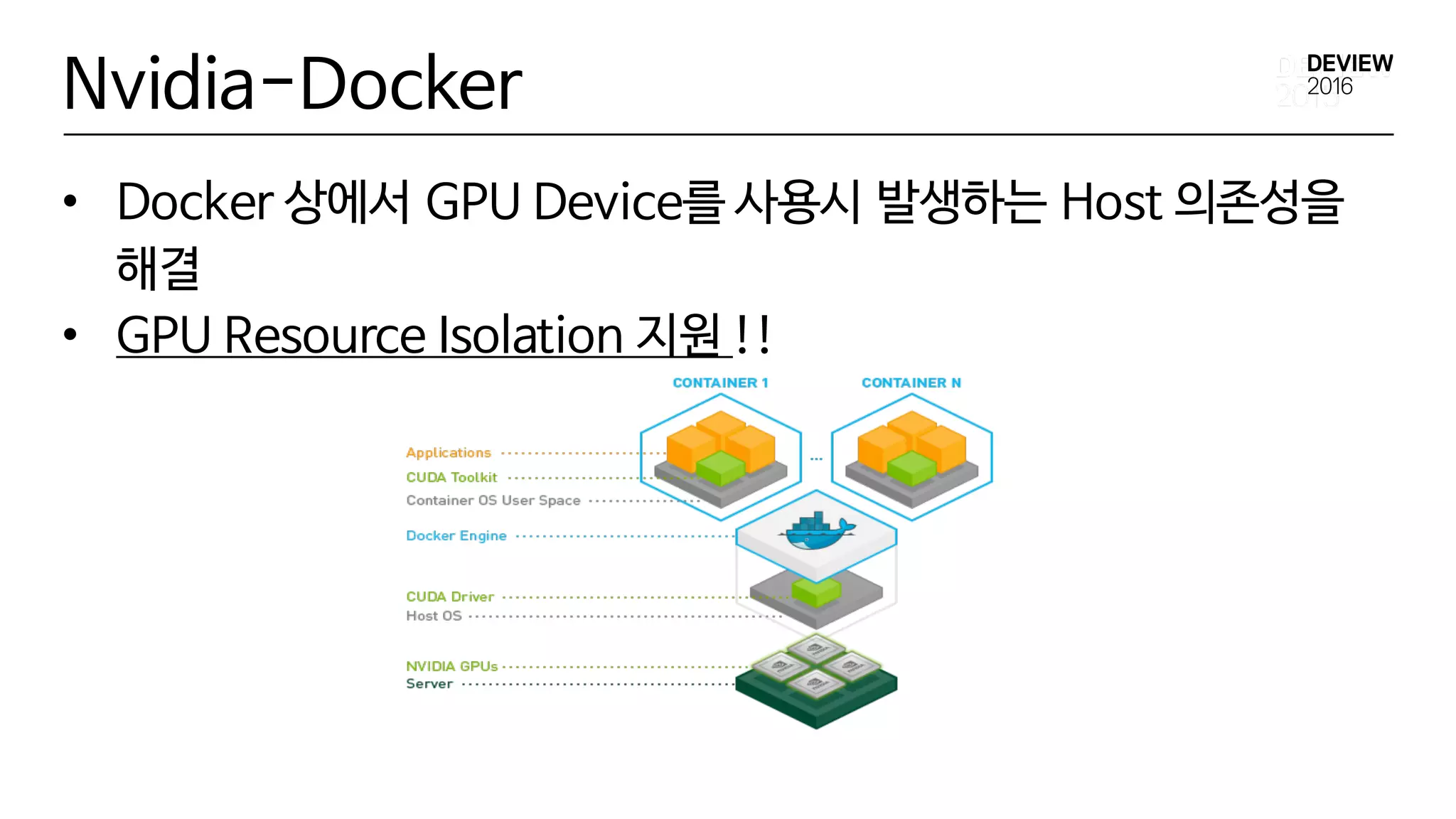
è Nvidia-Docker
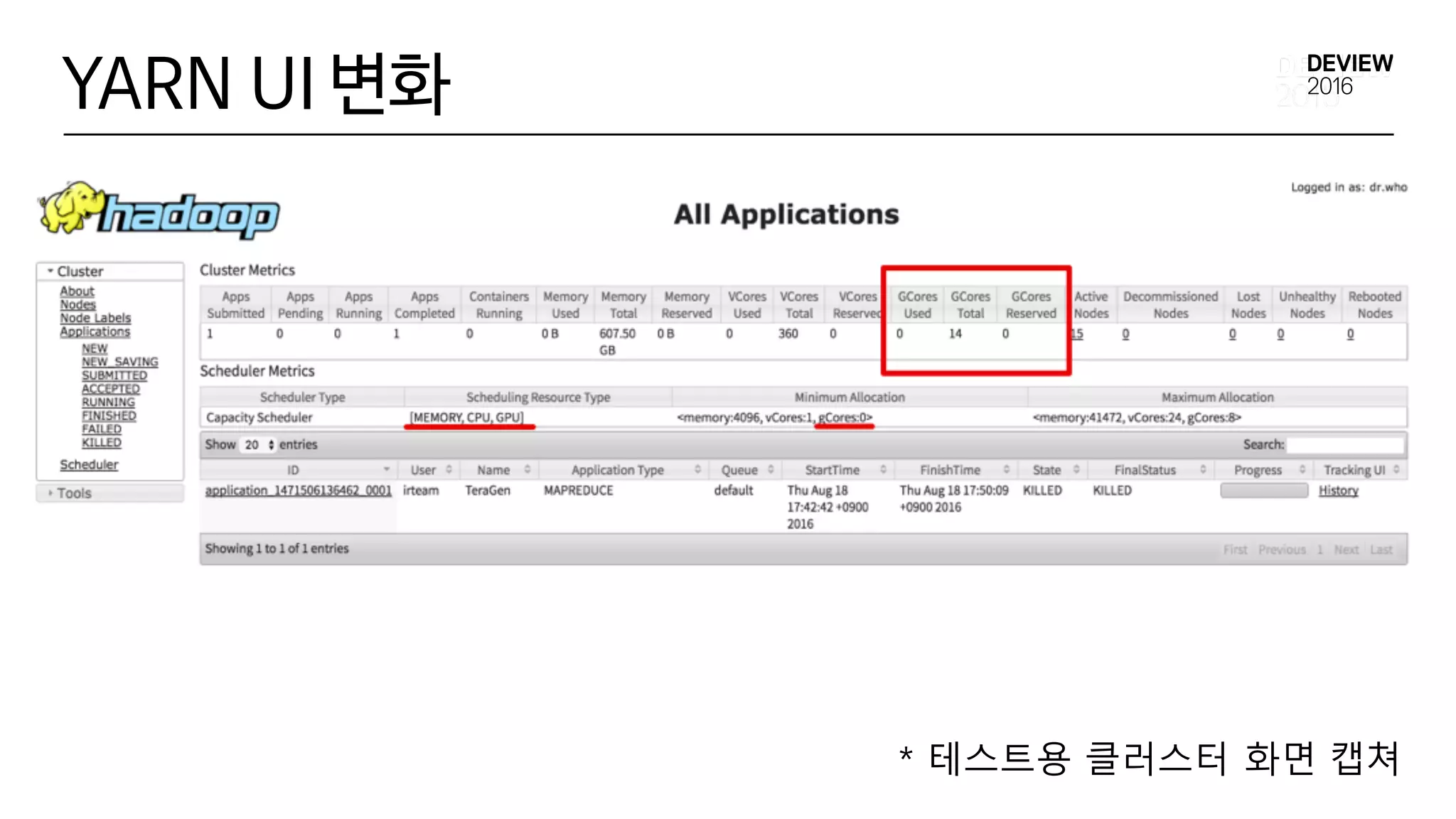
è YARN with GPU Scheduling 개발
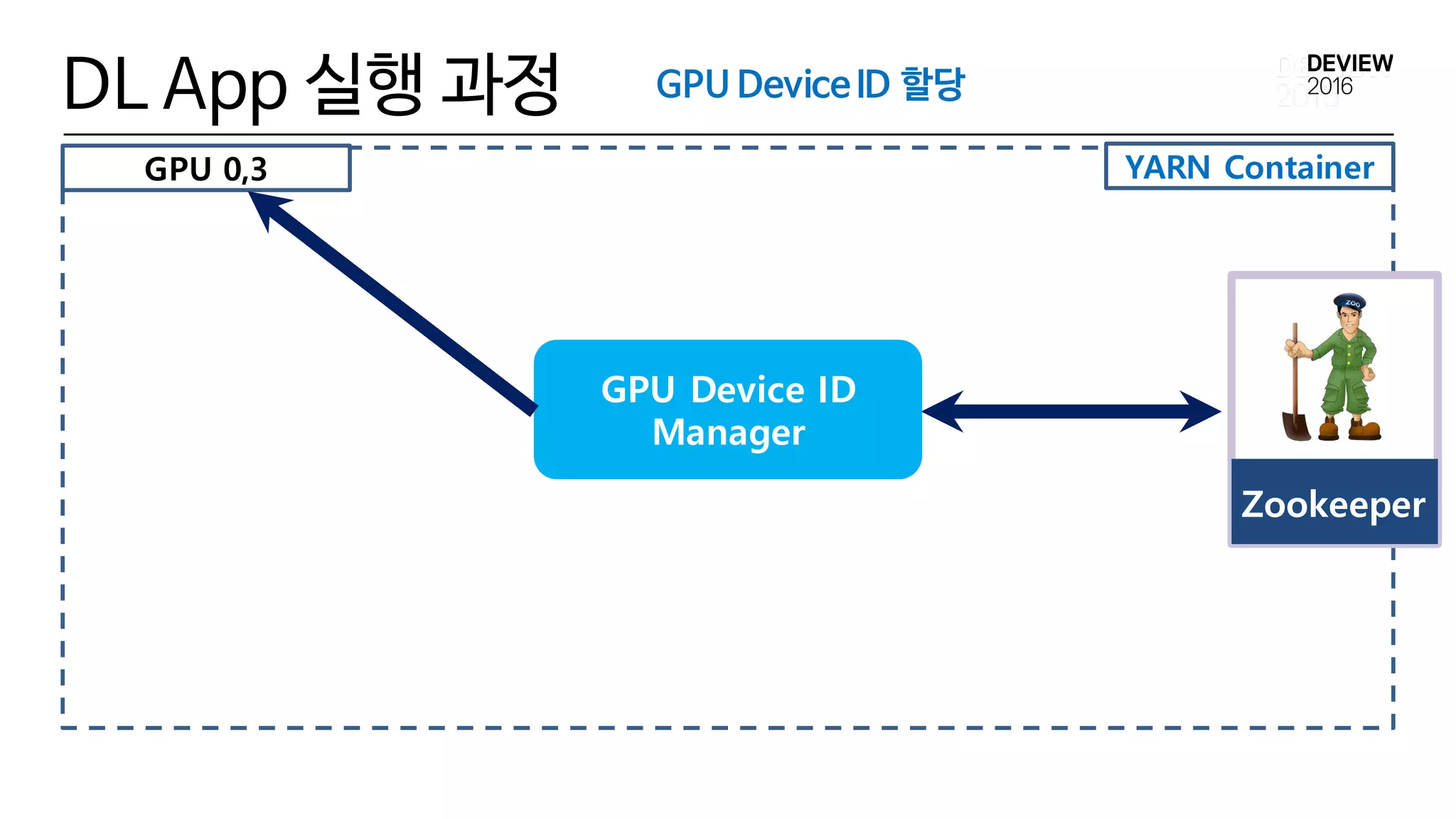
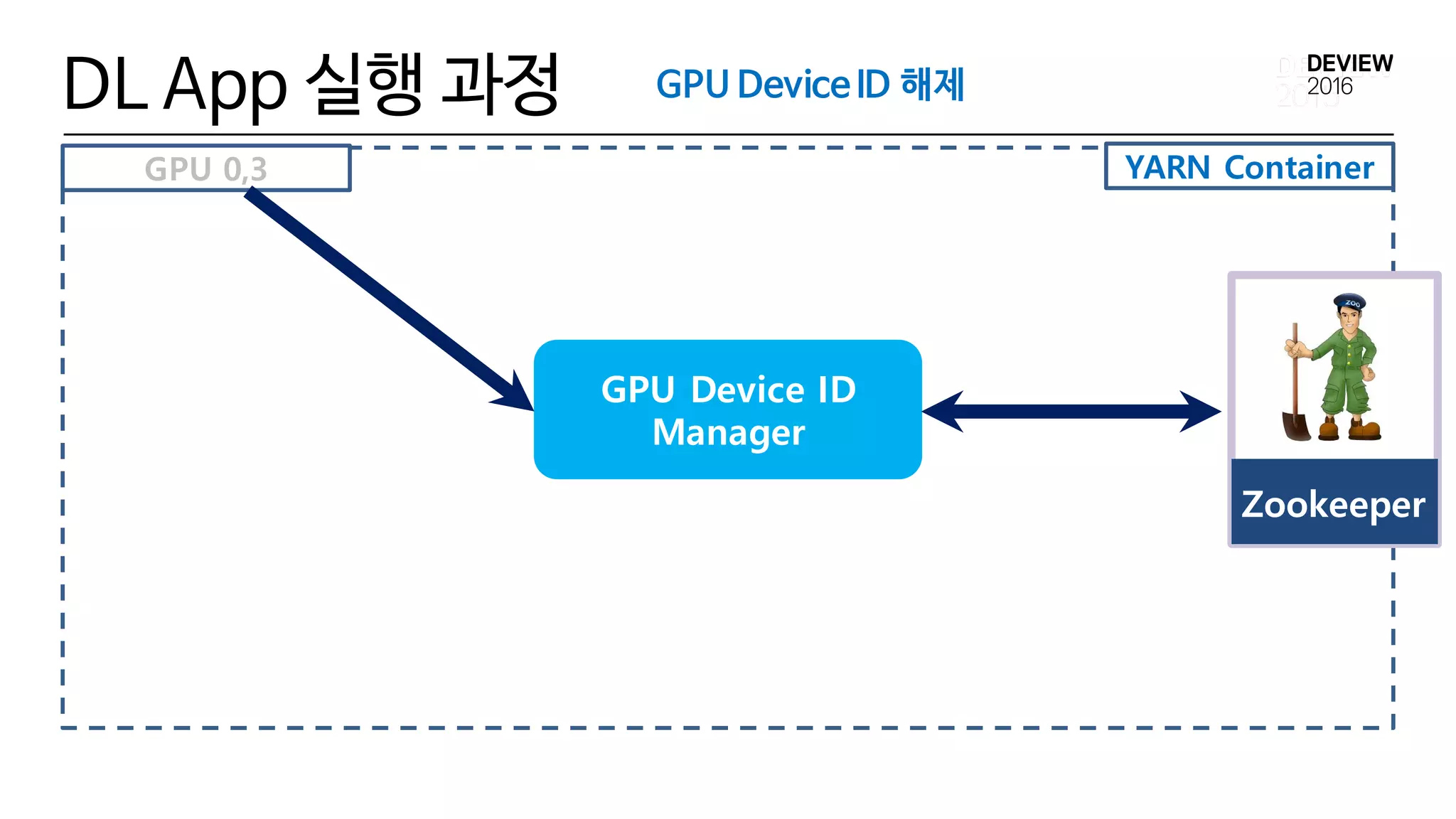
GPU Device IDManager
• Cluster 전체의 GPU Device ID Allocation 정보를 Zookeeper
를 통해 관리
• GPU Device ID Manager
• python kazoo lib
• 분산 Lock
• GPU Device ID 할당/해제
• Garbage Collection
{
”host01": {
"gpu0": "application_id_01",
"gpu1": “application_id_01”,
"gpu2": “application_id_02”,
"gpu3": “application_id_03”
},
“host02": {
"gpu0": “application_id_04",
…
},
…
}
60.
