Download to read offline



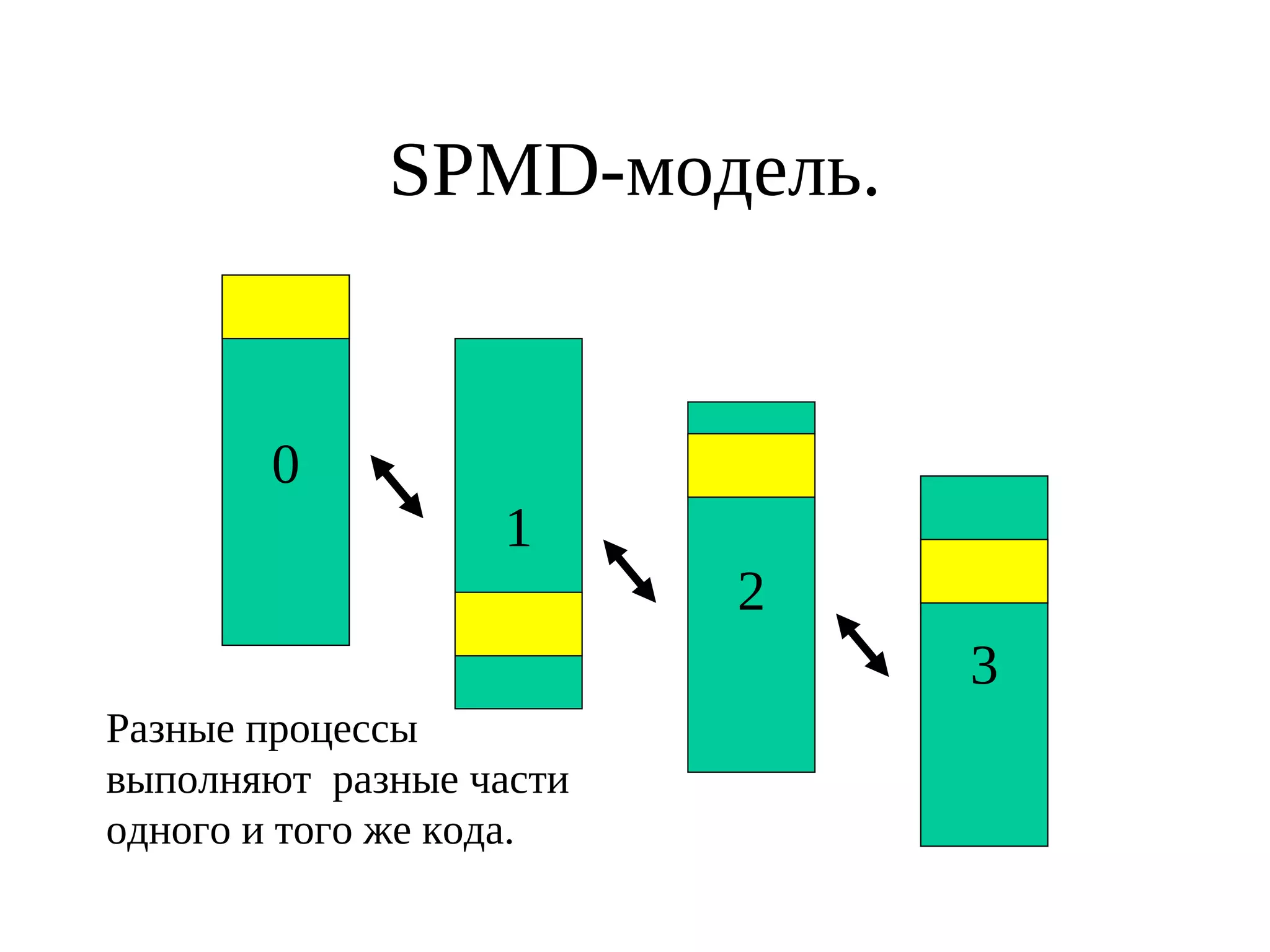


![Тоже простая MPI-программа
#include <mpi.h>
#include <stdio.h>
int main( int argc, char *argv[] )
{
int rank, size;
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
printf( "I am %d of %dn", rank, size );
MPI_Finalize();
return 0;
}](https://image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-7-2048.jpg)

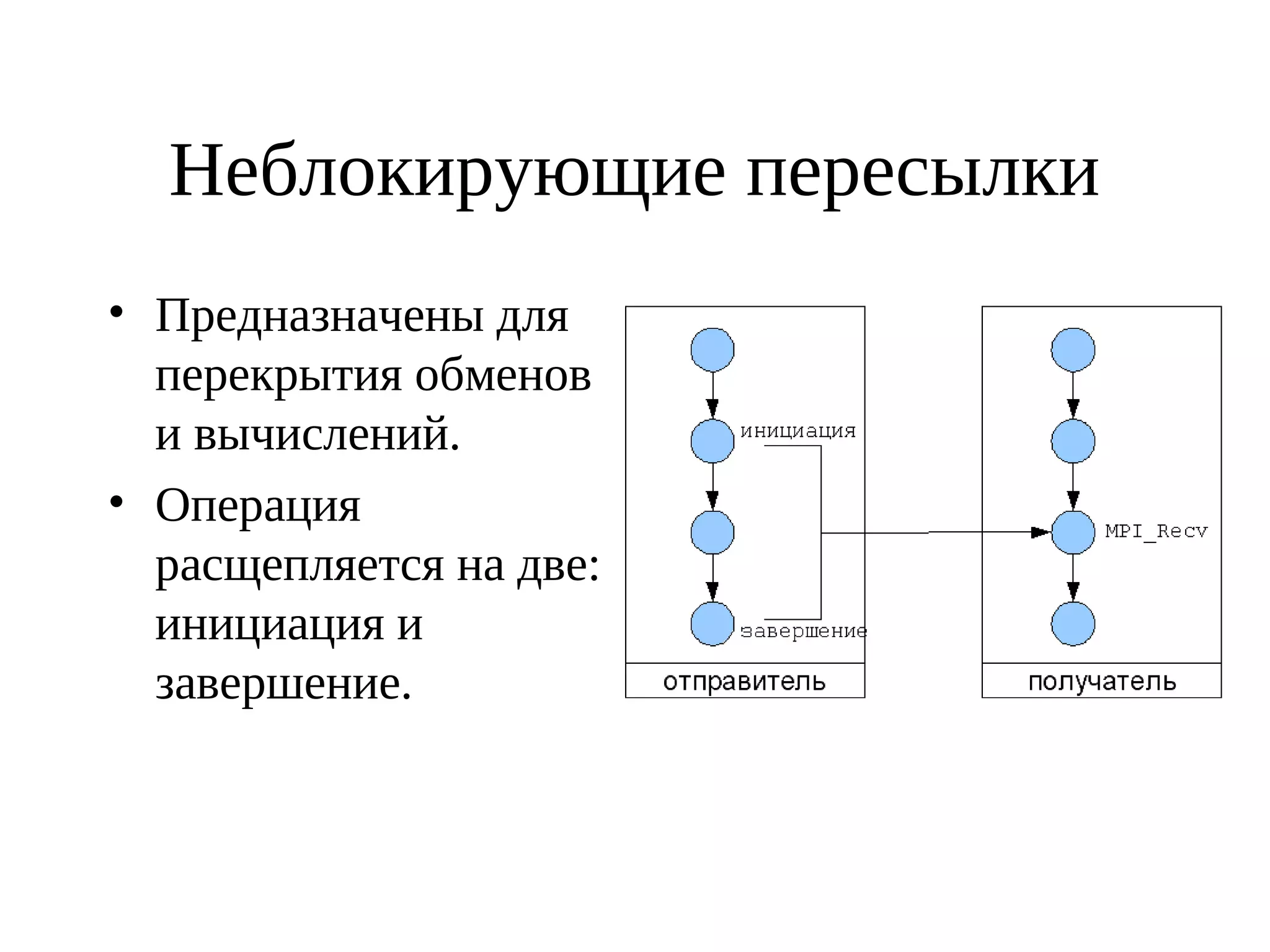
![Пример простейшей пересылки
#include <stdio.h>
#include <mpi.h>
main(int argc, char* argv[])
{
int rank;
MPI_Status st;
char buf[64];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) {
sprintf(buf, "Hello from processor 0");
MPI_Send(buf, 64, MPI_CHAR, 1, 0, MPI_COMM_WORLD);
} else {
MPI_Recv(buf, 64, MPI_CHAR, 0, 0, MPI_COMM_WORLD, &st);
printf("Process %d received %s n", rank, buf);
}
MPI_Finalize();
}](https://image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-9-2048.jpg)






![Завершение:
int MPI_Wait (MPI_Request * request, MPI_Status * status)
int MPI_Test(MPI_Request *request, int *flag,
MPI_Status *status)
int MPI_Waitall(int count, MPI_Request array_of_requests[],
MPI_Status array_of_statuses[] )
int MPI_Waitany(int count, MPI_Request array_of_requests[],
int* index, MPI_Status *status )](https://image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-17-2048.jpg)

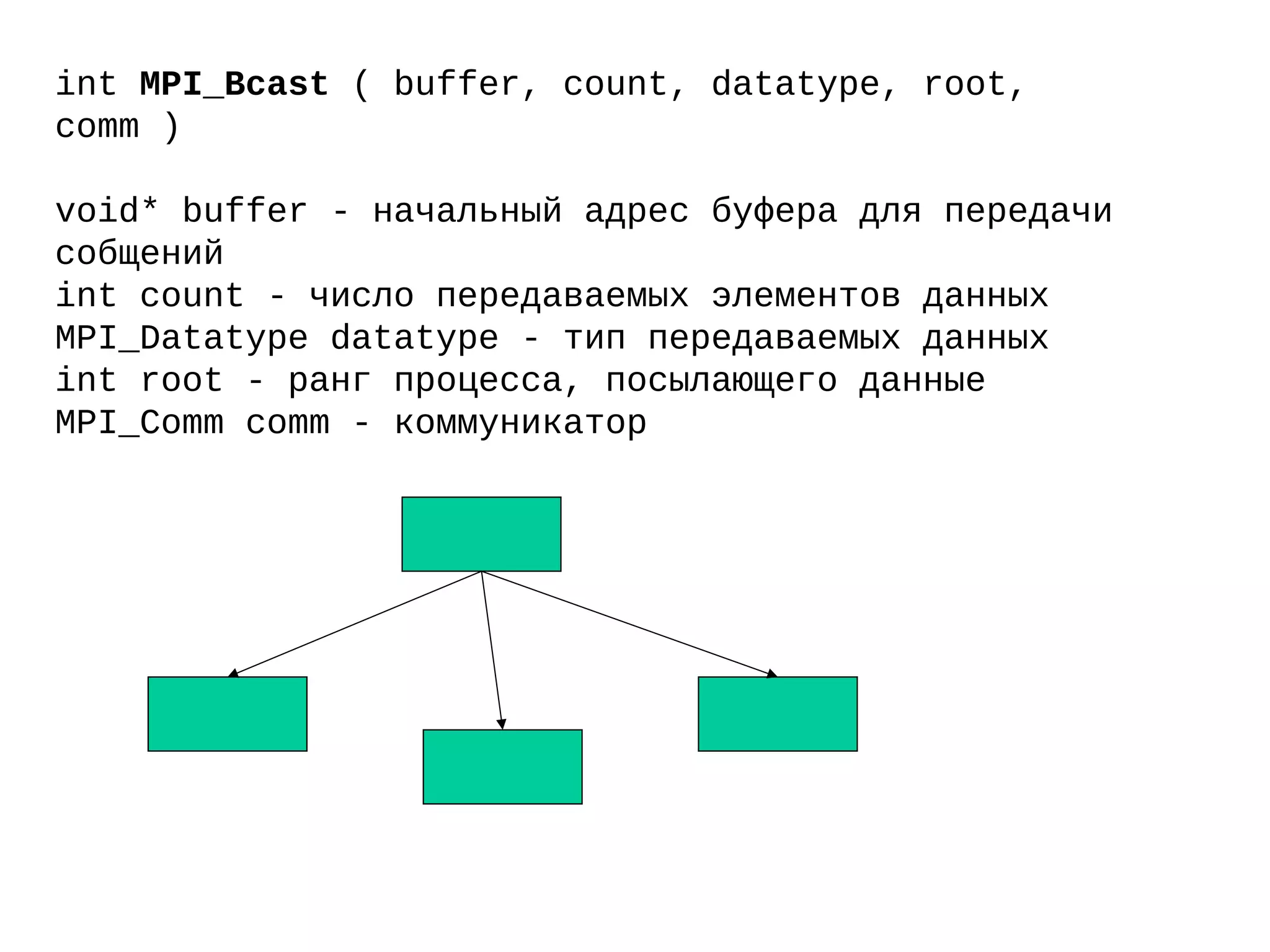