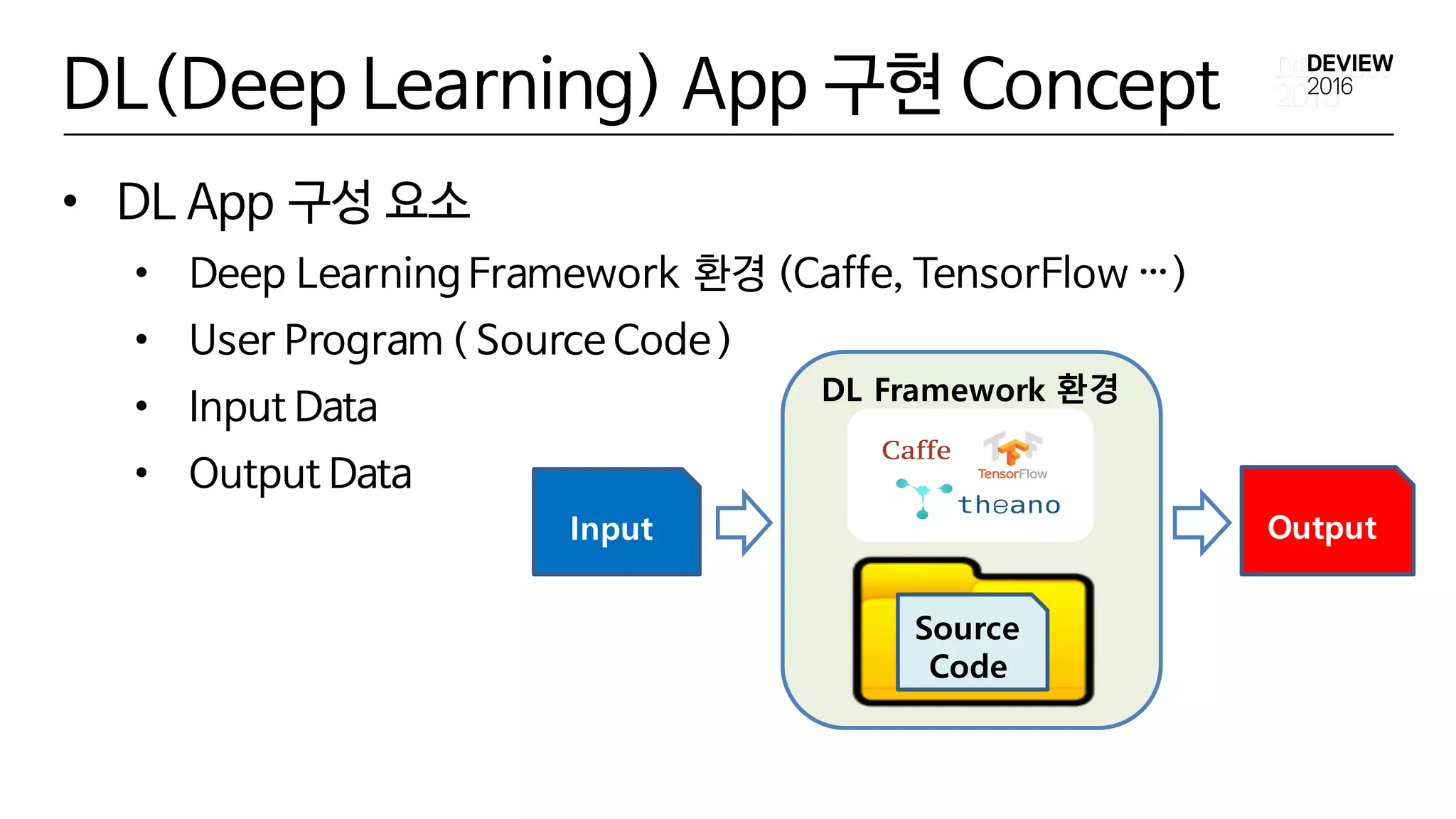
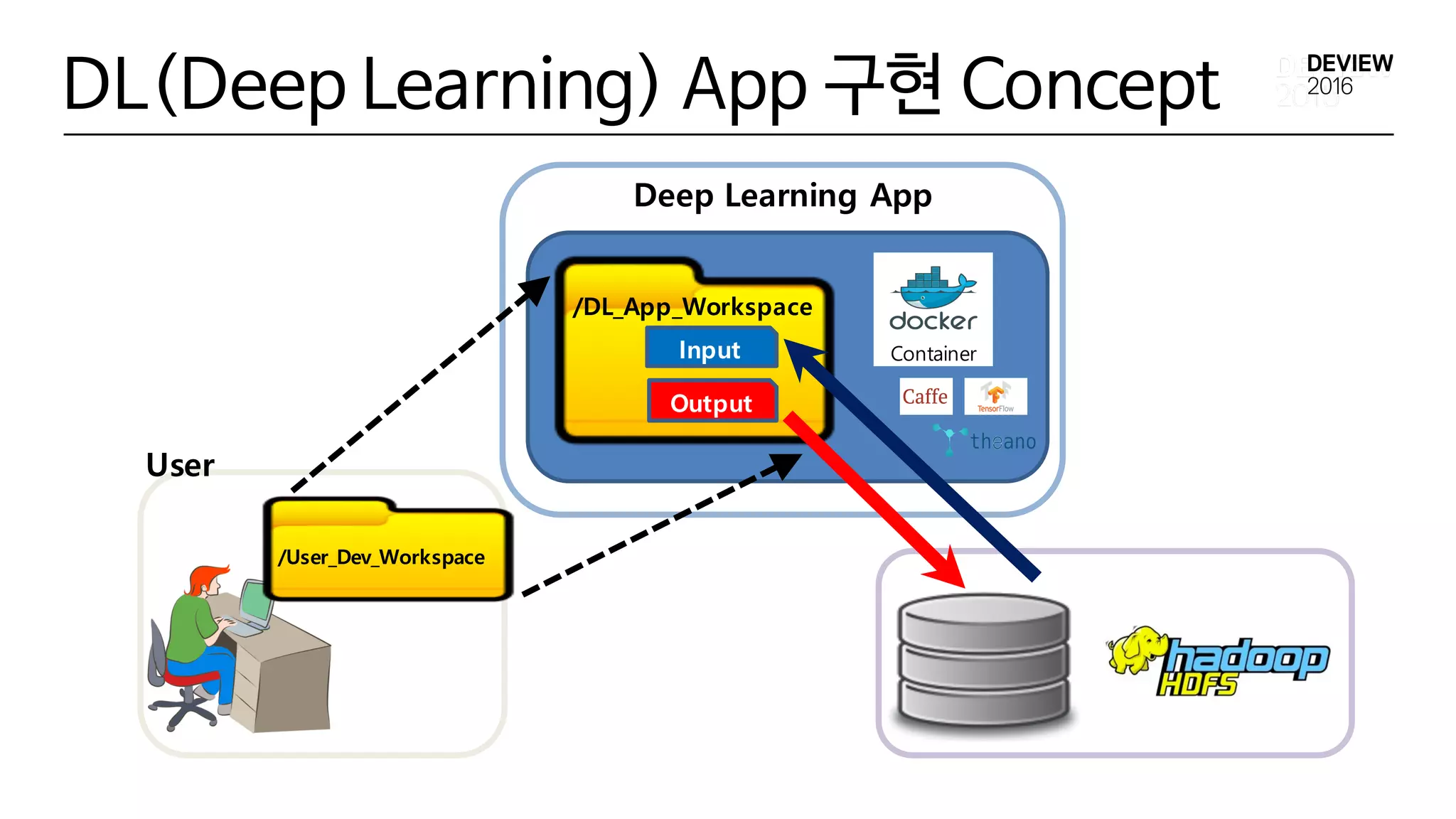
DL(Deep Learning) App구현 Concept
• DL App 구성 요소
• Deep Learning Framework 환경 (Caffe, TensorFlow …)
• User Program ( Source Code)
• Input Data
• Output Data
Input Output
DL Framework 환경
Source
Code
61.
YARN Cluster
CPU Core1
Memory 1G
GPU 3
Main main.sh
tar dl_app.tar.gz
data/
examples/
output/
main.sh
create_mnist.sh
lenet_solver.prototxt
lenet_train_test.prototxt
train_lenet.sh
data/
examples/
output/
ü main.sh
create_mnist.sh
lenet_solver.prototxt
lenet_train_test.prototxt
train_lenet.sh
CPU Core 1
Memory 1G
GPU 3
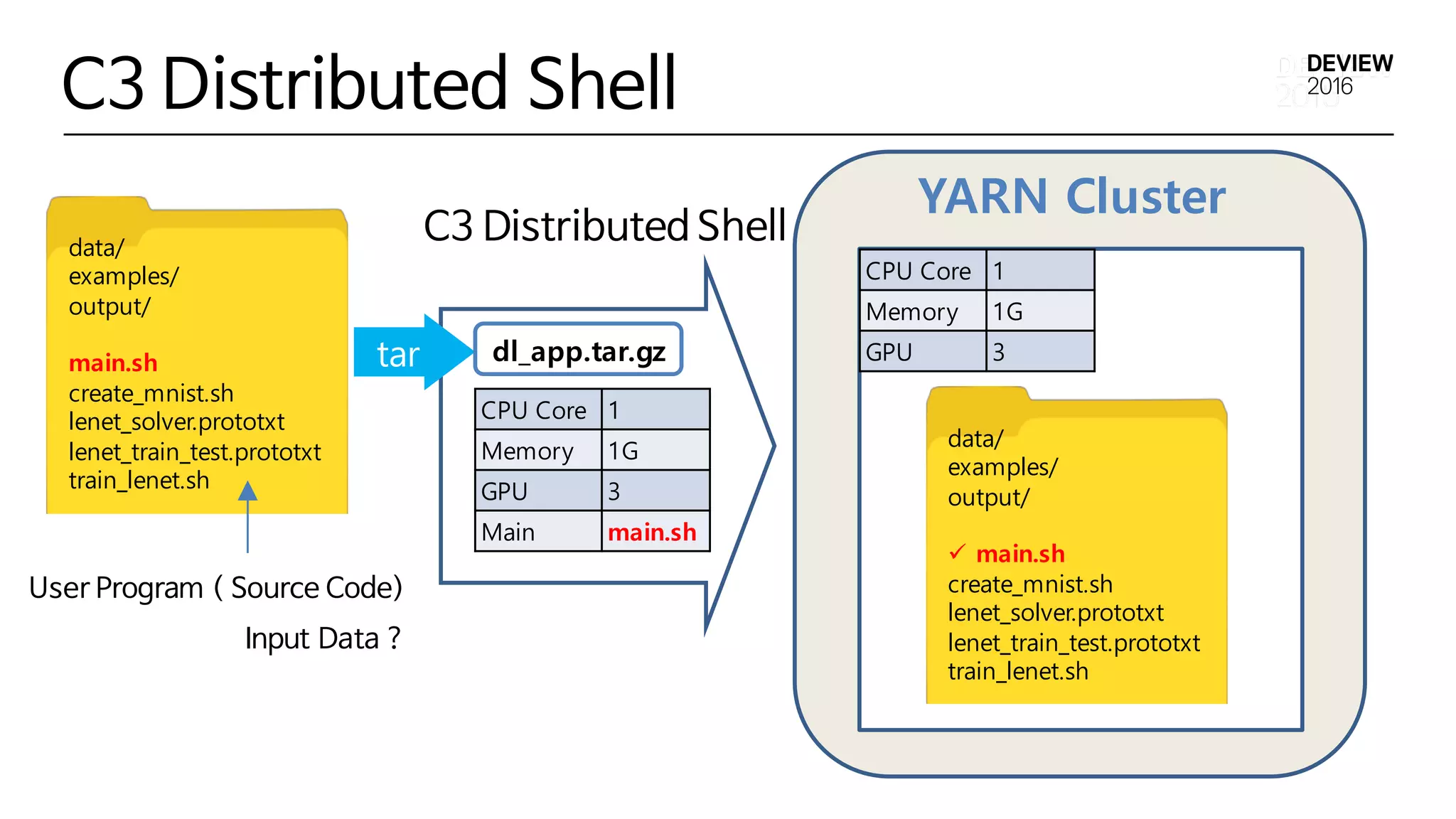
C3 Distributed Shell
C3 Distributed Shell
User Program ( Source Code)
Input Data ?
62.
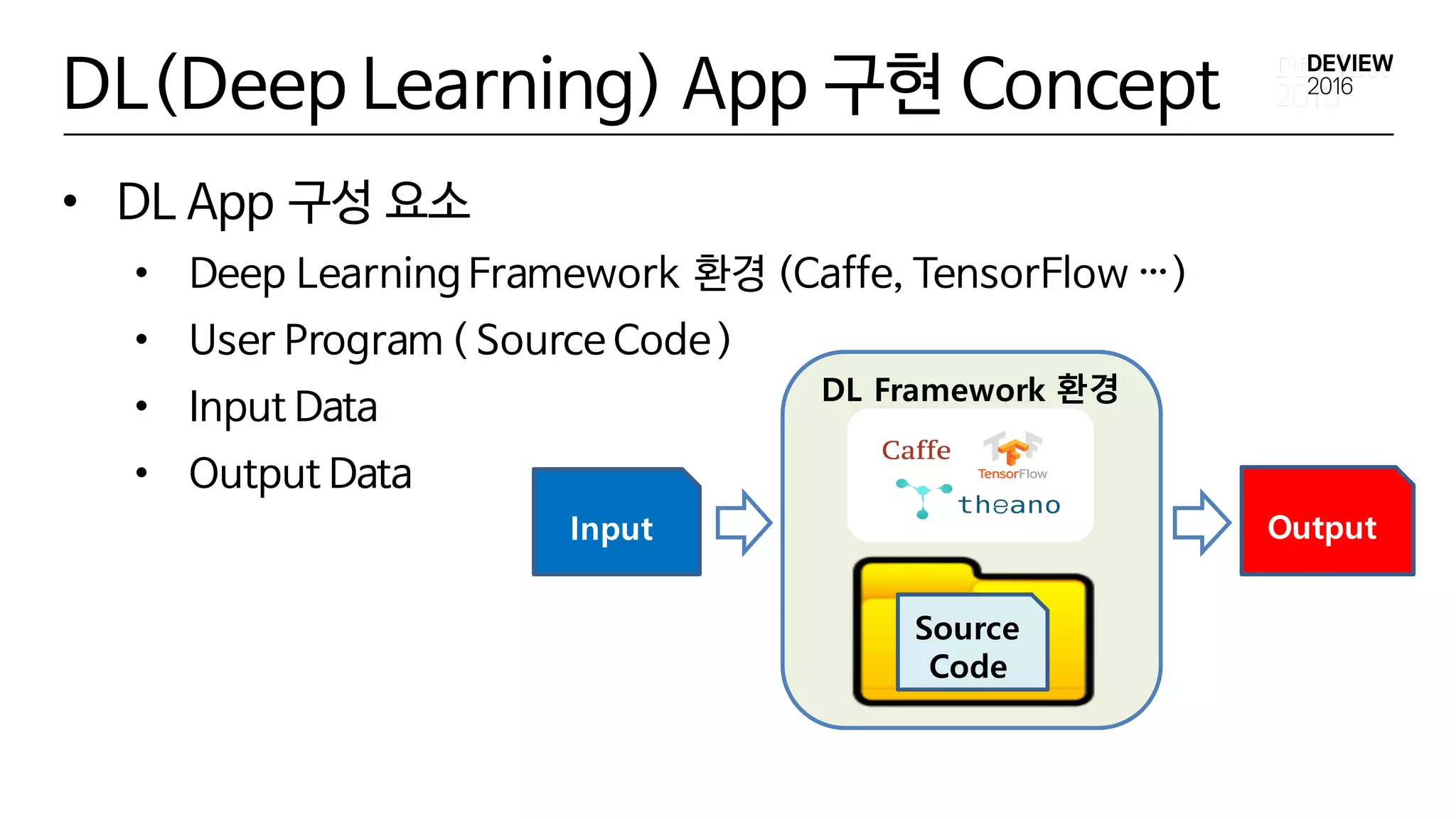
DL(Deep Learning) App구현 Concept
• DL App 구성 요소
• Deep Learning Framework 환경 (Caffe, TensorFlow …)
• User Program ( Source Code)
• Input Data
• Output Data
Input Output
DL Framework 환경
Source
Code
63.
DL(Deep Learning) App구현 Concept
• Input/Output Data
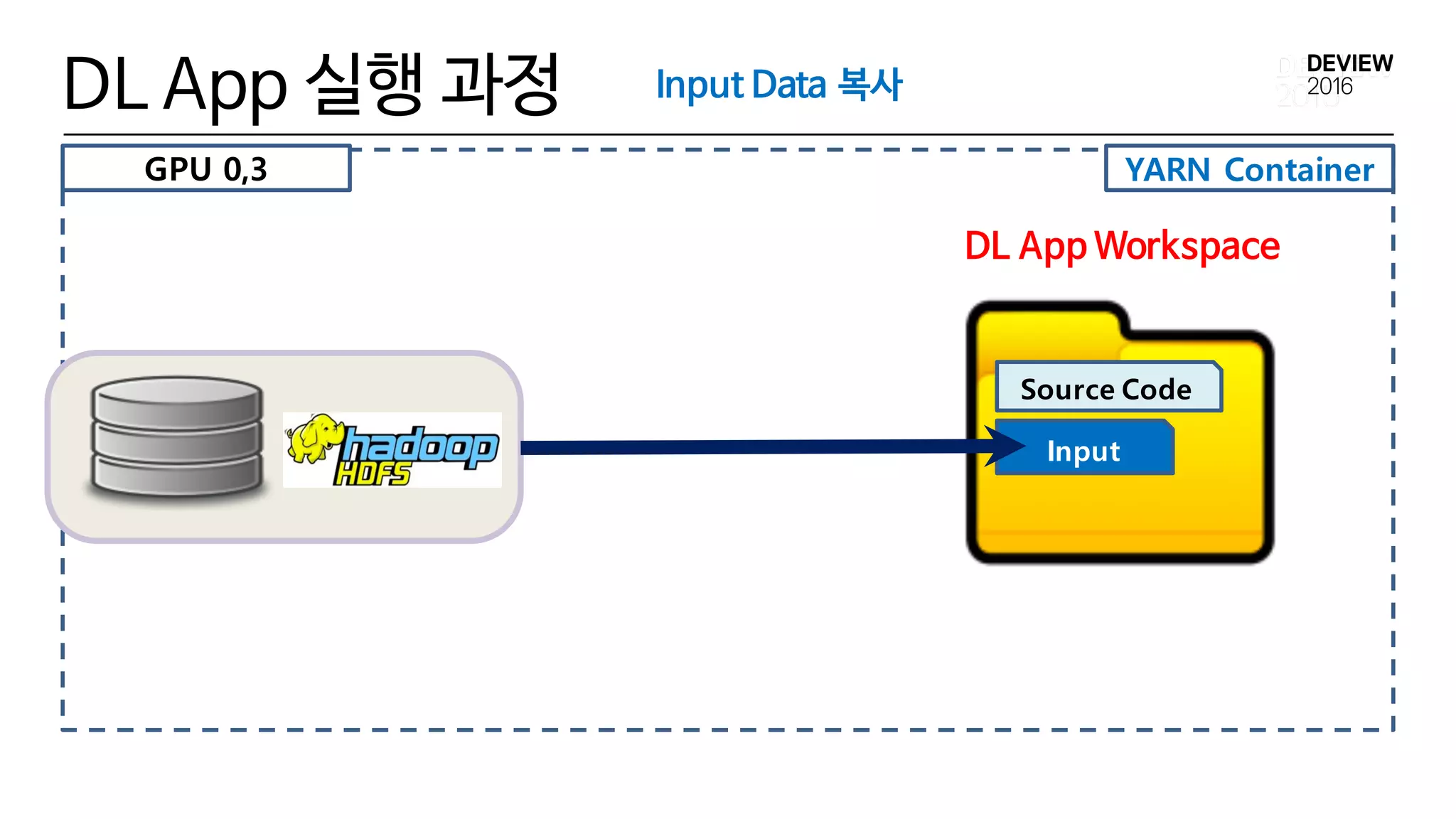
• Data Repository Tech.
• NFS
• Ceph, GlusterFS, Lustre
ü HDFS
• C3 HDFS Storage를 저장소로 사용
64.
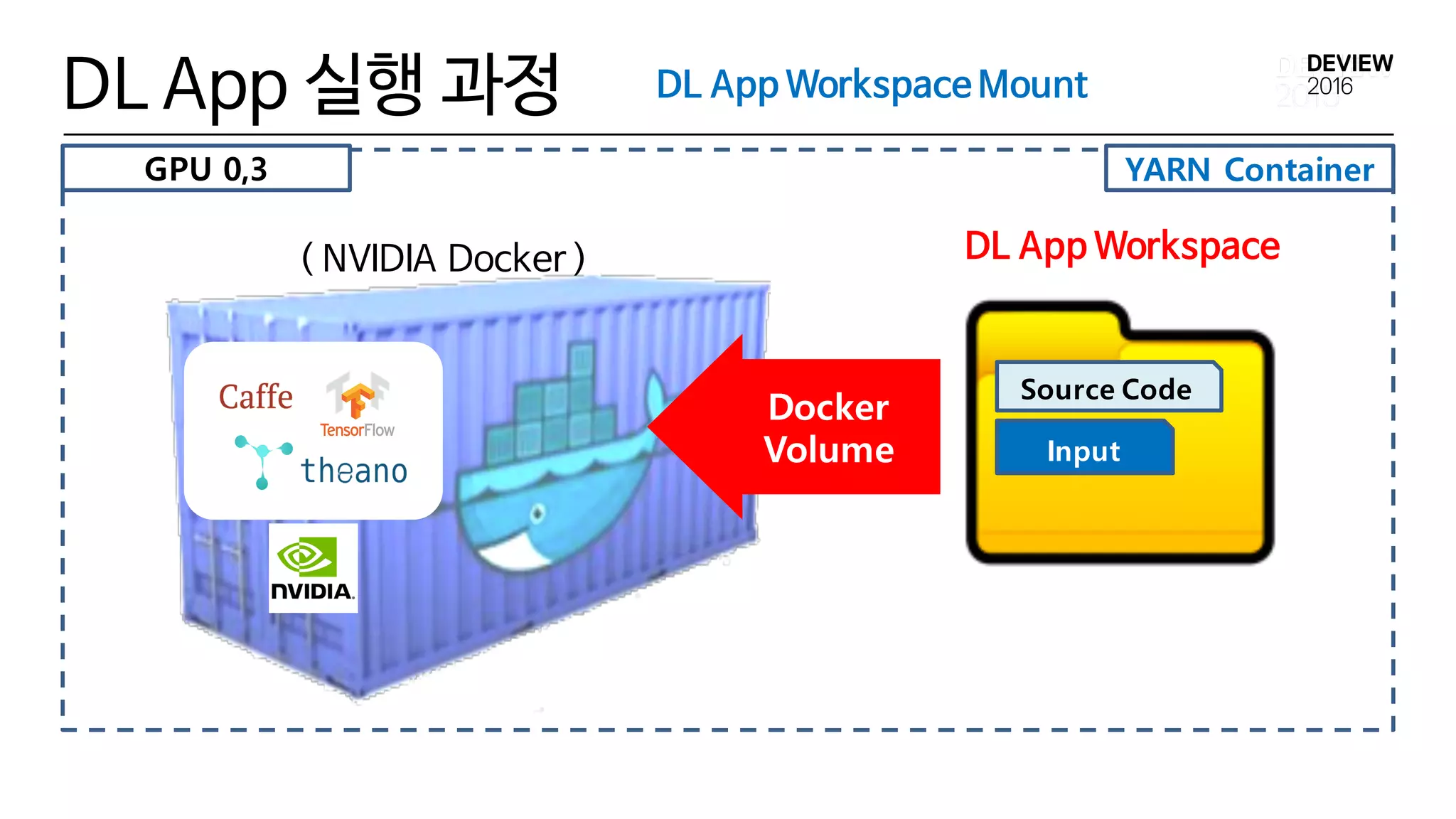
DL(Deep Learning) App구현 Concept
• Docker Container의 데이터는 volatile함
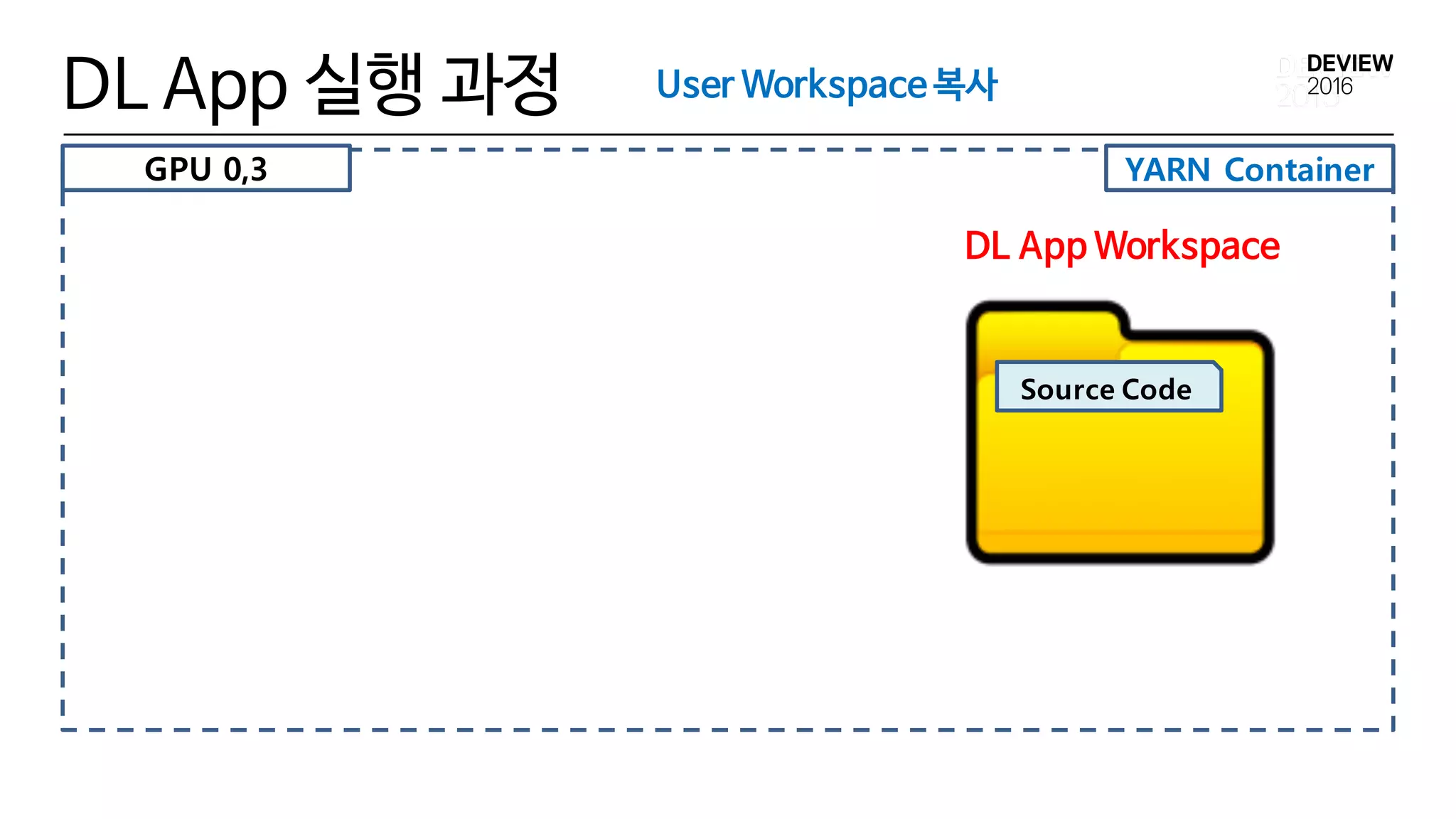
• Docker Container안에 permanent한 작업 영역(dir)이 필요함
• DL App Workspace (Directory)
• DL App 실행을 위한 File/Dir들이 존재하는 영역
• User Program Src Code, Input/OutputData 들이 위치함
• Host Server상의 Directory이며 , Docker Container에 volumemount
되는 영역
65.