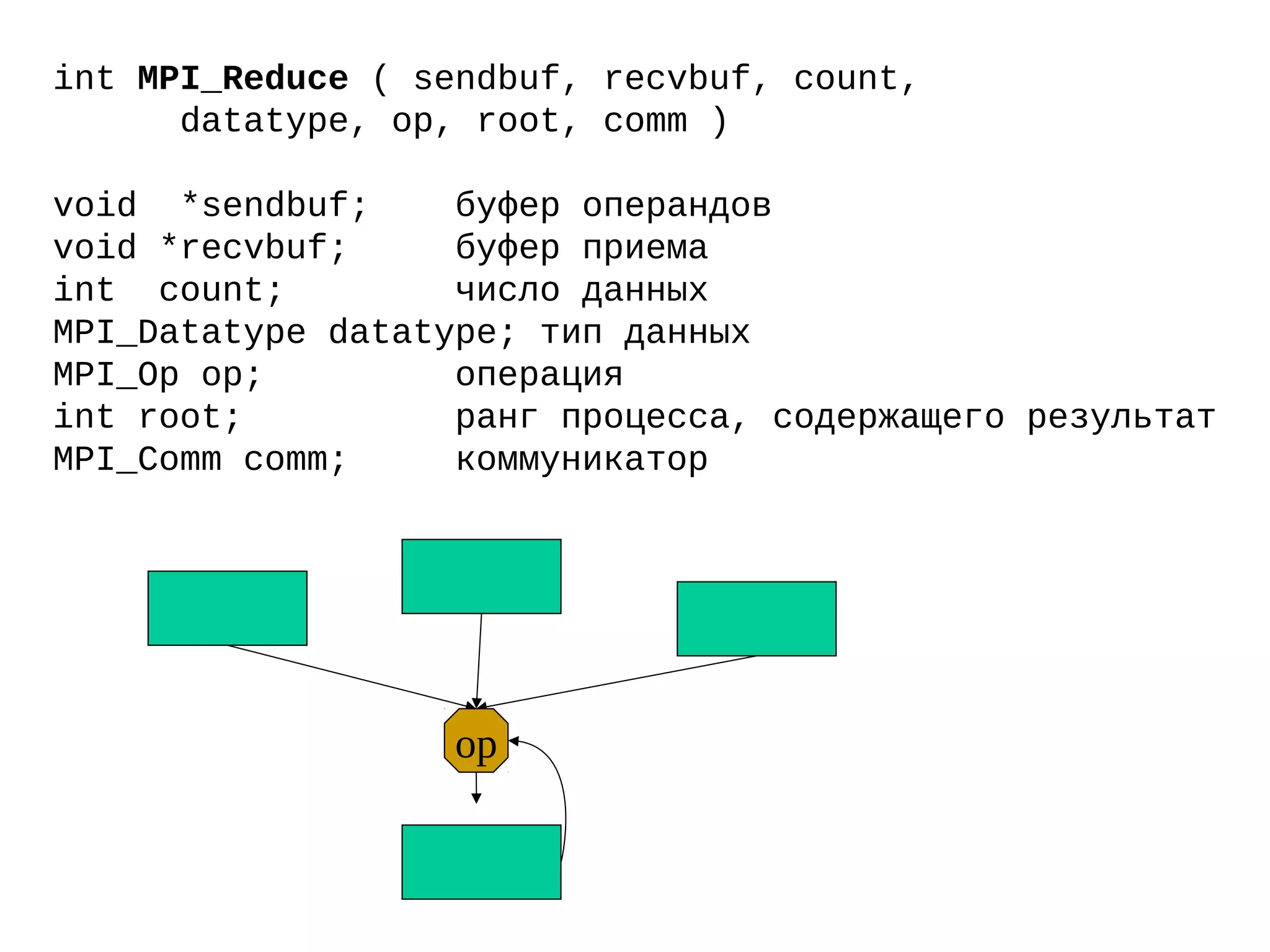

![Вычисление числа Pi
#include "mpi.h"
#include <math.h>
int main(argc,argv)
int argc;
char *argv[];
{
int n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x, a;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);](https://image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-22-2048.jpg)

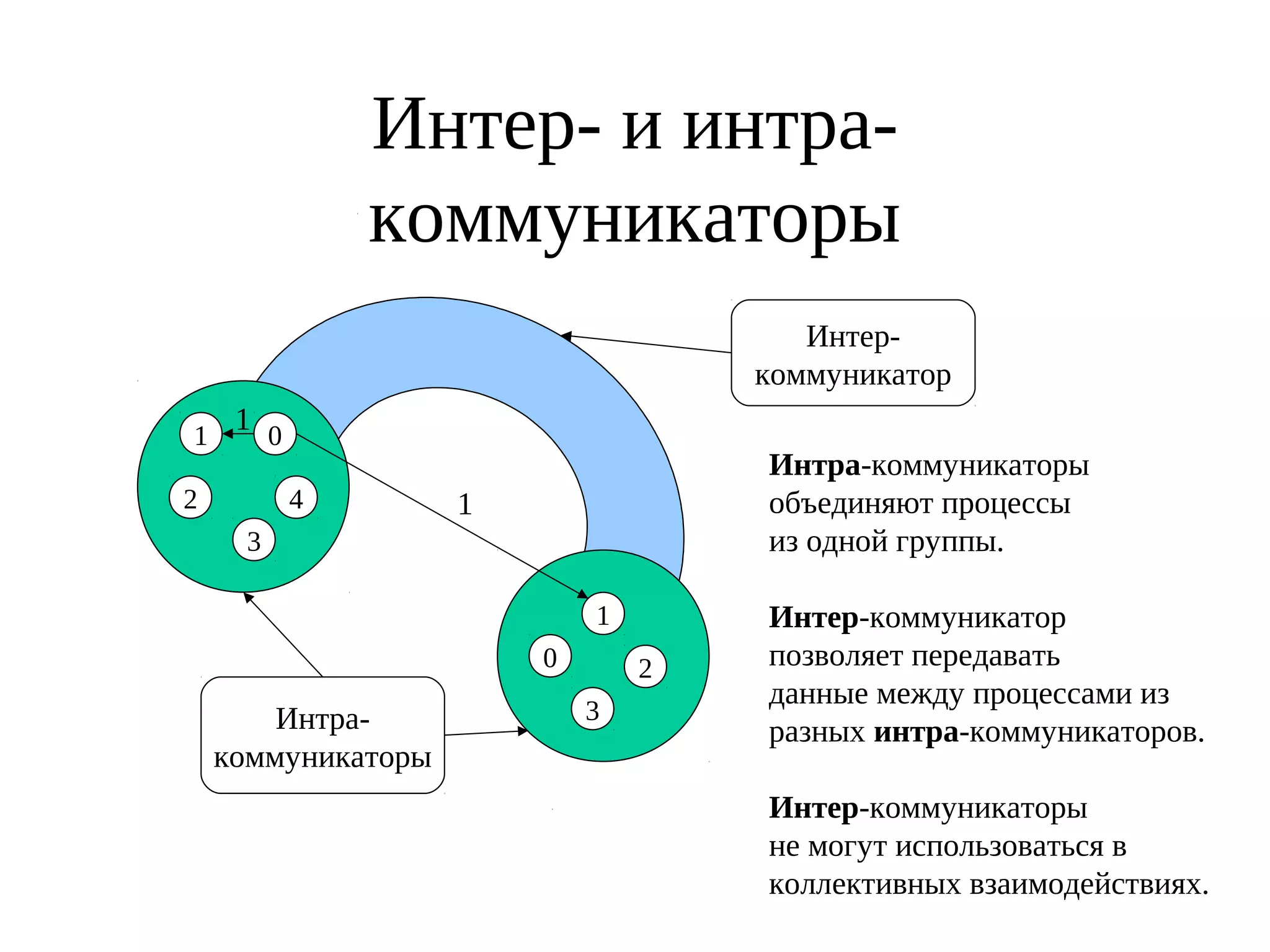



![Переупорядочивание (с возможным удалением) процессов
в существующей группе:
int MPI_Group_incl(MPI_Group* group, int n, int*
ranks, MPI_Group* newgroup)
group – исходная группа;
n – число элементов в массиве ranks;
ranks – массив номеров процессов, из которых
будет создана новая группа;
newgroup – указатель на область для сохранения