DL(Deep Learning) App구현 Concept
/User_Dev_Workspace
/DL_App_Workspace
Deep Learning App
Input
Output
User
Container
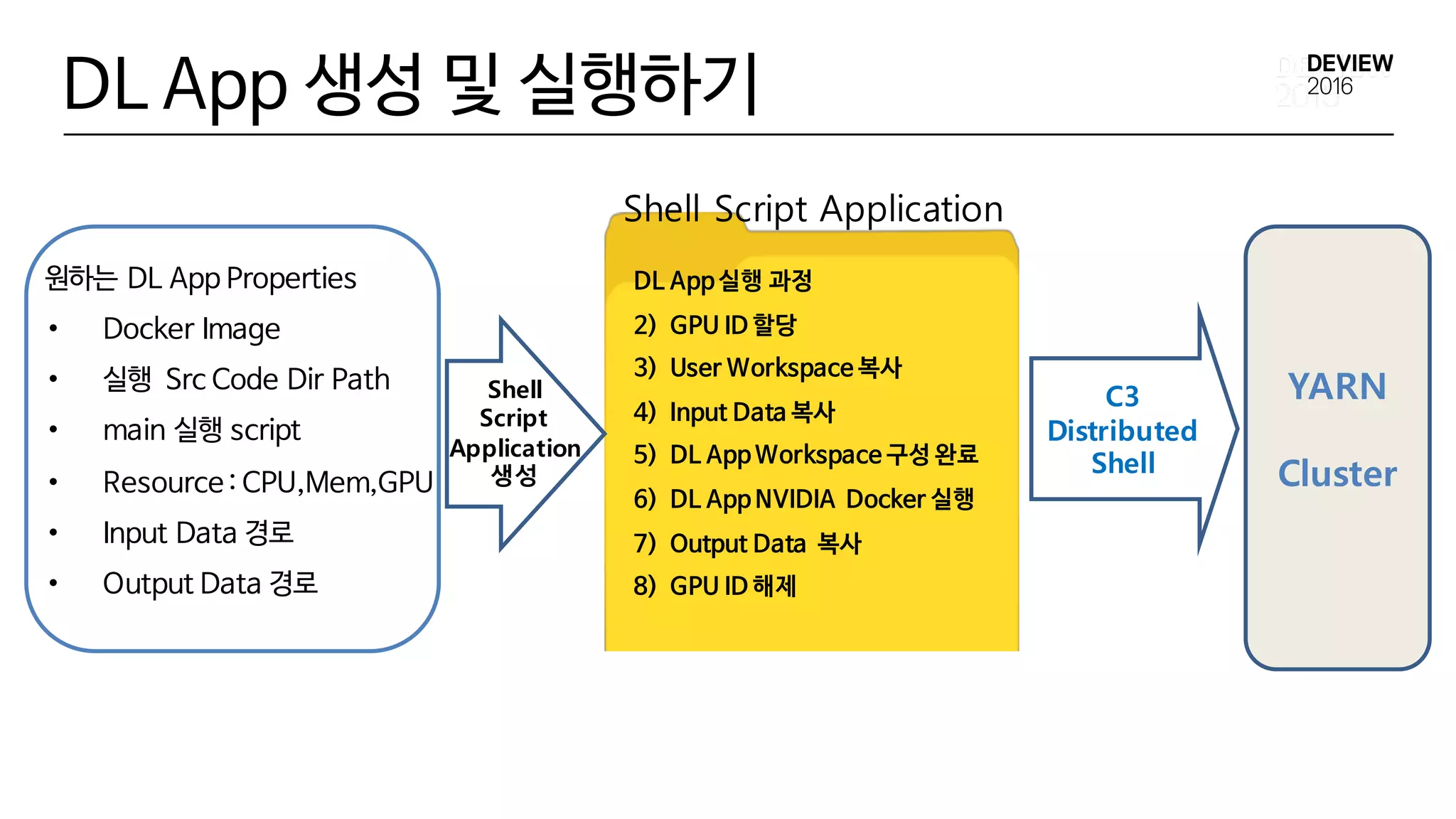
원하는 DL AppProperties
• Docker Image
• 실행 Src Code Dir Path
• main 실행 script
• Resource : CPU,Mem,GPU
• Input Data 경로
• Output Data 경로
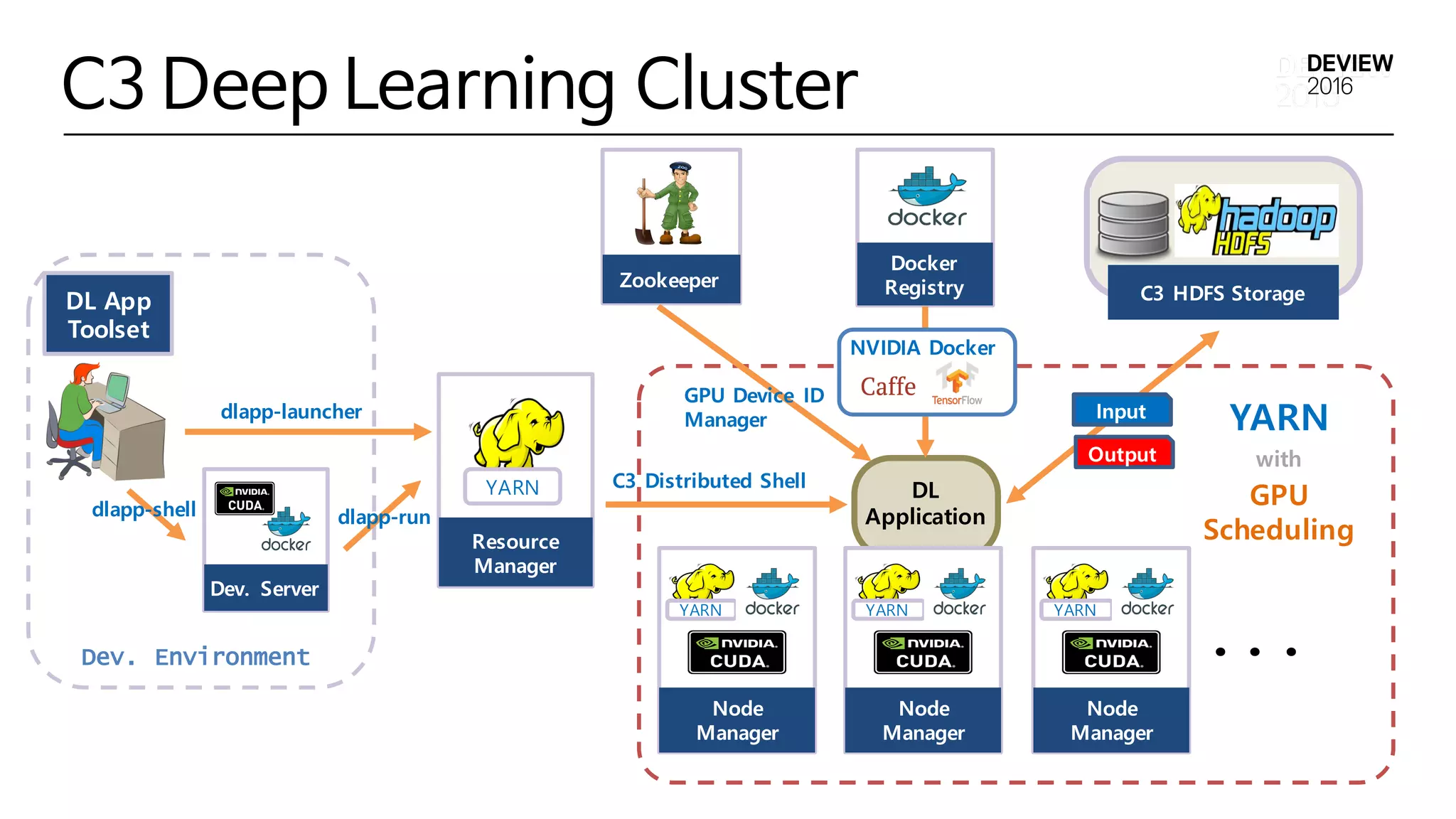
DL App 생성 및 실행하기
C3
Distributed
Shell
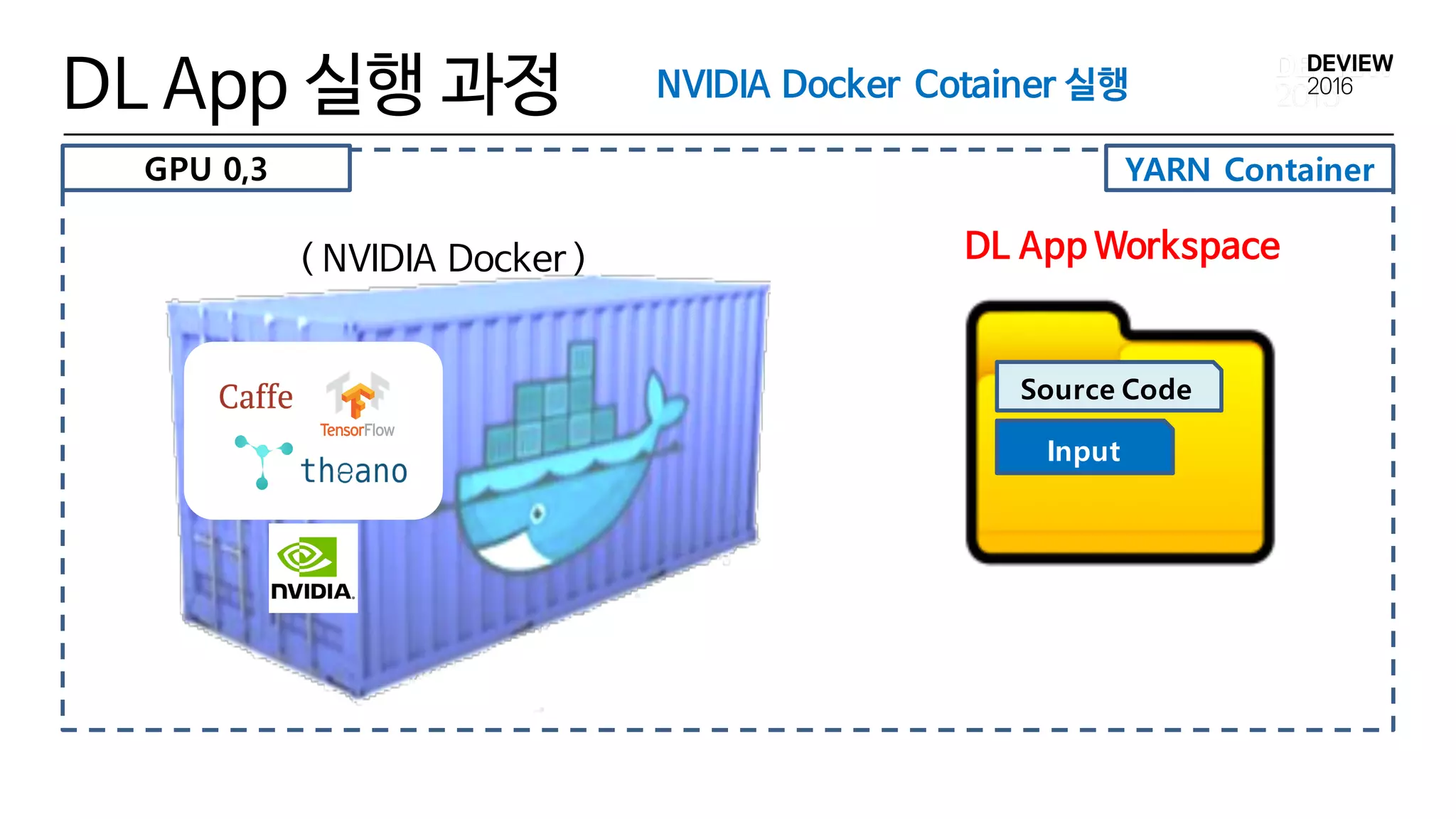
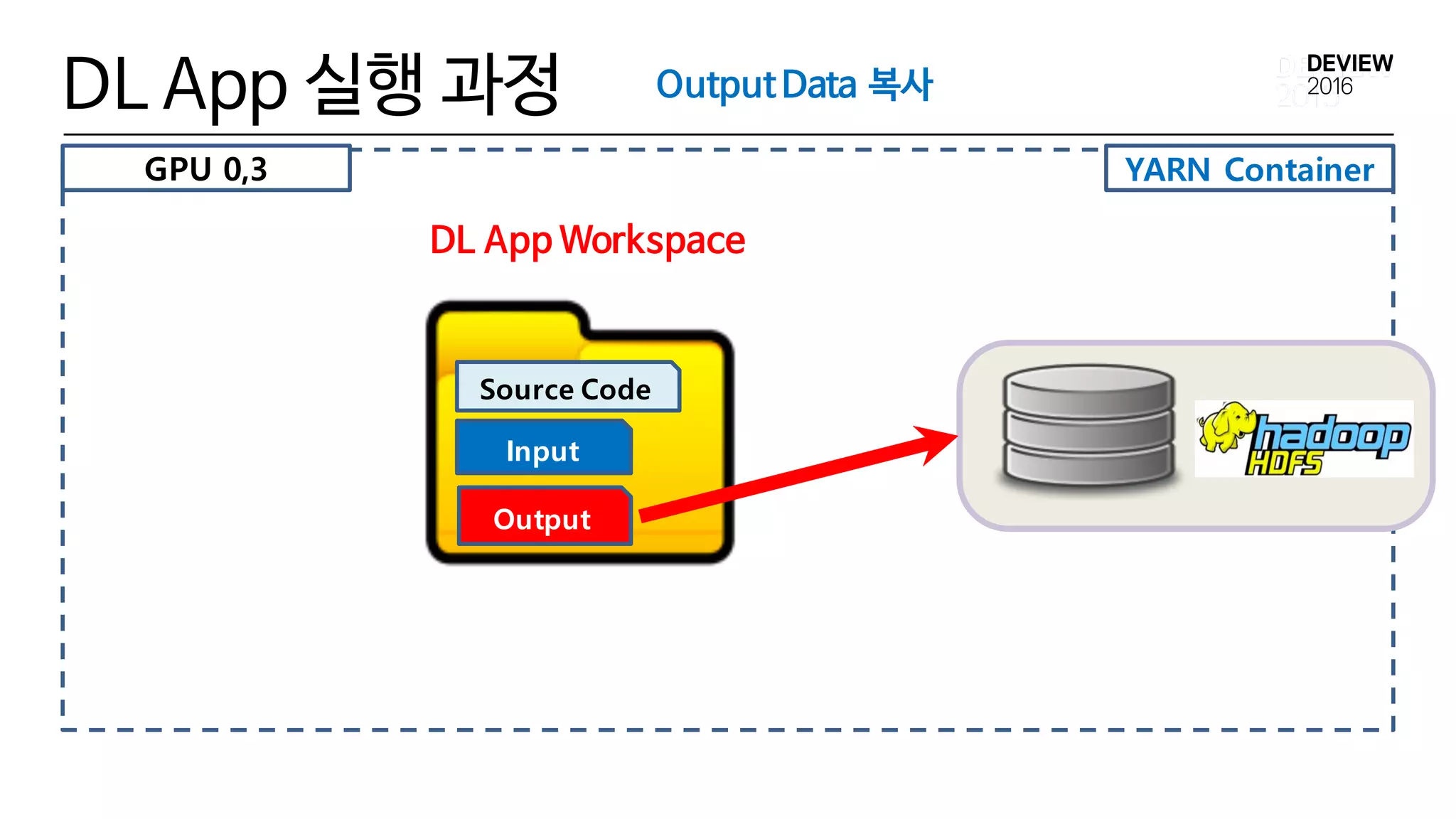
DL App 실행 과정
2) GPU ID 할당
3) User Workspace 복사
4) Input Data 복사
5) DL App Workspace 구성 완료
6) DL App NVIDIA Docker 실행
7) Output Data 복사
8) GPU ID 해제
YARN
Cluster
Shell Script Application
Shell
Script
Application
생성
81.