результата операции;
Созданная группа newgroup содержит элементы группы
group, перечисленные в массиве ranks: i-й процесс
создаваемой группы newgroup совпадает с процессом,
имеющим номер ranks[i] в группе group.](https://image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-28-2048.jpg)











![Тоже простая MPI-программа
#include <mpi.h>
#include <stdio.h>
int main( int argc, char *argv[] )
{
int rank, size;
MPI_Init( &argc, &argv );
MPI_Comm_rank( MPI_COMM_WORLD, &rank );
MPI_Comm_size( MPI_COMM_WORLD, &size );
printf( "I am %d of %dn", rank, size );
MPI_Finalize();
return 0;
}](https://crownmelresort.com/image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-7-2048.jpg)

![Пример простейшей пересылки
#include <stdio.h>
#include <mpi.h>
main(int argc, char* argv[])
{
int rank;
MPI_Status st;
char buf[64];
MPI_Init(&argc, &argv);
MPI_Comm_rank(MPI_COMM_WORLD, &rank);
if(rank == 0) {
sprintf(buf, "Hello from processor 0");
MPI_Send(buf, 64, MPI_CHAR, 1, 0, MPI_COMM_WORLD);
} else {
MPI_Recv(buf, 64, MPI_CHAR, 0, 0, MPI_COMM_WORLD, &st);
printf("Process %d received %s n", rank, buf);
}
MPI_Finalize();
}](https://crownmelresort.com/image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-9-2048.jpg)







![Завершение:
int MPI_Wait (MPI_Request * request, MPI_Status * status)
int MPI_Test(MPI_Request *request, int *flag,
MPI_Status *status)
int MPI_Waitall(int count, MPI_Request array_of_requests[],
MPI_Status array_of_statuses[] )
int MPI_Waitany(int count, MPI_Request array_of_requests[],
int* index, MPI_Status *status )](https://crownmelresort.com/image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-17-2048.jpg)




![Вычисление числа Pi
#include "mpi.h"
#include <math.h>
int main(argc,argv)
int argc;
char *argv[];
{
int n, myid, numprocs, i;
double PI25DT = 3.141592653589793238462643;
double mypi, pi, h, sum, x, a;
MPI_Init(&argc,&argv);
MPI_Comm_size(MPI_COMM_WORLD,&numprocs);
MPI_Comm_rank(MPI_COMM_WORLD,&myid);](https://crownmelresort.com/image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-22-2048.jpg)





![Переупорядочивание (с возможным удалением) процессов
в существующей группе:
int MPI_Group_incl(MPI_Group* group, int n, int*
ranks, MPI_Group* newgroup)
group – исходная группа;
n – число элементов в массиве ranks;
ranks – массив номеров процессов, из которых
будет создана новая группа;
newgroup – указатель на область для сохранения
результата операции;
Созданная группа newgroup содержит элементы группы
group, перечисленные в массиве ranks: i-й процесс
создаваемой группы newgroup совпадает с процессом,
имеющим номер ranks[i] в группе group.](https://crownmelresort.com/image.slidesharecdn.com/20140420parallelprogrammingkalishenkolecture10-140421054423-phpapp02/75/20140420-parallel-programming_kalishenko_lecture10-28-2048.jpg)