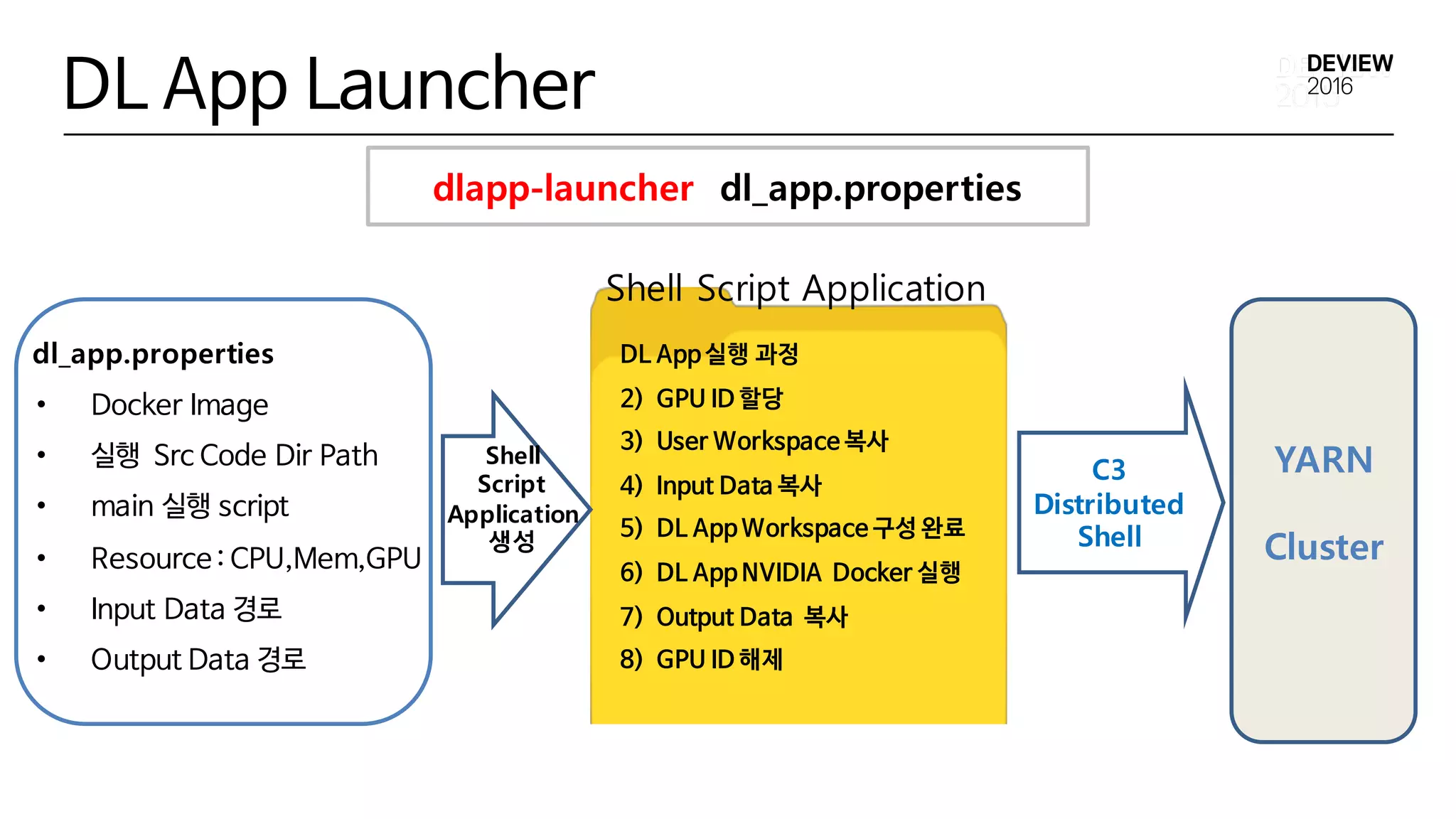
dl_app.properties
• Docker Image
•실행 Src Code Dir Path
• main 실행 script
• Resource : CPU,Mem,GPU
• Input Data 경로
• Output Data 경로
C3
Distributed
Shell
DL App 실행 과정
2) GPU ID 할당
3) User Workspace 복사
4) Input Data 복사
5) DL App Workspace 구성 완료
6) DL App NVIDIA Docker 실행
7) Output Data 복사
8) GPU ID 해제
YARN
Cluster
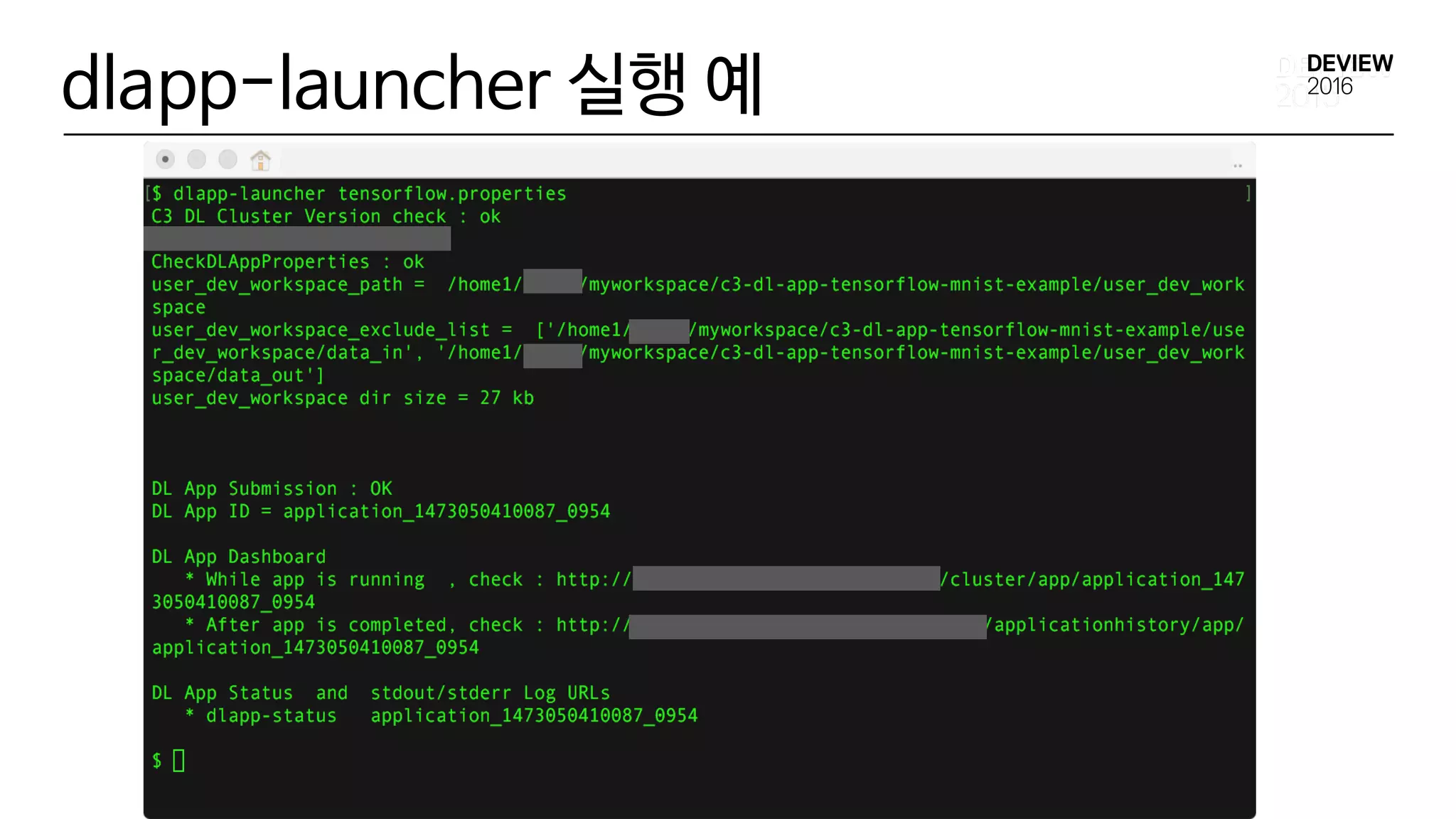
dlapp-launcher dl_app.properties
DL App Launcher
Shell Script Application
Shell
Script
Application
생성
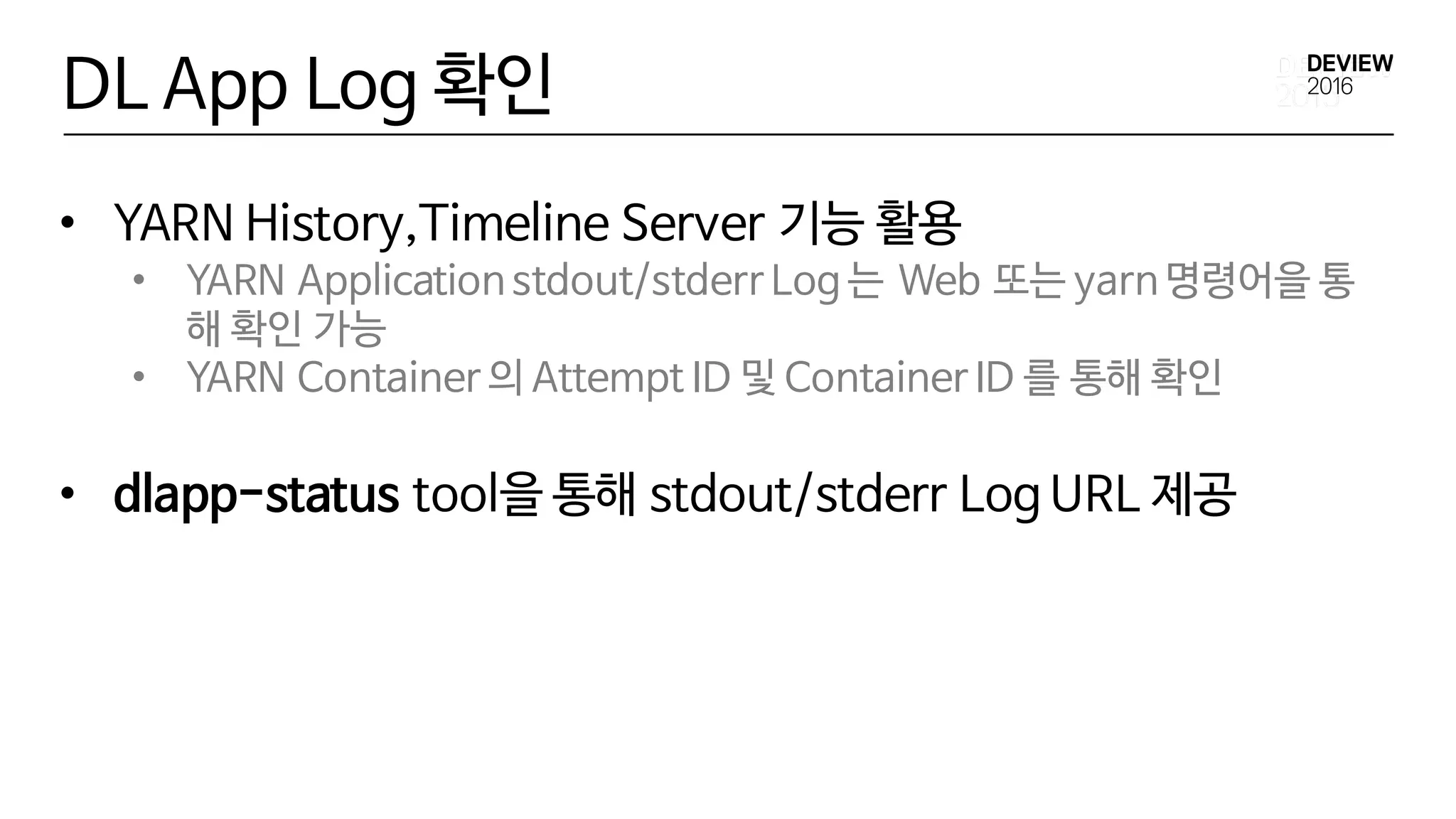
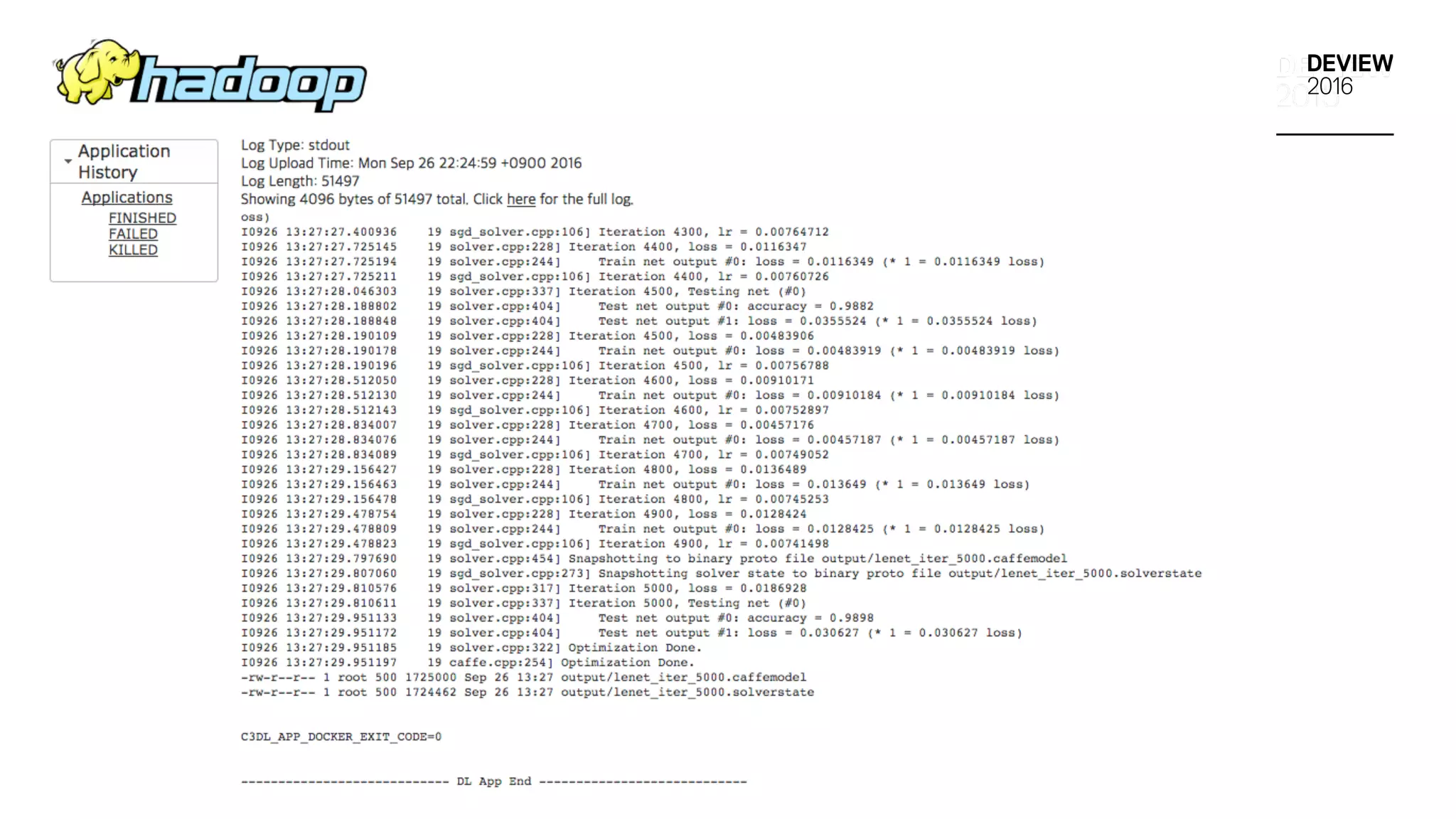
DL App Log확인
• YARN History,Timeline Server 기능 활용
• YARN Application stdout/stderr Log 는 Web 또는 yarn 명령어을 통
해 확인 가능
• YARN Container 의 Attempt ID 및 Container ID 를 통해 확인
• dlapp-status tool을 통해 stdout/stderr Log URL 제공
88.