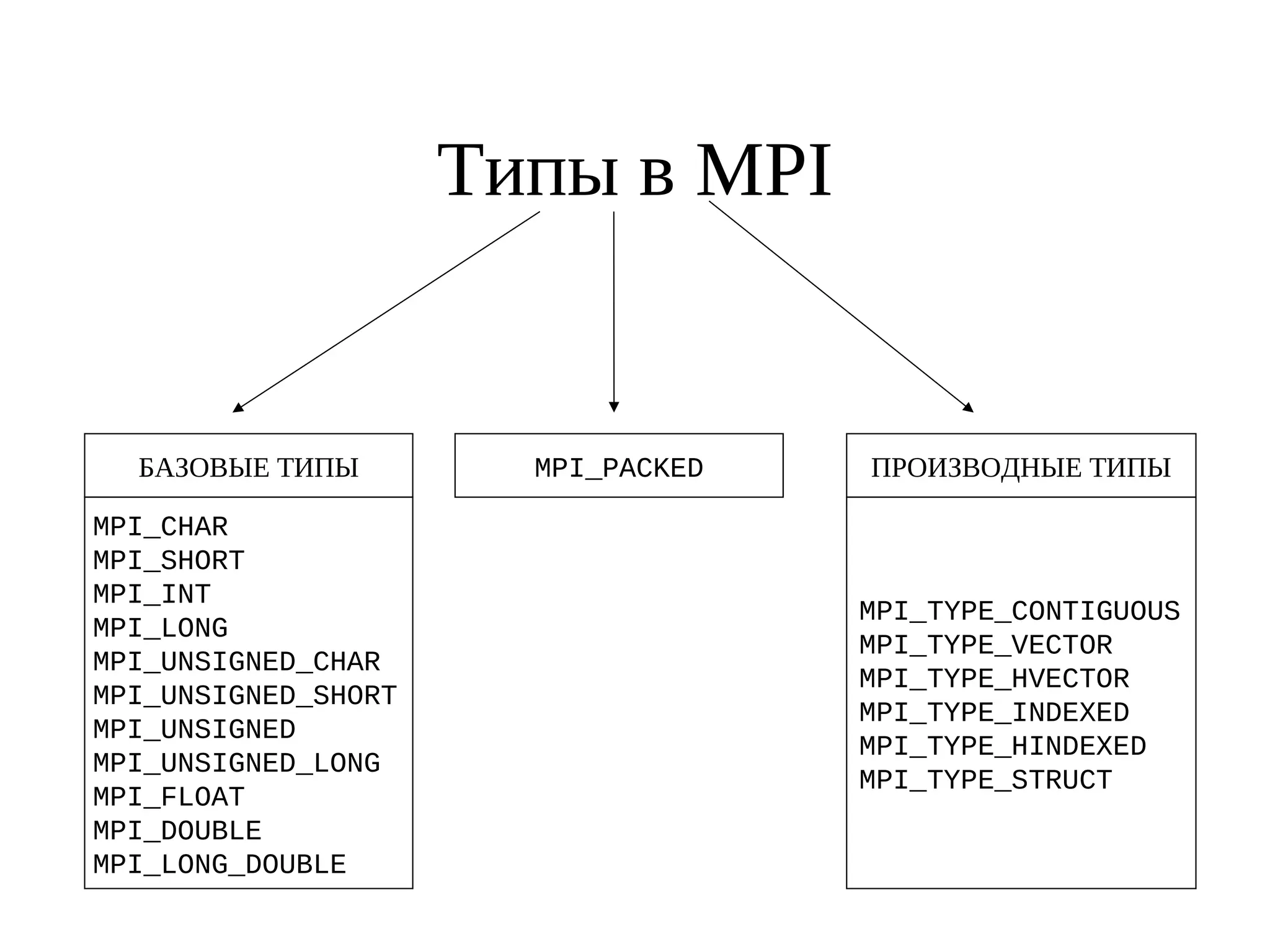
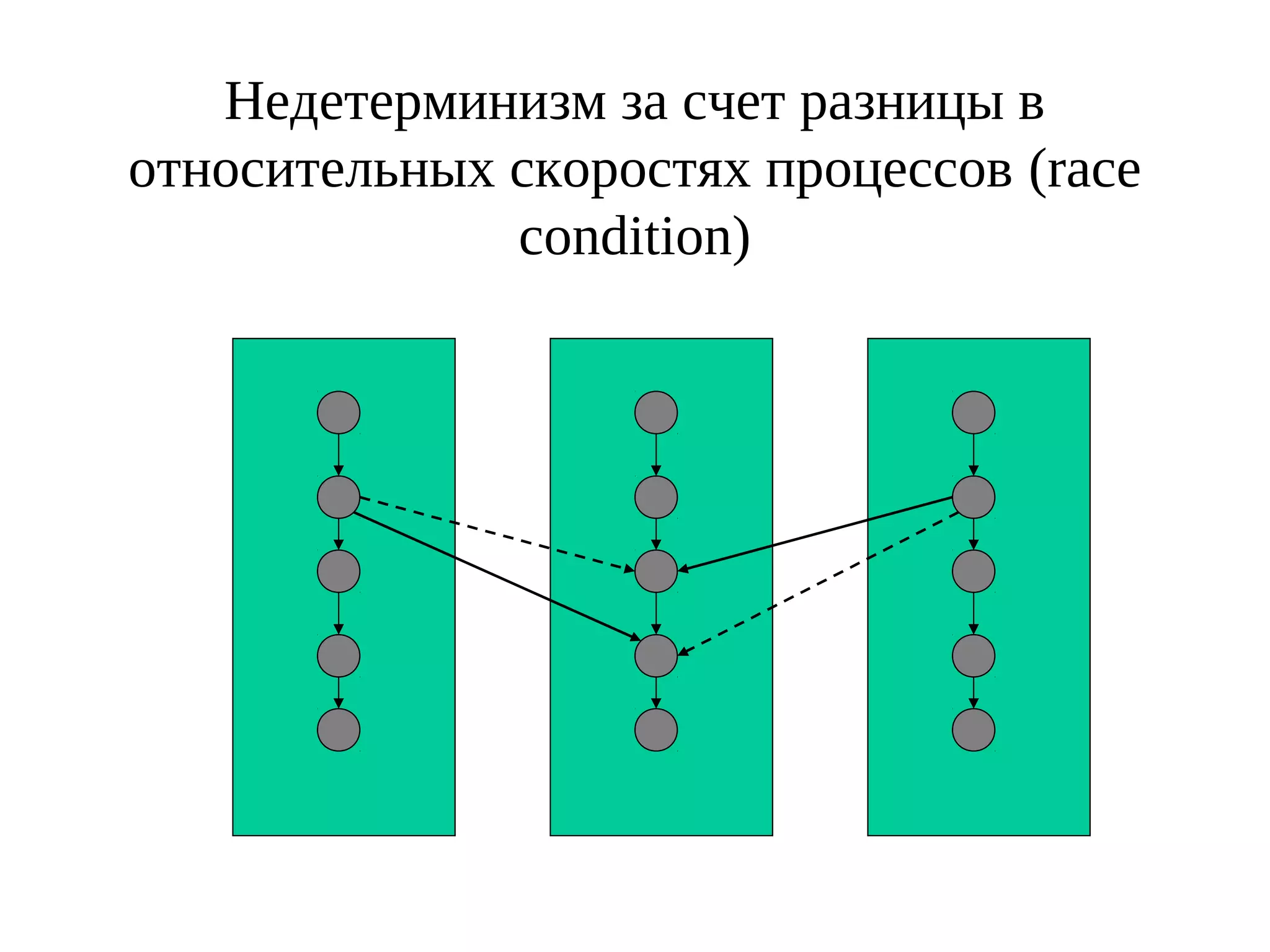
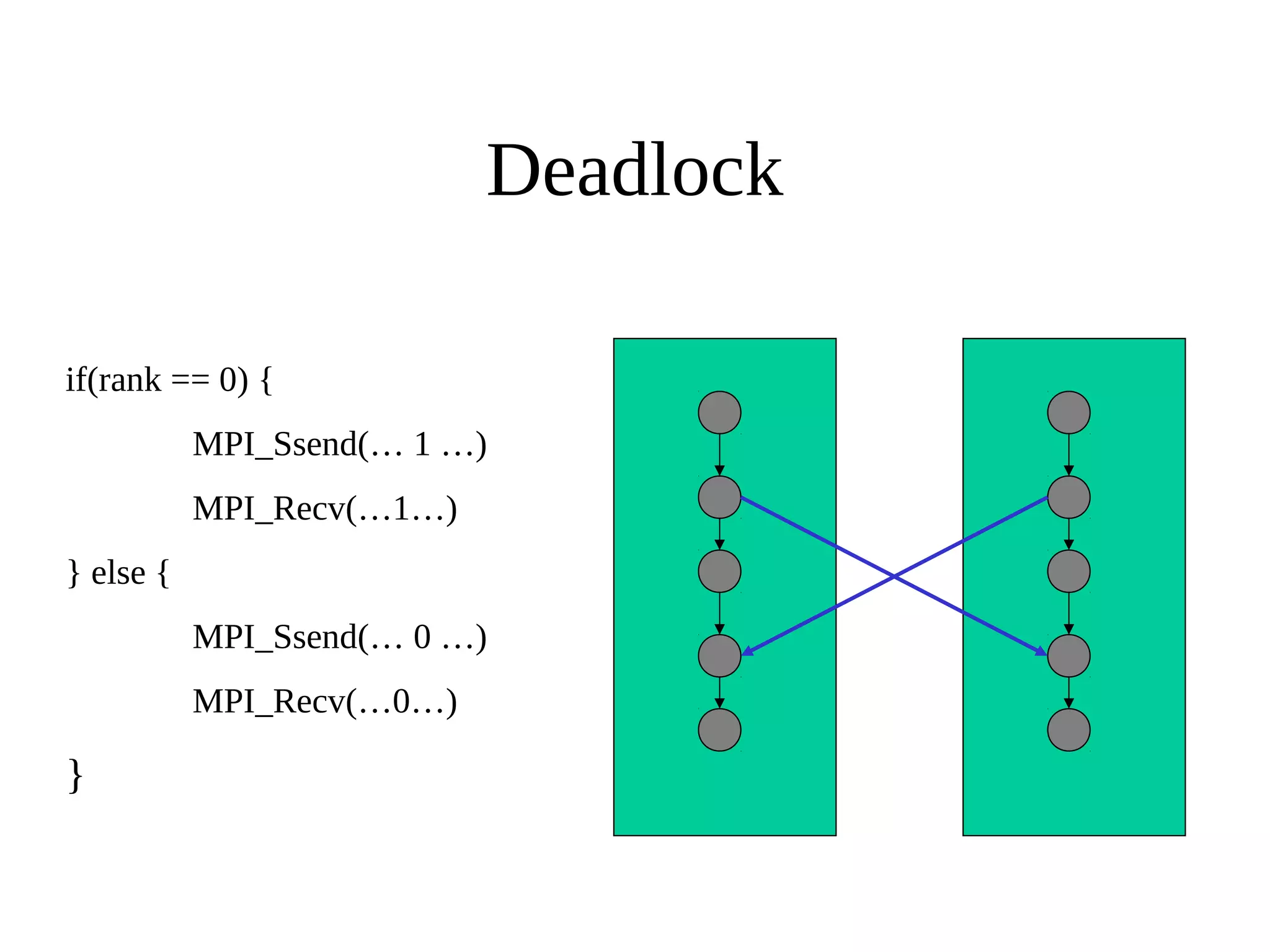
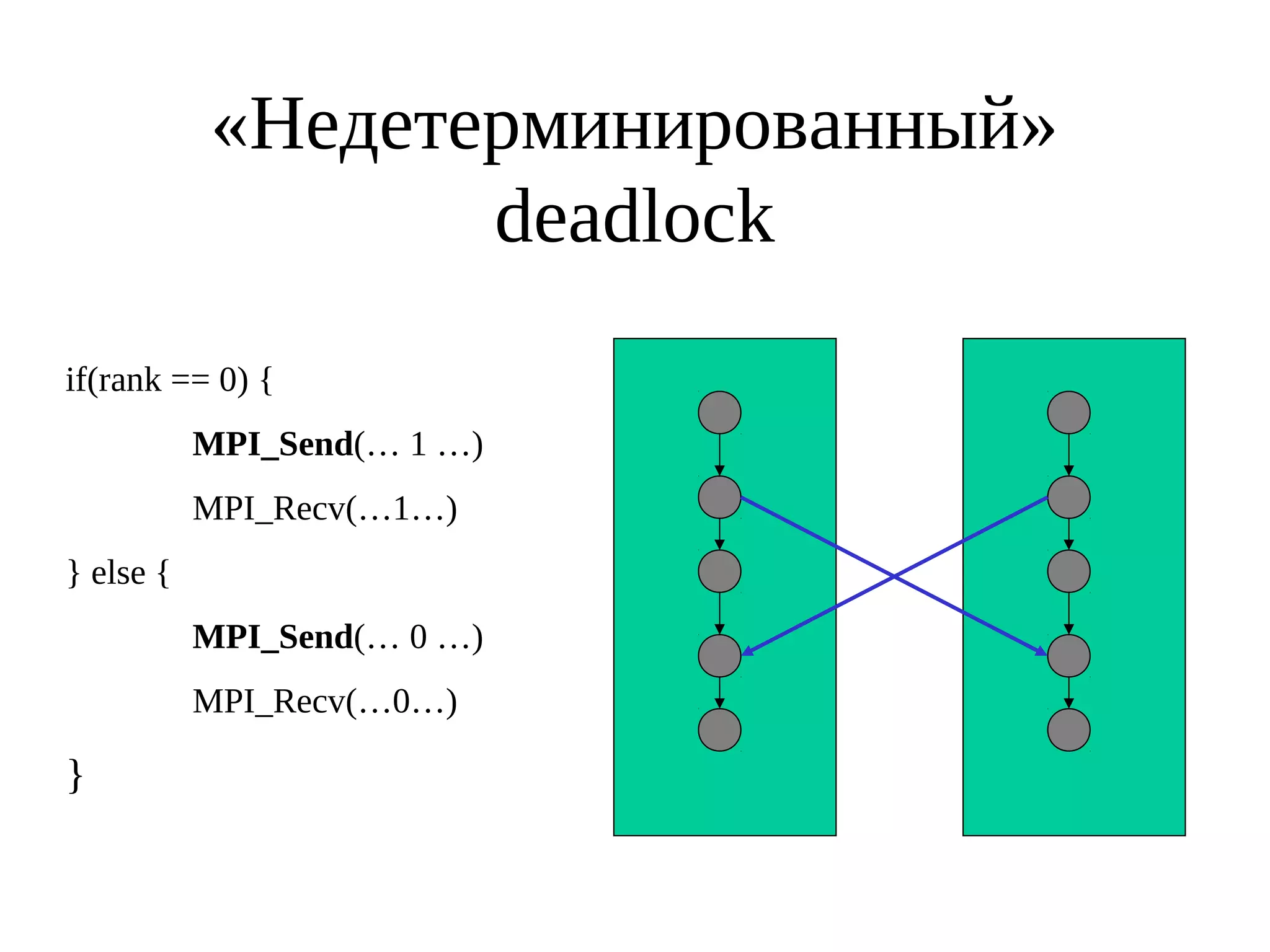
Документ описывает библиотеку MPI (Message Passing Interface) и её стандарты, начиная с версии 1.0 в 1995 году до версии 2.0 в 1998 году. Включены основные функции и примеры программ на C для инициализации, отправки и получения сообщений, а также коллективных операций между процессами. Рассматриваются также ошибки, которые могут возникнуть в MPI-программах, такие как взаимные блокировки и недетерминизм.
























