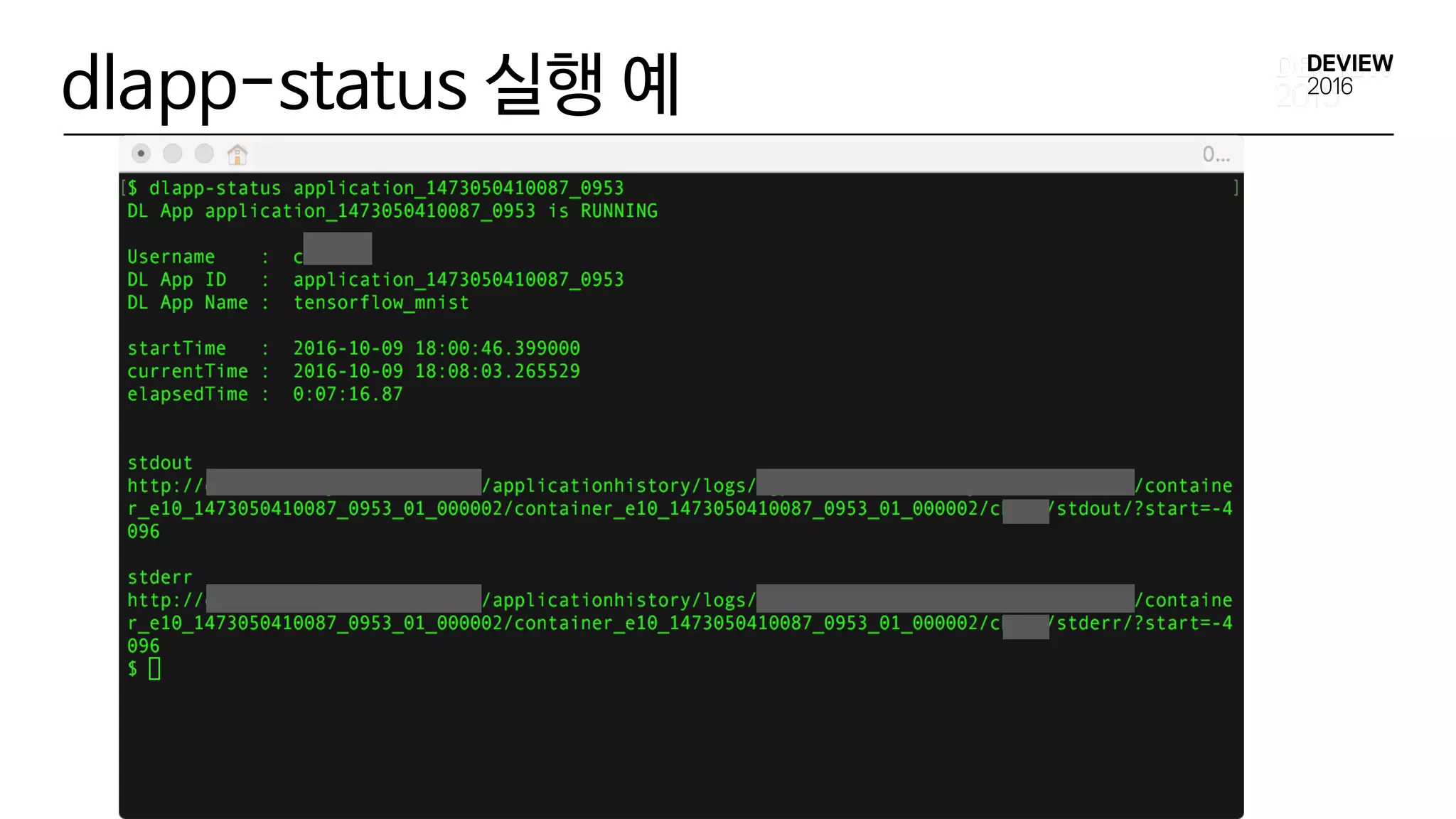
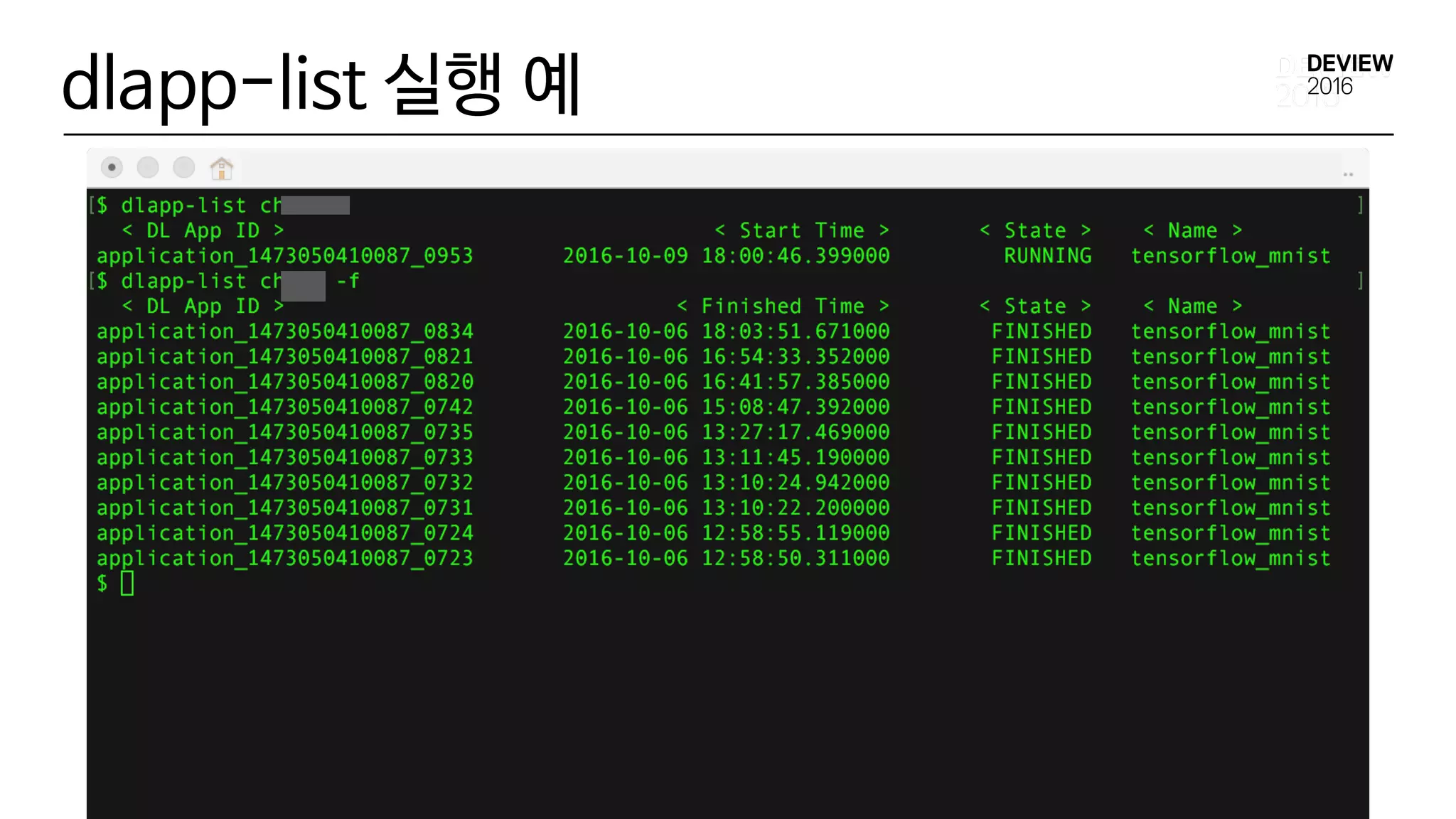
dlapp-status 실행 예
$dlapp-status application_aaaaaaaaaaa_bbbb
DL App application_aaaaaaaaaaa_bbbb is FINISHED
Username : tony
DL App ID : application_aaaaaaaaaaa_bbbb
DL App Name : 'c3 deeplearning app caffe mnist example'
startTime : 2016-09-26 22:24:11.575000
finishTime : 2016-09-26 22:24:57.703000
elapsedTime : 0:00:46.13
stdout
http://XXXXX/applicationhistory/logs/XXXXX/container_aaaaaaaaaaa_bbbb_01_000004/container_aaaaaaaaaaa_bbbb
_01_000004/tony/stdout/?start=-4096
stderr
http://XXXXX/applicationhistory/logs/XXXXX/container_aaaaaaaaaaa_bbbb_01_000004/container_aaaaaaaaaaa_bbbb
_01_000004/tony/stderr/?start=-4096
DL App Development환경의 필요성
• DL App을 개발하려면 GPU 장비가 필요함
• 초기 DL App개발 시점에서 기본적인 검증 용도로 DL Cluster를
이용하는 것은 매우 번거로움
• 코드의 사소한 실수를 수정하는 과정의 반복
• Input/outputData등의 Directory 구조 확인
94.
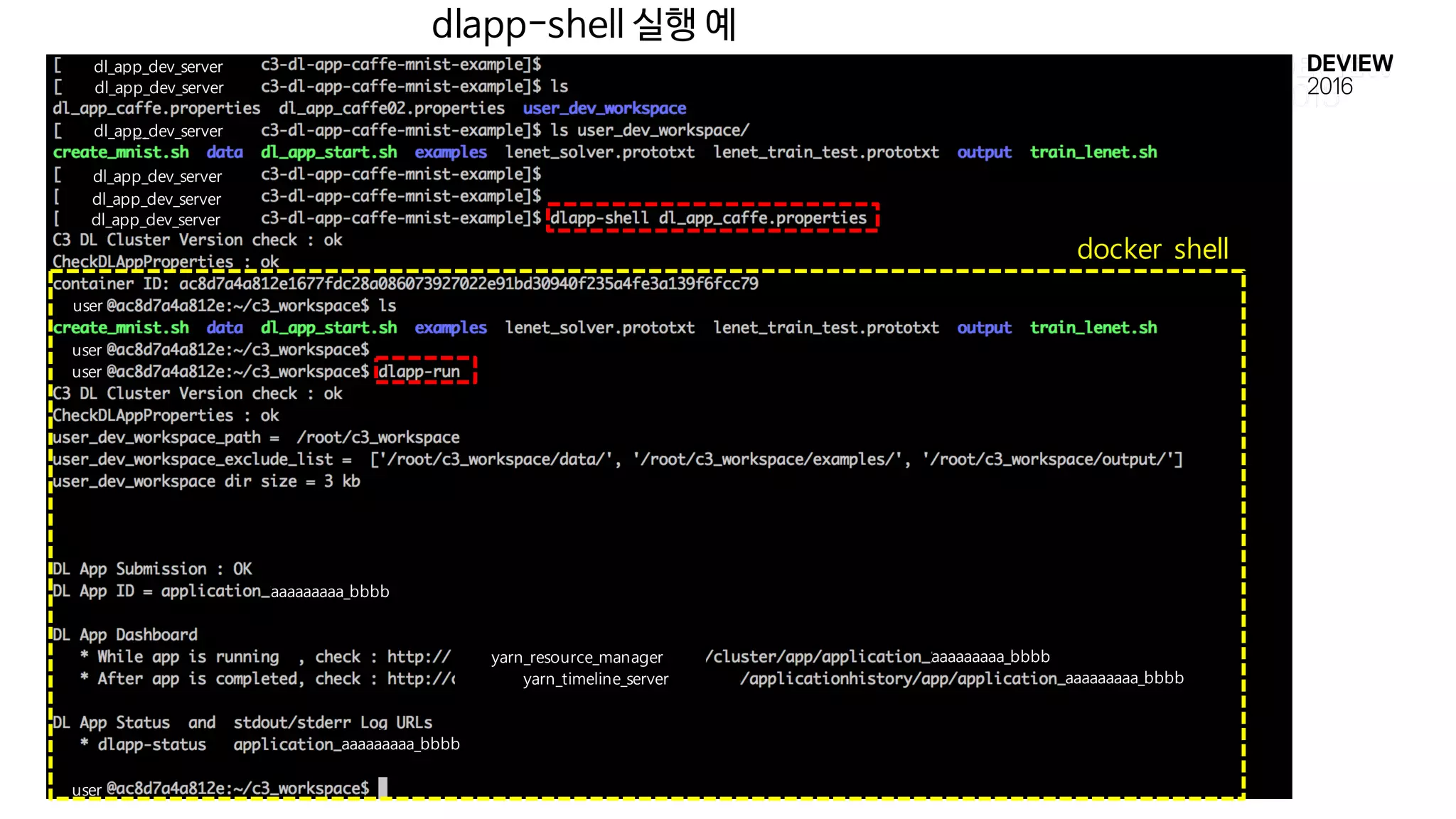
DL App Development환경
• DL App 개발 전용 GPU 서버 구축
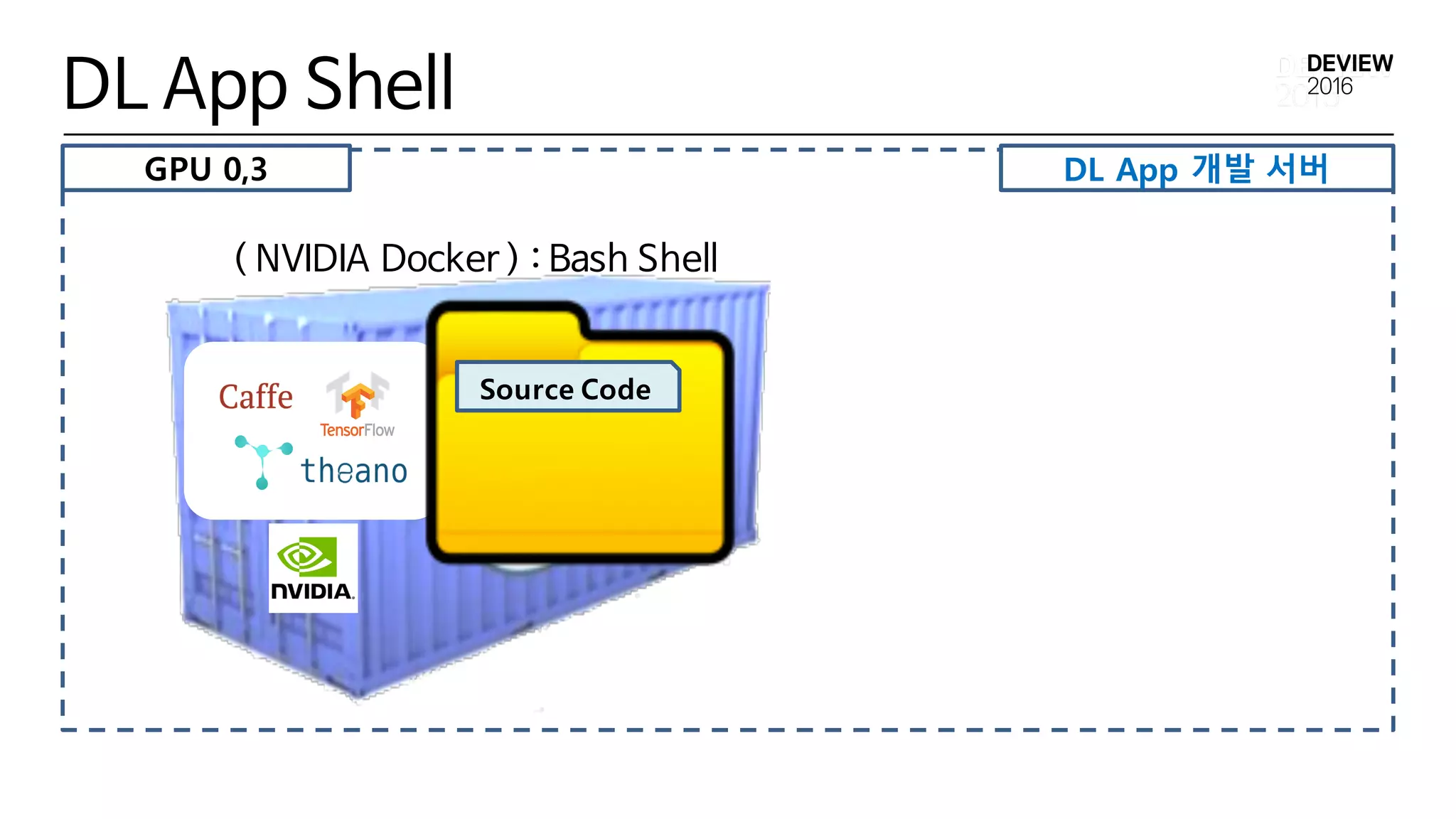
• dlapp-shell
• dlapp-launcher 와 동일한 Docker Image 및 Workspace로 실행되는
docker bash 환경 제공
• dlapp-run : dlapp-shell 환경에서 C3 DL Cluster 에 dl app 을 실행
95.
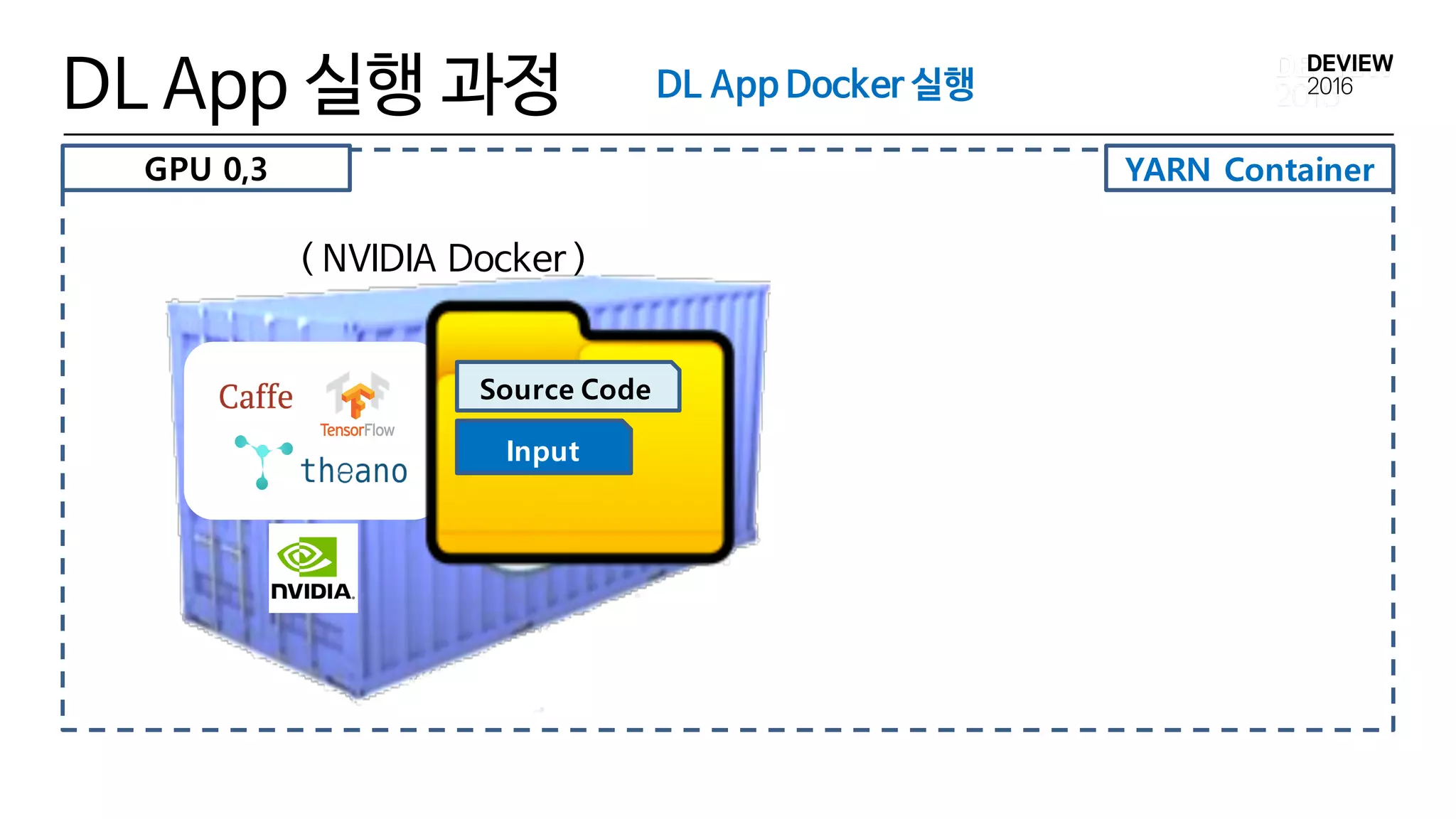
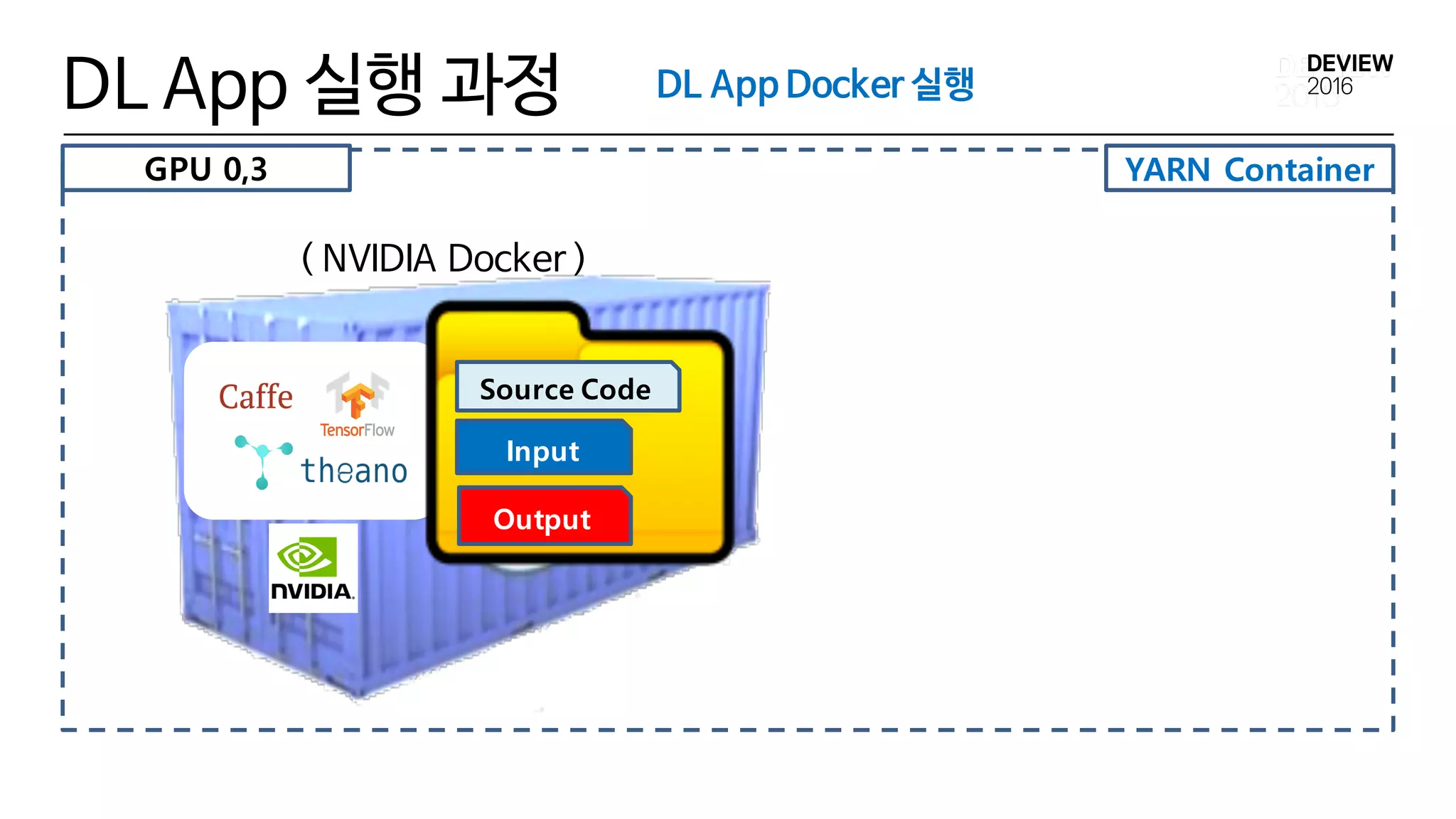
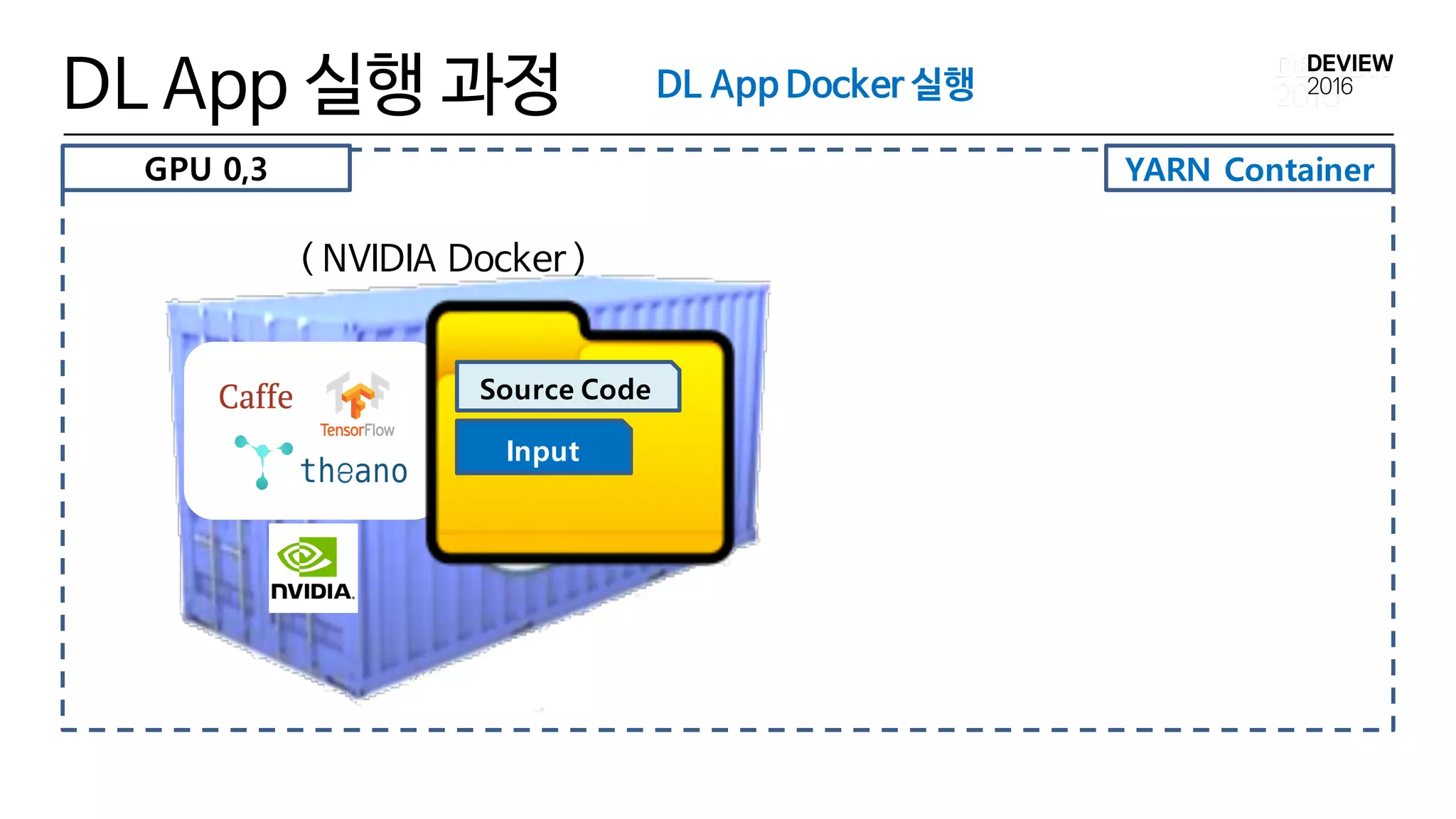
YARN Container
DL App실행 과정
( NVIDIA Docker )
Input
Source Code
DL App Docker 실행
GPU 0,3
• Resource 관리
•GPU 자원 Utilization 증가
• GPU ResourcePlanning ( YARN Queue)
• Administration
• 작업 이력 관리
• 프로젝트 관리
• 사용자 관리
• DevOps
• 규격화된 개발 환경 제공
• 개발 환경 공유
개선점
104.
• 검색 품질향상을 위한 seq2seq 기반의 검색 키워드 변환
• word2vec,CNN 기반의 문서 주제 분류
• CNN 기반의 Image Tagger
• 이외 다수의 프로젝트가 실행중
현재 C3 DL Cluster에서는 …
* CNN : Convolutional Neural Network


















































![• dl_app_caffe.properties
[application]
username=tony
appname='c3 deeplearning app caffe mnist example'
docker_image=naver/c3_dl-caffe
user_dev_workspace_path=./user_dev_workspace
user_shell_script=dl_app_start.sh
user_shell_args='-gpu all'
[from_hdfs]
hdfs=/user/tony/caffe_test/*
input_path=data
[to_hdfs]
output_path=output
hdfs=/user/tony/caffe_mnist_example_output
overwrite=true
• dl_app_start.sh
#!/usr/bin/env bash
./create_mnist.sh
./train_lenet.sh $@
dlapp-launcher 실행 예
.
├── dl_app_caffe.properties
└── user_dev_workspace
├── create_mnist.sh
├── data/
├── dl_app_start.sh
├── examples/
├── lenet_solver.prototxt
├── lenet_train_test.prototxt
├── output/
└── train_lenet.sh](https://image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-83-2048.jpg)
![dlapp-launcher 실행 예
$ dlapp-launcher dl_app_caffe.properties
C3 DL Cluster Version check : ok
CheckDLAppProperties : ok
user_dev_workspace_path = /path/to/user_dev_workspace
user_dev_workspace_exclude_list = []
user_dev_workspace dir size = 4 kb
DL App Submission : OK
DL App ID = application_aaaaaaaaaaa_bbbb
DL App Dashboard
* While app is running , check : http://XXXXXXXXX/cluster/app/application_aaaaaaaaaaa_bbbb
* After app is completed, check : http://XXXXXXXXX/applicationhistory/app/application_aaaaaaaaaaa_bbbb
DL App Status and stdout/stderr Log URLs
* dlapp-status application_aaaaaaaaaaa_bbbb](https://image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-84-2048.jpg)
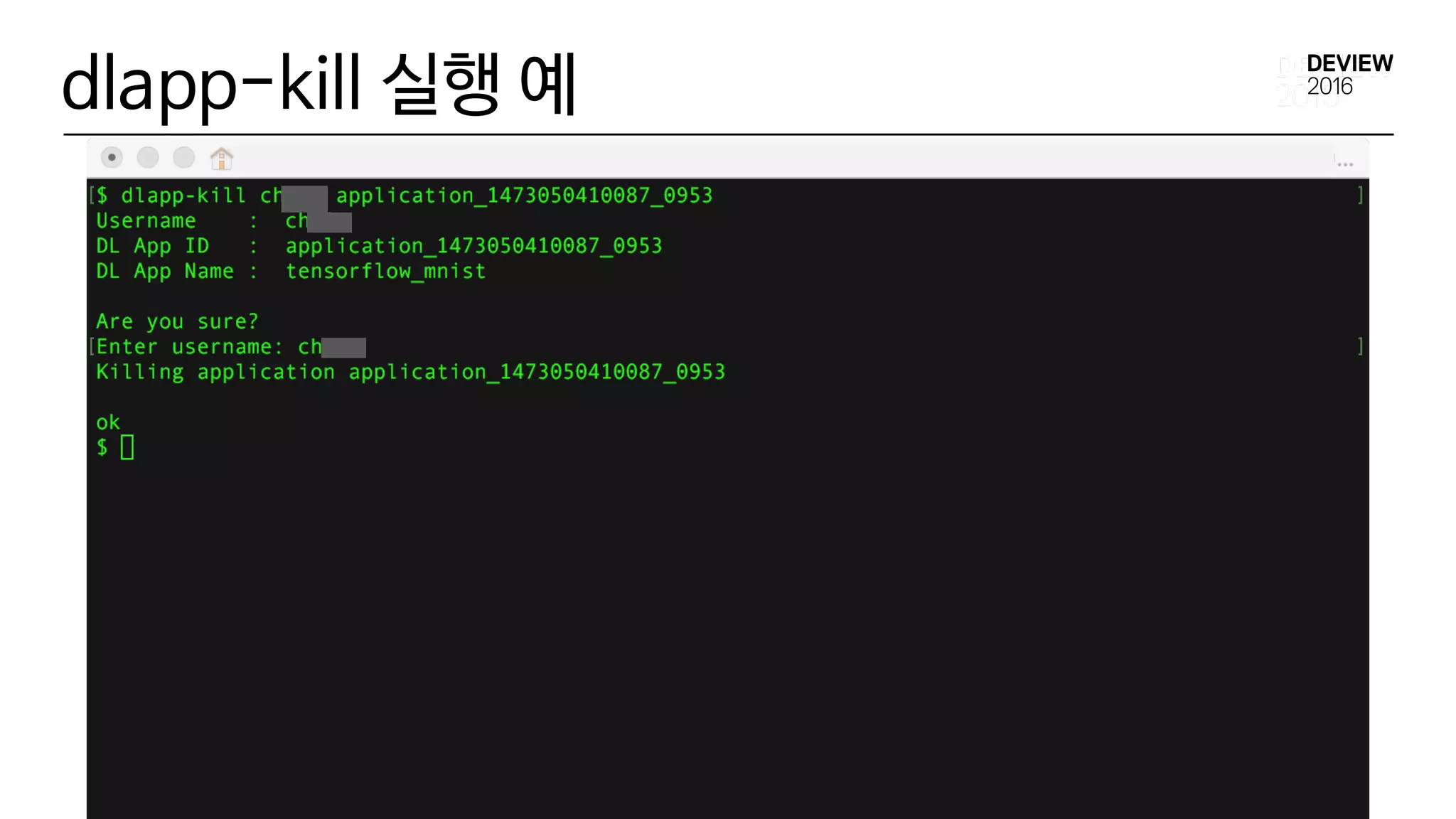
![DL App Tools
• dlapp-status [ DL App ID ]
• dlapp-list [Username]
• dlapp-softkill [Username] [ DL App ID ]
• dlapp-kill [Username] [ DL App ID ]](https://image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-85-2048.jpg)



![DL App Toolset
• dlapp-launcher dl_app.properties
• dlapp-shell dl_app.properties
• dlapp-run
• dlapp-status [DL App ID]
• dlapp-list [Username]
• dlapp-softkill [Username] [DL App ID]
• dlapp-kill [Username] [DL App ID]](https://image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-98-2048.jpg)

























































































![• dl_app_caffe.properties
[application]
username=tony
appname='c3 deeplearning app caffe mnist example'
docker_image=naver/c3_dl-caffe
user_dev_workspace_path=./user_dev_workspace
user_shell_script=dl_app_start.sh
user_shell_args='-gpu all'
[from_hdfs]
hdfs=/user/tony/caffe_test/*
input_path=data
[to_hdfs]
output_path=output
hdfs=/user/tony/caffe_mnist_example_output
overwrite=true
• dl_app_start.sh
#!/usr/bin/env bash
./create_mnist.sh
./train_lenet.sh $@
dlapp-launcher 실행 예
.
├── dl_app_caffe.properties
└── user_dev_workspace
├── create_mnist.sh
├── data/
├── dl_app_start.sh
├── examples/
├── lenet_solver.prototxt
├── lenet_train_test.prototxt
├── output/
└── train_lenet.sh](https://crownmelresort.com/image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-83-2048.jpg)
![dlapp-launcher 실행 예
$ dlapp-launcher dl_app_caffe.properties
C3 DL Cluster Version check : ok
CheckDLAppProperties : ok
user_dev_workspace_path = /path/to/user_dev_workspace
user_dev_workspace_exclude_list = []
user_dev_workspace dir size = 4 kb
DL App Submission : OK
DL App ID = application_aaaaaaaaaaa_bbbb
DL App Dashboard
* While app is running , check : http://XXXXXXXXX/cluster/app/application_aaaaaaaaaaa_bbbb
* After app is completed, check : http://XXXXXXXXX/applicationhistory/app/application_aaaaaaaaaaa_bbbb
DL App Status and stdout/stderr Log URLs
* dlapp-status application_aaaaaaaaaaa_bbbb](https://crownmelresort.com/image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-84-2048.jpg)
![DL App Tools
• dlapp-status [ DL App ID ]
• dlapp-list [Username]
• dlapp-softkill [Username] [ DL App ID ]
• dlapp-kill [Username] [ DL App ID ]](https://crownmelresort.com/image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-85-2048.jpg)












![DL App Toolset
• dlapp-launcher dl_app.properties
• dlapp-shell dl_app.properties
• dlapp-run
• dlapp-status [DL App ID]
• dlapp-list [Username]
• dlapp-softkill [Username] [DL App ID]
• dlapp-kill [Username] [DL App ID]](https://crownmelresort.com/image.slidesharecdn.com/225yarndeeplearningapplicationcluster-161025031031/75/225-yarn-deep-learning-application-cluster-98-2048.jpg)













![[143] Modern C++ 무조건 써야 해?](https://cdn.slidesharecdn.com/ss_thumbnails/143deview2018modernc9-181011024146-thumbnail.jpg?width=640&height=640&fit=bounds)

























![[225]빅데이터를 위한 분산 딥러닝 플랫폼 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/2251016final-171017052307-thumbnail.jpg?width=640&height=640&fit=bounds)




![[AWS Innovate 온라인 컨퍼런스] 수백만 사용자 대상 기계 학습 서비스를 위한 확장 비법 - 윤석찬, AWS 테크 에반젤리스트](https://cdn.slidesharecdn.com/ss_thumbnails/awsinnovateonlineconferenceaimltrack1session1channyyun-200319071657-thumbnail.jpg?width=640&height=640&fit=bounds)


![[OpenInfra Days Korea 2018] Day 2 - E5: GPU on Kubernetes](https://cdn.slidesharecdn.com/ss_thumbnails/e51610gpuonkubernetesv1-180704062436-thumbnail.jpg?width=640&height=640&fit=bounds)




![[E-commerce & Retail Day] 인공지능서비스 활용방안](https://cdn.slidesharecdn.com/ss_thumbnails/random-171027021822-thumbnail.jpg?width=640&height=640&fit=bounds)
![[2017 AWS Startup Day] 스타트업이 인공지능을 만날 때 : 딥러닝 활용사례와 아키텍쳐](https://cdn.slidesharecdn.com/ss_thumbnails/20171102awsstartupday2017-with-171102040932-thumbnail.jpg?width=640&height=640&fit=bounds)

![[233]멀티테넌트하둡클러스터 남경완](https://cdn.slidesharecdn.com/ss_thumbnails/233-161025011544-thumbnail.jpg?width=640&height=640&fit=bounds)



![[211] 인공지능이 인공지능 챗봇을 만든다](https://cdn.slidesharecdn.com/ss_thumbnails/211chatbot-181106094835-thumbnail.jpg?width=640&height=640&fit=bounds)
![[233] 대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing: Maglev Hashing Scheduler i...](https://cdn.slidesharecdn.com/ss_thumbnails/233networkloadbalancing-181018151852-thumbnail.jpg?width=640&height=640&fit=bounds)
![[215] Druid로 쉽고 빠르게 데이터 분석하기](https://cdn.slidesharecdn.com/ss_thumbnails/215druid-181012071910-thumbnail.jpg?width=640&height=640&fit=bounds)
![[245]Papago Internals: 모델분석과 응용기술 개발](https://cdn.slidesharecdn.com/ss_thumbnails/245papagointernals1-181012045005-thumbnail.jpg?width=640&height=640&fit=bounds)
![[236] 스트림 저장소 최적화 이야기: 아파치 드루이드로부터 얻은 교훈](https://cdn.slidesharecdn.com/ss_thumbnails/236deview2018jihoonson-final-181012031726-thumbnail.jpg?width=640&height=640&fit=bounds)
![[235]Wikipedia-scale Q&A](https://cdn.slidesharecdn.com/ss_thumbnails/235deview2018julienperezwikipediaqa12oct2018-181012030613-thumbnail.jpg?width=640&height=640&fit=bounds)
![[244]로봇이 현실 세계에 대해 학습하도록 만들기](https://cdn.slidesharecdn.com/ss_thumbnails/244deview2018tomisilanderrobotsrealworldfinal11oct2018-181012024720-thumbnail.jpg?width=640&height=640&fit=bounds)
![[243] Deep Learning to help student’s Deep Learning](https://cdn.slidesharecdn.com/ss_thumbnails/243deeplearningtohelpstudentsdeeplearning-181012024530-thumbnail.jpg?width=640&height=640&fit=bounds)
![[234]Fast & Accurate Data Annotation Pipeline for AI applications](https://cdn.slidesharecdn.com/ss_thumbnails/234fastaccuratedataannotationpipelineforaiapplications1-181012024230-thumbnail.jpg?width=640&height=640&fit=bounds)
![Old version: [233]대형 컨테이너 클러스터에서의 고가용성 Network Load Balancing](https://cdn.slidesharecdn.com/ss_thumbnails/233largecontainerclusternetworkloadbalancing-181012024225-thumbnail.jpg?width=640&height=640&fit=bounds)
![[226]NAVER 광고 deep click prediction: 모델링부터 서빙까지](https://cdn.slidesharecdn.com/ss_thumbnails/226naveraddeepclickprediction-181012024116-thumbnail.jpg?width=640&height=640&fit=bounds)
![[225]NSML: 머신러닝 플랫폼 서비스하기 & 모델 튜닝 자동화하기](https://cdn.slidesharecdn.com/ss_thumbnails/225nsmlmachinelearningntuningautomize-181012023407-thumbnail.jpg?width=640&height=640&fit=bounds)
![[224]네이버 검색과 개인화](https://cdn.slidesharecdn.com/ss_thumbnails/224naversearchnpersonalizationfinal-181012022631-thumbnail.jpg?width=640&height=640&fit=bounds)
![[216]Search Reliability Engineering (부제: 지진에도 흔들리지 않는 네이버 검색시스템)](https://cdn.slidesharecdn.com/ss_thumbnails/216sresearchreliabilityengineering-181012022623-thumbnail.jpg?width=640&height=640&fit=bounds)
![[214] Ai Serving Platform: 하루 수 억 건의 인퍼런스를 처리하기 위한 고군분투기](https://cdn.slidesharecdn.com/ss_thumbnails/214aiservingplatforminference-181012022603-thumbnail.jpg?width=640&height=640&fit=bounds)
![[213] Fashion Visual Search](https://cdn.slidesharecdn.com/ss_thumbnails/213fashionvisualsearchreduced-181012022540-thumbnail.jpg?width=640&height=640&fit=bounds)
![[232] TensorRT를 활용한 딥러닝 Inference 최적화](https://cdn.slidesharecdn.com/ss_thumbnails/232dlinferenceoptimizationusingtensorrt1-181012014455-thumbnail.jpg?width=640&height=640&fit=bounds)
![[242]컴퓨터 비전을 이용한 실내 지도 자동 업데이트 방법: 딥러닝을 통한 POI 변화 탐지](https://cdn.slidesharecdn.com/ss_thumbnails/242pcdpublic-181012011734-thumbnail.jpg?width=640&height=640&fit=bounds)
![[212]C3, 데이터 처리에서 서빙까지 가능한 하둡 클러스터](https://cdn.slidesharecdn.com/ss_thumbnails/212c3-181012011644-thumbnail.jpg?width=640&height=640&fit=bounds)
![[223]기계독해 QA: 검색인가, NLP인가?](https://cdn.slidesharecdn.com/ss_thumbnails/2232018-181012010149-thumbnail.jpg?width=640&height=640&fit=bounds)